Hacking Academia: Data Science and the University by Jake Vanderplas
From the post:
…
In the words of Alex Szalay, these sorts of researchers must be “Pi-shaped” as opposed to the more traditional “T-shaped” researcher. In Szalay’s view, a classic PhD program generates T-shaped researchers: scientists with wide-but-shallow general knowledge, but deep skill and expertise in one particular area. The new breed of scientific researchers, the data scientists, must be Pi-shaped: that is, they maintain the same wide breadth, but push deeper both in their own subject area and in the statistical or computational methods that help drive modern research:
Perhaps neither of these labels or descriptions is quite right. Another school of thought on data science is Jim Gray’s idea of the “Fourth Paradigm” of scientific discovery: First came the observational insights of empirical science; second were the mathematically-driven insights of theoretical science; third were the simulation-driven insights of computational science. The fourth paradigm involves primarily data-driven insights of modern scientific research. Perhaps just as the scientific method morphed and grew through each of the previous paradigmatic transitions, so should the scientific method across all disciplines be modified again for this new data-driven realm of knowledge.
…
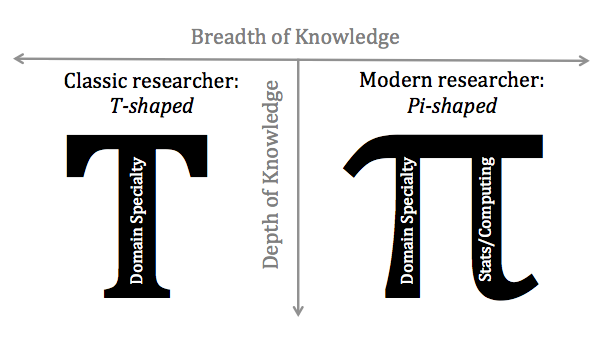
Neither one of the labels in the graphic are correct. In part because this a classic light versus dark dualism, along the lines of Middle Age scholars making reference to the dark ages. You could not have asked anyone living between the 6th and 13th centuries, what it felt like to live in the “dark ages.” That was a name later invented to distinguish the “dark ages,” an invention that came about in the “Middle Ages.” The “Middle Ages” being coined, of course, during the Renaissance.
Every age thinks it is superior to those that came before and the same is true for changes in the humanities and sciences. Fear not, someday your descendants will wonder how we fed ourselves, being hobbled with such vastly inferior software and hardware.
I mention this because the “Pi-shaped” graphic is making the rounds on Twitter. It is only one of any number of new “distinctions” that are springing up in academia and elsewhere. None of which will be of interest or perhaps even intelligible in another twenty years.
Rather than focusing on creating ephemeral labels for ourselves and others, how about we focus on research and results, whatever label has been attached to someone? Yes?