Big Data, or Not Big Data: What is <your> question? by Pradyumna S. Upadrashta.
From the post:
Before jumping on the Big Data bandwagon, I think it is important to ask the question of whether the problem you have requires much data. That is, I think its important to determine when Big Data is relevant to the problem at hand.
The question of relevancy is important, for two reasons: (i) if the data are irrelevant, you can’t draw appropriate conclusions (collecting more of the wrong data leads absolutely nowhere), (ii) the mismatch between the problem statement, the underlying process of interest, and the data in question is critical to understand if you are going to distill any great truths from your data.
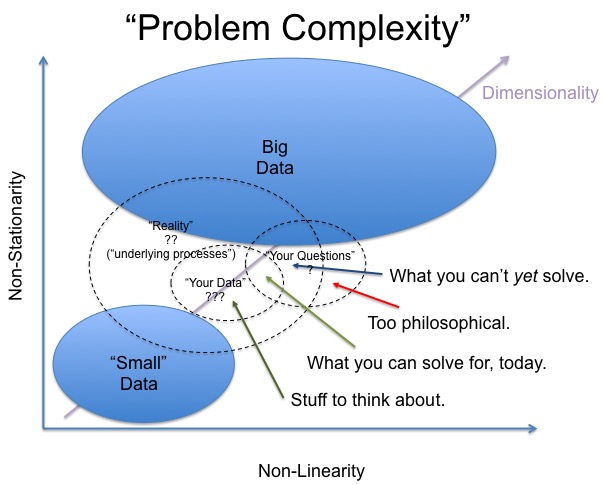
Big Data is relevant when you see some evidence of a non-linear or non-stationary generative process that varies with time (or at least, collection time), on the spectrum of random drift to full blown chaotic behavior. Non-stationary behaviors can arise from complex (often ‘hidden’) interactions within the underlying process generating your observable data. If you observe non-linear relationships, with underlying stationarity, it reduces to a sampling problem. Big Data implicitly becomes relevant when we are dealing with processes embedded in a high dimensional context (i.e., after dimension reduction). For high embedding dimensions, we need more and more well distributed samples to understand the underlying process. For problems where the underlying process is both linear and stationary, we don’t necessarily need much data
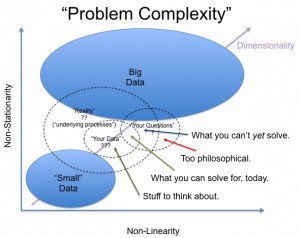
…
Great post and a graphic that is worthy of being turned into a poster! (Pradyumna asks for suggestions on the graphic so you may want to wait a few days to see if it improves. Plus send suggestions if you have them.)
What is <your> question? wasn’t the starting point for: Dell: Big opportunities missed as Big Data remains big business.
The barriers to big data:
While big data has proven marketing benefits, infrastructure costs (35 per cent) and security (35 per cent) tend to be the primary obstacles for implementing big data initiatives.
Delving deeper, respondents believe analytics/operational costs (34 per cent), lack of management support (22 per cent) and lack of technical skills (21 per cent) are additional barriers in big data strategies.
“So where do the troubles with big data stem from?” asks Jones, citing cost (e.g. price of talent, storage, etc.), security concerns, uncertainty in how to leverage data and a lack of in-house expertise.
“In fact, only 36 percent of organisations globally have in-house big data expertise. Yet, the proven benefits of big data analytics should justify the investment – businesses just have to get started.
Do you see What is <your> question? being answered anywhere?
I didn’t, yet the drum beat for big data continues.
I fully agree that big data techniques and big data are important advances and they should be widely adopted and used, but only when they are appropriate to the question at hand.
Otherwise you will be like a non-profit I know that spent upward of $500,000+ on a CMS system that was fundamentally incompatible with their data. Wasn’t designed for document management. Fine system but not appropriate for the task at hand. It was like a sleeping dog in the middle of the office. No matter what you wanted to do, it was hard to avoid the dog.
Certainly could not admit that the purchasing decision was a mistake because those in charge would lose face.
Don’t find yourself in a similar situation with big data.
Unless and until someone produces an intelligible business plan that identifies the data, the proposed analysis of the data and the benefits of the results, along with cost estimates, etc., keep a big distance from big data. Make business ROI based decisions, not cult ones.
I first saw this in a tweet by Kirk Borne.