G8 countries must work harder to open up essential data by Rufus Pollock.
From the post:
Open data and transparency will be one of the three main topics at the G8 Summit in Northern Ireland next week. Today transparency campaigners released preview results from the global Open Data Census showing that G8 countries still have a long way to go in releasing essential information as open data.
The Open Data Census is run by the Open Knowledge Foundation, with the help of a network of local data experts around the globe. It measures the openness of data in ten key areas including those essential for transparency and accountability (such as election results and government spending data), and those vital for providing critical services to citizens (such as maps and transport timetables). Full results for the 2013 Open Data Census will be released later this year.
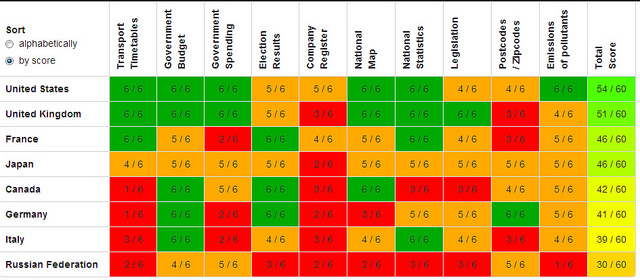
The preview results show that while both the UK and the US (who top the table of G8 countries) have made significant progress towards opening up key datasets, both countries still have work to do. Postcode data, which is required for almost all location-based applications and services, remains a major issue for all G8 countries except Germany. No G8 country scored the top mark for company registry data. Russia is the only G8 country not to have published any of the information included in the census as open data. The full results for G8 countries are online at: http://census.okfn.org/g8/
Apologies for the graphic, it is too small to read. See the original post for a more legible version.
The U.S. came in first with a score of 54 out of a possible 60.
I assume this evaluation was done prior the the revelation of the NSA data snooping?
The U.S. government has massive collections of data that not only isn’t visible, its existence is denied.
How is that for government transparency?
The most disappointing part is that other major players, China, Russia, you take your pick, has largely the small secret data as the United States. Probably not full sets of the day to day memos but the data that really counts, they all have.
So, who is it they are keeping information from?
Ah, that would be their citizens.
Who might not approve of their privileges, goals, tactics, and favoritism.
For example, despite the U.S. government’s disapproval/criticism of many other countries (or rather their governments), I can’t think of any reason for me to dislike unknown citizens of another country.
Whatever goals the U.S. government is pursuing in disadvantaging citizens of another country, it’s not on my behalf.
If the public knew who was benefiting from U.S. policy, perhaps new officials would change those policies.
But that isn’t the goal of the specter of government transparency that the United States leads.