Skimming through my Twitter stream I encountered:
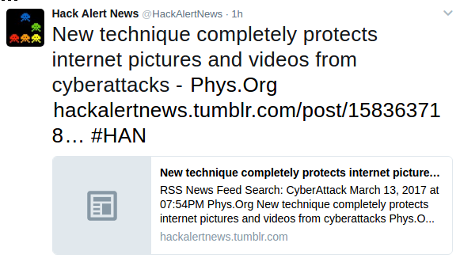
That sounds important and it’s from Phys.org.
Who describe themselves in 100 words:
Phys.org™ (formerly Physorg.com) is a leading web-based science, research and technology news service which covers a full range of topics. These include physics, earth science, medicine, nanotechnology, electronics, space, biology, chemistry, computer sciences, engineering, mathematics and other sciences and technologies. Launched in 2004, Phys.org’s readership has grown steadily to include 1.75 million scientists, researchers, and engineers every month. Phys.org publishes approximately 100 quality articles every day, offering some of the most comprehensive coverage of sci-tech developments world-wide. Quancast 2009 includes Phys.org in its list of the Global Top 2,000 Websites. Phys.org community members enjoy access to many personalized features such as social networking, a personal home page set-up, RSS/XML feeds, article comments and ranking, the ability to save favorite articles, a daily newsletter, and other options.
So I bit and visited New technique completely protects internet pictures and videos from cyberattacks, which reads in part:
A Ben-Gurion University of the Negev (BGU) researcher has developed a new technique that could provide virtually 100 percent protection against cyberattacks launched through internet videos or images, which are a growing threat.

“Any downloaded or streamed video or picture is a potential vehicle for a cyberattack,” says Professor Ofer Hadar, chair of BGU’s Department of Communication Systems Engineering. “Hackers like videos and pictures because they bypass the regular data transfer systems of highly secure systems, and there is significant space in which to implant malicious code.”…
“Preliminary experimental results show that a method based on a combination of Coucou Project techniques results in virtually 100 percent protection against cyberattacks,” says Prof. Hadar. “We envision that firewall and antivirus companies will be able to utilize Coucou protection applications and techniques in their products.”
The Coucou Project receives funding from the BGU Cyber Security Research Center and the BaseCamp Innovation Center at the Advanced Technologies Park adjacent to BGU, which is interested in developing the protective platform into a commercial enterprise.
Summary: Cyberattackers using internet videos or images are in little danger of being thwarted any time soon.
First, Professor Hadar’s technique would need to be verified by other researchers. (Possibly has been but no publications are cited.)
Second, the technique must not introduce additional cybersecurity weaknesses.
Third, vendors have to adopt and implement the techniques.
Fourth, users must upgrade to new software that incorporates the new techniques.
A more accurate headline reads:
New Technique In Theory Protects Pictures and Videos From Cyberattacks
Yes?