Most topic map software, either explicitly or implicitly, is targeted at developers.
I ran across a graphic today that highlights what I consider to be a flaw in that strategy.
The original graphic concerns the number of students enrolled in computer science:

I first saw that in a tweet by Matt Asay.
I need to practice (read learn) Gimp skills so my first attempt to re-purpose the graphic was:
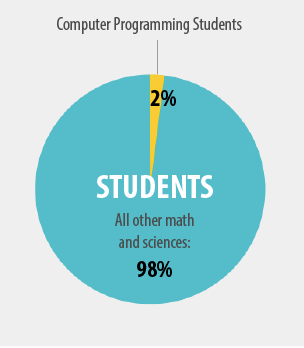
But that leaves my main point implied, so after some fiddling, I got:
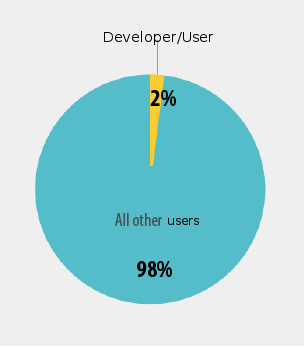
Even without a marketing degree, I can pick the better marketing target.
What about you?
BTW, the experience with Hadoop supports my side, not the targeting for developers argument.
Yes, a lot of Hadoop tools are difficult to use, if not black arts.
However, Hadoop marketing has more hand waving and arm flapping than you will see among Democrats on entitlement reform and Republicans on tax reform, combined.
The Hadoop ecosystem (which I like a lot by the way) is billed to consumers as curing everything but AIDS and that is just a matter of application.
Consumer demand, from people who aren’t going to run Hadoop clusters, write pig scripts, etc. is driving developers to build better tools and to learn the harder ones.
Suggestions on how to build consumer oriented marketing of topic maps will be greatly appreciated!
My suggestion is to pick something that 98% of computer user need but where existing solutions are still inadequate and topic maps could do a much better job. Recruit a few topic mappers for an open source project and get a small desktop application out where people can download it an use it. Nothing sells a technology like users of an application they are happy with. Duh, right?
After I understood Topic Maps, there was an application I was hoping to find but didn’t. I’m sure I’ll never get around to writing it but I’d be glad to use/test/document it if someone else wrote it. The application that everyone needs but where there are no good alternatives are file and/or bookmark searching. Yes I know there are are file indexers built in or can be added onto every operating system but word search often does not cut it and indexing does not help with mapped drives, drop-boxes, removable drives, encrypted files, and bookmarks.
Almost everyone keeps many, many files and bookmarks and they are usually kept in trees of folders and named using short words and abbreviations. Rather than doing word searches and getting a 1000 hits or 0 hits, it would be much easier to search by context where the context of a file or bookmark included all the metadata of the file and all the words (and associated synonyms) used in the tree where the file is stored.
The user had a reason for storing the file there so presumably the context would make sense to them no matter what it was ad the context would not have to be the same each user. If it is a bookmark or a file on the KDE Semantic Desktop, or one of a few file types on Windows, it might also have some tags assigned.
Software_Projects
–Open_Source
—-Topic_Maps
——Applications
——–Startr_Proj_Req.doc
(Created: 1/11/11, Modified: 4/1/11, Author: Patrick_D)
Even the small tree above provides a lot of context for the file.
With file search, I would need to remember what I called it. With word search, I need to remember the content of the file and I need to have the file indexed. With a Topic Map based context search I should only need to remember something about the file. Like:
– I saved it a couple of years ago when I was working on the Topic Map Application.
– I wrote some software requirement for an open source project.
– Pat did some work on a free application a while back (found through synonyms).
Because it would rely only on file/bookmark context and not content, it would be fast, it would work everywhere, and everyone who uses a computer could use to it to get some benefit.
Comment by clemp — April 4, 2013 @ 1:44 pm
That’s a great outline of an topic map based application! Although I would separate out file from bookmark search, mostly because of different implementation strategies.
While it could be something to download, thinking a bookmark application would be better as an improvement to an existing bookmark manager in a browser. That supports exporting to a TM interchange format. Some default use of synonyms, with custom synonyms from users. And upon user request, generate associations with the users who bookmarked the resources. Possibly the keywords from the resource that was bookmarked.
A file search application would have different associations to cover your removable drives, network drives, etc. Perhaps even tracking backup bits? Associations with other files open while editing a file?
Questions like: Should I open all the spreadsheets you have associated with this one? Or emails? Or documents?
Don’t have to re-write any of the application logic, just passing file names to existing applications.
It too could be an aftermarket install but suspect it would do better as a native application.
Doesn’t take away from its topic map nature that it isn’t stand alone software.
In fact might ease adoption because it makes some existing application better.
PS: I just installed the latest Ontopia release (I was running 5.2.1). Will be tomorrow but I will check the port and path issues I mentioned in my other response.
Comment by Patrick Durusau — April 4, 2013 @ 4:09 pm
I think you are right that a bookmark add-on for the brower would make a better showcase to start with. It would be easier to build, would be more universal, and it could take advantage of web based information resources by default. Since many of the topic map libraries seem to have a web focus, it might be a better fit there as well.
When I think back through the killer applications of the past, they all appear to contain a bit of magic in that you, as the user, get back more than you have to put in. I think that is the promise of a Topic Map application that has not yet been demonstrated in a real application (at least not one that I have seen). It has the potential to give you back much more than you put in by showing you related material where you, as the user, did not have to explicitly define which items are related.
Comment by clemp — April 5, 2013 @ 6:41 am
Just thinking out loud but what if a bookmark add-on could generate from say a blog roll, a list of the links from that page, create associations and then display other pages that point to the same links? Separately?
Perhaps even sort the bookmarks according to how many of the other sites in your bookmarks that point to them?
Sort of a personalized page ranking.
Comment by Patrick Durusau — April 6, 2013 @ 5:24 am
That sounds like a good idea to me. I think that is the type of thing that could get wide usage because it doesn’t take much effort from the user in the same way that a Google search doesn’t take much effort.
Google does not give great results (as you have pointed out multiple times) but it is good enough AND it does not take much effort. Social bookmarking is popular because you can add a few of your own bookmarks and then get to take advantage of the data all the other users have entered. Same story for for almost every application and device. iPods were not better at playing music, they were just easier to use. As long as some application or device has crossed the “good enough” threshold, then easier seems to beat better almost every time.
My impression is that, to date, the Topic Map community has been trying to sell the power of topic maps by promising something better than the current search, database, and e-publishing applications: Better information. More prcise linking. Improved flexibility. That all may be true but I think what most consumers want (including me) is something that is easier and faster.
What you described above is easier. Searching for files or bookmarks could be easier/faster with topic maps. I could put in a little information and quickly get a lot of information back out. That is the power that got me interested in topic maps in the first place: The ability to extract meaning out of the data that users already have through associations they did not have to explicitly enter. They enter a little information and, through associations with automatically extracted information, the topic map application gives them back more than they put in.
Maybe that automatic part is just really hard because, for some reason, the topic map applications I have tried (Wandora excepted) focus on the richness of the information that the user can enter.
Comment by clemp — April 6, 2013 @ 12:45 pm
The automatic part is very hard. That’s the semantics part that is so hard to automate, even for something as simple as searching.
In some ways it may be a form of information entropy. You can’t get more out of an information system than has been put into it. Yes?
Perhaps we should leave cheap and good in the fast-cheap-good project diagram and replace “fast” with “easy?” What do you think?
Comment by Patrick Durusau — April 7, 2013 @ 6:30 pm
So easy-cheap-good (enough). I think that’s what does sell the most. (With easy-expensive-good coming in second).
I think T. Passin’s idea in the link you posted http://conferences.idealliance.org/extreme/html/2003/Passin01/EML2003Passin01.html could be refined to meet the easy-cheap-good enough criteria. The same idea could be extended into file trees, collections of notes and other things where we create informal hierarchies.
Another example of easy-cheap-good enough semantics along the same lines was an information management product from Lotus back in the early 1990’s. It was called Agenda (http://en.wikipedia.org/wiki/Lotus_Agenda) and, once you got through the learning curve, it was great. It ran under DOS but I continued to use it long after DOS was dead because it was so helpful and no other software could do the same thing. Basically, it was a note taking application (now called PIM) but, independently, you could build what was essentially a thesaurus and you just tailored the thesaurus for the type of information you wanted to track.
Agenda would automatically tag all the notes based on the terms in your personal thesaurus. The assignment was not perfect but it was good enough to be very useful. You could type “Meet with Joe next Tuesday about the Delta project.” and then later find the note on you calendar as an appointment, in the list of notes under People/Joe, on your list of meetings for the next week, and in the list of notes under Projects/Delta.
After you built the thesaurus, it was very easy to find any note based on the informal semantics you defined separately.
Comment by clemp — April 7, 2013 @ 7:39 pm
Thanks for the pointer to Agenda!
FYI, its freeware now: http://www2.support.lotus.com/ftp/pub/desktop/Agenda/dos/2.0/misc/ .
I think the idea of a user’s personal thesaurus is a good one. In part because it is capturing the user’s semantics, not those of an expert.
Will see what DOS emulators I can find for a VM just to get a feel for it.
Comment by Patrick Durusau — April 8, 2013 @ 6:42 pm