If you aren’t familiar with Right Relevance, you are missing an amazing resource for cutting through content clutter.
Starting at the default homepage:
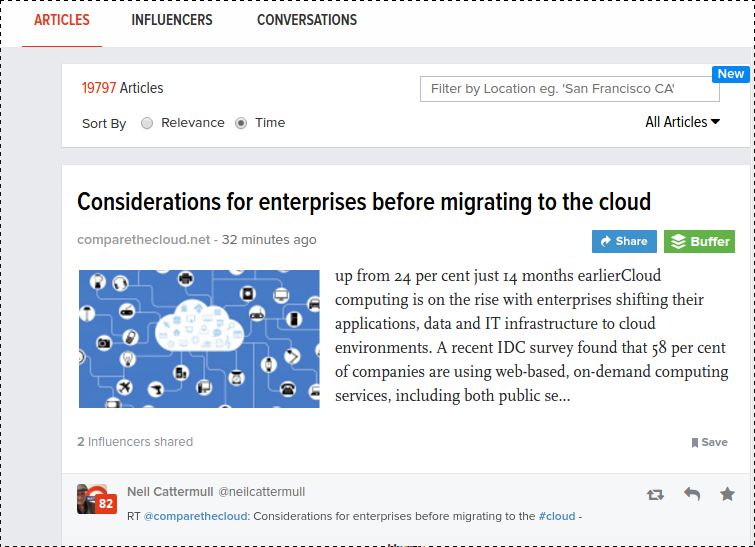
You can search for “big data” and the default result screen appears:
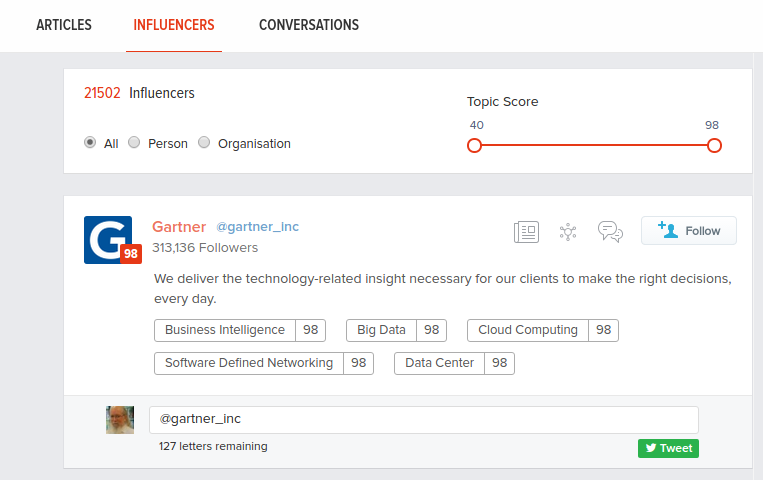
If you switch to “people,” the following screen appears:
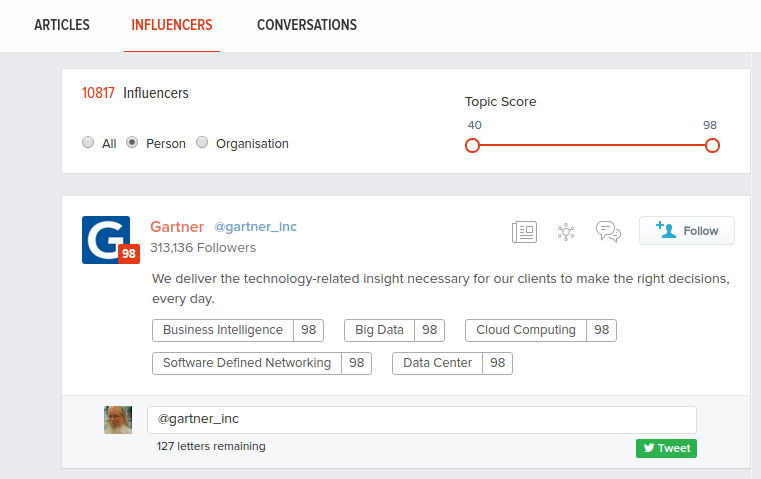
The “topic score” line moves, so you can require a higher or lesser score for inclusion in the listing. That is helpful if you want only the top people, articles, etc. on a topic or want to reach deeper into the pool of data.
As of yesterday, if you set the “topic score” to the range 70 to 98, the number of people influencers was 1880.
The interface allows you to follow and/or tweet to any of those 1880 people, but only one at a time.
I submitted feedback to Right Relevance on Monday of this week pointing out how useful lists of Twitter handles could be for creating Twitter seed lists, etc., but have not gotten a response.
Part of my query to Right Relevance concerned the failure of a web scraper to match the totals listed in the interface (a far lower number of results than expected).
In the absence of an answer, I continue to experiment with the Web Scraper extension for Chrome to extract data from the site.
Caveat: In order to set the delay for requests in Web Scraper, I have found the settings under “Scrape” ineffectual:

In order to induce enough delay to capture the entire list, I set the delay in the exported sitemap (in JSON) and then imported it into another sitemap. Could have reached the same point by setting the delay under the top selector, which was also set to SelectorElementScroll.
To successfully retrieve the entire list, that delay setting was 16000 miliseconds.
There may be more performant solutions but since it ran in a separate browser tab and notified me of completion, time wasn’t an issue.
I created a sitemap that obtains the user’s name, Twitter handle and number of Twitter followers, bigdata-right-relevance.txt.
Oh, the promised 1880-big-data-influencers.csv. (File renamed post-scraping due to naming constraints in Web Scraper.)
At best I am a casual user of Web Scraper so suggestions for improvements, etc., are greatly appreciated.