When I first read about: Facebook Ads: Exposing Russia’s Effort to Sow Discord Online: The Internet Research Agency and Advertisements, a release of alleged Facebook ads, by Democrats of the House Permanent Select Committee on Intelligence, I should have just ignored it.
But any number of people whose opinions I respect, seem deadly certain that Facebook ads, purchased by Russians, had a tipping impact on the 2016 presidential election. At least I should look at the purported evidence offered by House Democrats. The reporting I have seen on the release indicates at best skimming of the data, if it is read at all.
It wasn’t until I started noticing oddities in a sample of the data that I cleaned that the full import of:
Redactions Completed at the Direction of Ranking Member of the US House Permanent Select Committee on Intelligence
That statement appears in every PDF file. Moreover, if you check the properties of any of the PDF files, you will find a creation date in May of 2018.
I had been wondering why Facebook would deliver ad data to Congress as PDF files. Just seemed odd, something nagging in the back of my mind. Terribly inefficient way to deliver ad data.
The “redaction” notice and creation dates make it clear that the so-called Facebook ad PDFs, are wholly creations of the House Permanent Select Committee on Intelligence, and not Facebook.
I bring that break in the data chain because without knowing the content of the original data from Facebook, there is no basis for evaluating the accuracy of the data being delivered by Congressional Democrats. It may or may not bear any resemblance to the data from Facebook.
Rather than a blow against whoever the Democrats think is responsible, this is a teaching moment about the provenance of data. If there is a gap, such as the one here, the only criteria for judging the data is do you like the results? If so, it’s good data, if not, then it’s bad data.
Why so-called media watch-dogs on “fake news” and mis-information missed such an elementary point isn’t clear. Perhaps you should ask them.
While cleaning the data for October of 2016, my suspicions were re-enforced by the following:
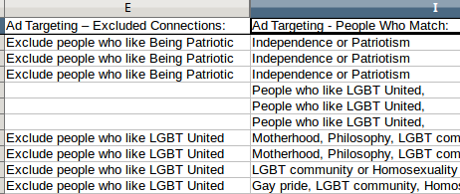
Doesn’t it strike you as odd that both the exclusion targets and ad targets are the same? Granting it’s only seven instances in this one data sample of 135 ads, but that’s enough for me to worry about the process of producing the files in question.
If you decide to invest any time in this artifice of congressional Democrats, study the distribution of the so-called ads. I find it less than credible that August of 2017 had one ad placed by (drum roll), the Russians! FYI, July 2017 had only seven.
Being convinced the Facebook ad files from Congress are contrived representations with some unknown relationship to Facebook data, I abandoned the idea of producing a clean data set.
Resources:
PDFs produced by Congress, relationship to Facebook data unknown.
Cleaned July, 2015 data set by Patrick Durusau.
Text of all the Facebook ads (uncleaned), September 2015 – August 2017 (missing June – 2017) by Patrick Durusau. (1.2 MB vs. their 8 GB.)
Seriously pursuit of any theory of ads influencing the 2016 presidential election, has the following minimal data requirements:
- All the Facebook content posted for the relevant time period.
- Identification of paid ads and by what group, organization, government they were placed.
Assuming that data is available, similarity measures of paid versus user content and measures of exposure should be undertaken.
Notice that none of the foregoing “prove” influence on an election. Those are all preparatory steps towards testing theories of influence and on who, to what extent?

