Recently “Hyperedges and Cypher” was cited to illustrate “improvements” to Neo4j documentation. It is deeply problematic.
The first paragraph and header read:
5.1 Hyperedges and Cypher
Imagine a user being part of different groups. A group can have different roles, and a user can be part of different groups. He also can have different roles in different groups apart from the membership. The association of a User, a Group and a Role can be referred to as a HyperEdge. However, it can be easily modeled in a property graph as a node that captures this n-ary relationship, as depicted below in the U1G2R1 node.
This is the first encounter of hyperedge (other than in the table of contents) for the reader. The manual offers no definition for or illustration of a “hyperedge.”
When terms are introduced, they need to be defined.
Here is the Neo4j illustration for the preceding description (from the latest milestone release):
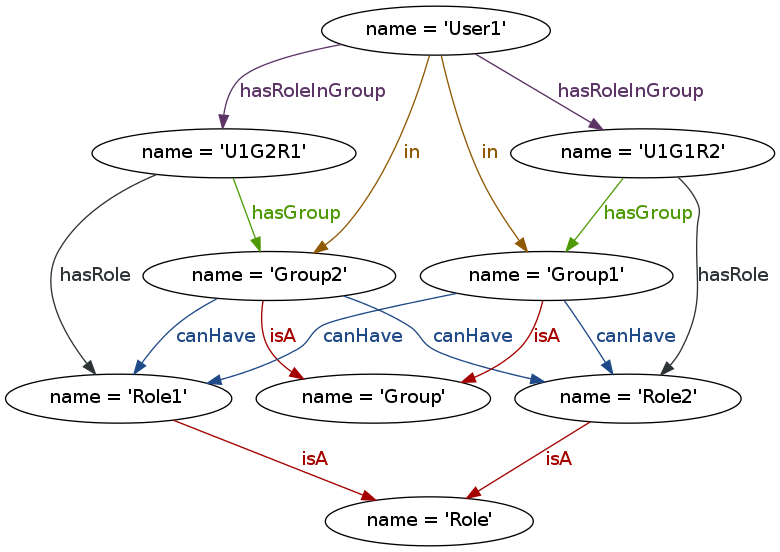
I don’t get that graph from the description in the text.
This graph comes closer:
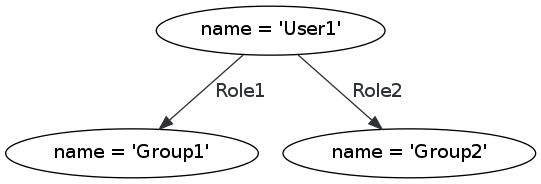
You may object that role1 and role2 should be nodes rather than an edges, but that is a modeling decision, another area where the Neo4j manual is weak. The reader doesn’t share in that process, nodes and edges suddenly appear and the reader must work out why?
If the current prose were cleaned up, by providing a better prose description, modeling choices and alternatives could be illustrated, along with Cypher queries.
On hypergraphs/hyperedges:
A user having different roles in different groups could be modeled with a hyperedge, but not necessarily so. If Neo4j isn’t going to support hyperedges, why bring it up? Show the modeling that Neo4j does support.
If I were going to discuss hyperedges/hypergraphs at all, I would point out examples of where they are used, along with citations to the literature.