NarcoData is a new collaboration that aims to track and visualize the drug cartels of Mexico by Laura Hazard Owen.
From the post:
NarcoData, a collaboration between Mexican digital news site Animal Politico and data journalism platform Poderopedia, launched Tuesday with a mission to shine light on organized crime and drug trafficking in Mexico.
“The Mexican state has failed in giving its citizens accurate, updated, and systematic information about the fight against organized crime,” said Dulce Ramos, editor-in-chief of Animal Politico and the general coordinator for NarcoData. “NarcoData wants to fill that empty space.”
The site examines four decades of data to explain how drug trafficking reached its current size and influence in the country. The idea for the project came about last year, when Animal Politico obtained, via the Mexican transparency act, a government chart outlining all of the criminal cells operating in the country. Instead of immediately publishing an article with the data, Animal Politico delved further to fill in the information that the document was missing.
Even a couple of months later, when the document went public and some legacy media outlets wrote articles about it and made infographics from it, “we remained sure that that document had great potential, and we didn’t want to waste it,” Ramos said. Instead, Animal Politico requested and obtained more documents and corroborated the data with information from books, magazines, and interviews.
…
If you are unfamiliar with the status of the drug war in Mexico, consider the following:
Mexico’s drug war is getting even worse by Jeremy Bender:
…At least 60,000 people are believed to have died between 2006 and 2012 as a result of the drug war as cartels, vigilante groups, and the Mexican army and police have battled each other.
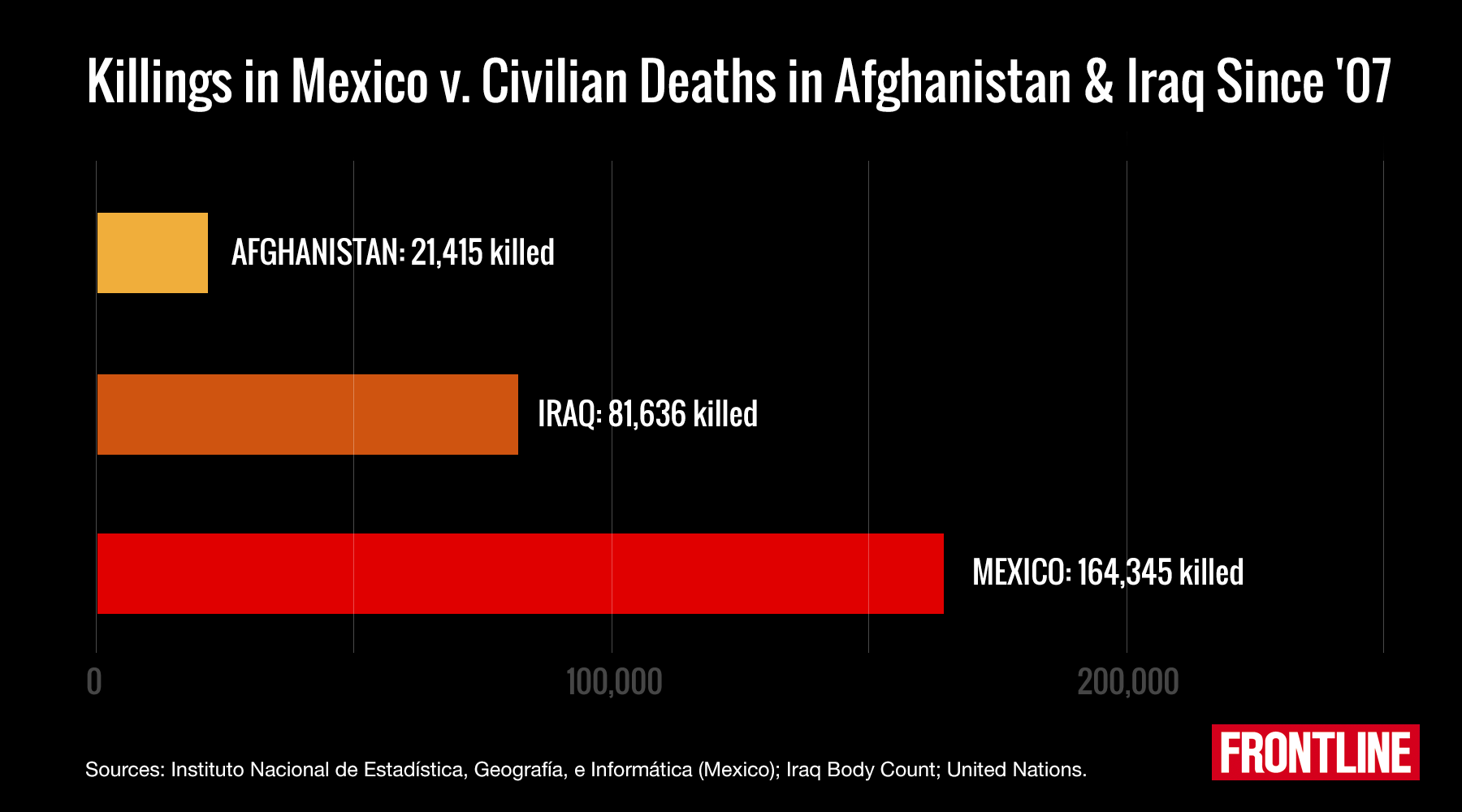
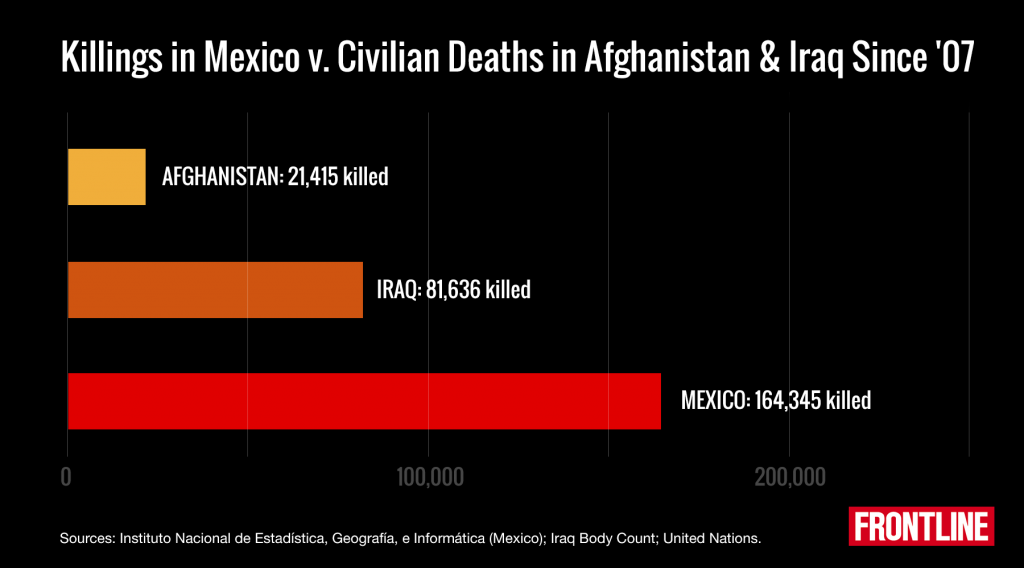
The Staggering Death Toll of Mexico’s Drug War by Jason M. Breslow:
Last week, the Mexican government released new data showing that between 2007 and 2014 — a period that accounts for some of the bloodiest years of the nation’s war against the drug cartels — more than 164,000 people were victims of homicide. Nearly 20,000 died last year alone, a substantial number, but still a decrease from the 27,000 killed at the peak of fighting in 2011.
Over the same seven-year period, slightly more than 103,000 died in Afghanistan and Iraq, according to data from the and the website .
‘Journalists are being slaughtered’ – Mexico’s problem with press freedom by Nina Lakhani.
…
Journalists and press freedom groups have expressed growing anger at Mexican authorities’ failure to tackle escalating violence against reporters and activists who dare to speak out against political corruption and organised crime.
Espinosa was the 13th journalist working in Veracruz to be killed since Governor Javier Duarte from the ruling Institutional Revolutionary party (PRI) came to power in 2011. According to the press freedom organisation Article 19, the state is now the most dangerous place to be a journalist in Latin America.
…
According to the Committee to Protect Journalists, about 90% of journalist murders in Mexico since 1992 have gone unpunished.
Patrick Timmons, a human rights expert who investigated violence against journalists while working for the UK embassy in Mexico City, said the massacre was another attempt to silence the press: “These are targeted murders which are wiping out a whole generation of critical leaders.”
…
Against that background of violence and terror, NarcoData emerges. Mexican journalists speak out against the drug cartels and on behalf of the people of Mexico who suffer under the cartels.
I am embarrassed to admit sharing U.S. citizenship with the organizers of South by Southwest (SXSW). Under undisclosed “threats” of violence because of panels to discuss online harassment, the SXSW organizers cancelled the panels. Lisa Vaas captures those organizers perfectly in her headline: SXSW turns tail and runs, nixing panels on harassment.
I offer thanks that the SXSW organizers were not civil rights organizers in: SXSW turns tail and runs… [Rejoice SXSW Organizers Weren’t Civil Rights Organizers] Troll Police.
NarcoData sets an example of how to respond to drug cartels or Internet trolls. Shine a bright light on them. Something the SXSW organizers were too timid to even contemplate.
Fighting Internet trolls requires more than anecdotal accounts of abuse. Imagine a TrollData database that collects data from all forms of social media, including SMS messages and email forwarded to it. So that data analytics can be brought to bear on the data with a view towards identifying trolls by their real world identities.
Limited to Twitter but a start in that direction is described in: How do you stop Twitter trolls? Unleash a robot swarm to troll them back by Jamie Bartlett.
Knowing how to deal with Internet trolls is tricky, because the separating line between offensive expression and harassment very fine, and usually depends on your vantage point. But one subspecies, the misogynist troll, has been causing an awful lot of trouble lately. Online abuse seems to accompany every woman that pops her head over the parapet: Mary Beard, Caroline Criado-Perez, Zelda Williams and so on. It’s not just the big fish, either. The non-celebs women cop it too, but we don’t hear about it. Despite near universal condemnation of this behaviour, it just seems to be getting worse.
Today, a strange and mysterious advocacy group based in Berlin called the “Peng! Collective” have launched a new way of tackling the misogynistic Twitter trolls. They’re calling it “Zero Trollerance.”
Here’s what they are doing. If a Twitter user posts any one of around one hundred preselected terms or words that are misogynistic, a bot – an automated account – spots it, and records that user’s Twitter handle in a database. (These terms, in case you’re wondering, include, but are not limited to, the following gems: #feministsareugly #dontdatesjws “die stupid bitch”, “feminazi” and “stupid whore”.)
This is the clever bit. This is a lurking, listening bot. It’s patrolling Twitter silently as we speak and taking details of the misogynists. But then there is another fleet of a hundred or so bots – I’ll call them the attack bots – that, soon after the offending post has been identified, will start auto-tweeting messages @ the offender (more on what they tweet below).
…
“Zero Trollerance” is a great idea and I applaud it. But it doesn’t capture the true power of data mining, which could uncover trolls that use multiple accounts, trolls that are harassing other users via other social media, not to mention being able to shine light directly on trolls in public, quite possibly the thing they fear the most.
TrollData would require high levels of security, monitoring of all public social media and the ability to accept email and SMS messages forwarded to it, governance and data mining tools.
Mexican journalists are willing to face death to populate NarcoData, what do you say to facing down trolls?
In case you want to watch or forward the Zero Trollerance videos:
Zero Trollerance Step 1: Zero Denial
Zero Trollerance Step 2: Zero Internet
Zero Trollerance Step 3: Zero Anger
Zero Trollerance Step 4: Zero Fear
Zero Trollerance Step 5: Zero Hate
Zero Trollerance Step 6: Zero Troll