With $20 of Gear from Amazon, Nearly Anyone Can Make This IMSI-Catcher in 30 Minutes by Joseph Cox.
From the post:
With some dirt cheap tech I bought from Amazon and 30-minutes of set-up time, I was streaming sensitive information from phones all around me. IMSIs, the unique identifier given to each SIM card, can be used to confirm whether someone is in a particular area. They can also be used as part of another attack to take over a person’s phone number and redirect their text messages. Obtaining this information was incredibly easy, even for a non-expert.
…
But a DIY IMSI catcher is relatively trivial to setup, and the technology is accessible to anyone with a cheap laptop, $20 of gear, and, the ability to essentially copy and paste some commands into a computer terminal. This is about ease of access; a lower barrier of technical entry. In a similar way to so-called spouseware—malware used by abusive partners—surveillance takes on different character when it trickles down to more ordinary, everyday users. The significance and threat from IMSI-catchers is multiplied when a lot more people can deploy one.
…
Once you get up and running, project’s github page, other extensions and uses will occur to you.
I deeply disagree with the assessment:
The significance and threat from IMSI-catchers is multiplied when a lot more people can deploy one.
The greater danger comes when secret agencies and even police agencies, operate with no effective oversight. Either because their operations are too secret to be known to others or a toady, such as the FISA court, is called upon to pass judgment.
As the “threat” from IMSI-catchers increases, manufacturers will engineer phones that resist attacks from the government and the public. A net win for the public, if not the government.
IMSI-catchers and more need to be regulars around government offices and courthouses. Governments like surveillance so much, let’s provide them with a rich and ongoing experience of the same.

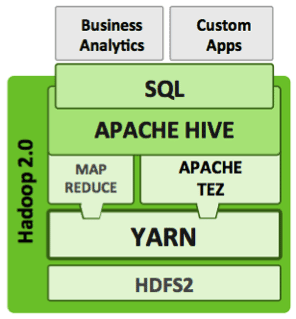 Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.
Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.