Hacker Fantastic and x0rz have been deriding Shadow Brokers Response Team is creating open & transparent crowd-funded analysis of leaked NSA tools.
In part because whitehats will get the data at the same time.
Even if whitehats could instantly generate patches for all the vulnerabilities in each monthly release, if the vulnerabilities do have value, always an open question, they will retain that value for years, even more than a decade.
Why?
Roger Grimes recites the folk wisdom:
…
Folk wisdom says that patching habits can be divided into quarters: 25 percent of people patch within the first week; 25 percent patch within the first month; 25 percent patch after the first month, and 25 percent never apply the patch. The longer the wait, the greater the increased risk.
…
Or to put that another way:
50% of all vulnerable systems remain so 30+ days after the release.
25% of all vulnerable systems remain so forever.
Here’s a “whitehat” graphic that makes a similar point:
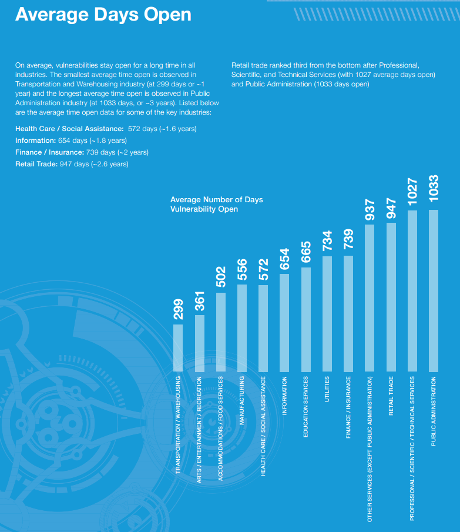
(From: Website Security Statistics Report 2015)
For $100 each by 2500 people, assuming there are vulnerabilities in the first Shadow Brokers monthly release, you get:
Vulnerabilities for 25% of systems forever (assuming patches are possible), vulnerabilities for 50% of systems are vulnerable for more than a month (assuming patches are possible), for some industries offer years of vulnerability, especially government systems.
For a $100 investment?
Modulo my preference for a group buy, then distribute model, that’s not a bad deal.
If there are no meaningful vulnerabilities in the first release, then don’t spend the second $100.
A commodity marketplace for malware weakens the NSA and its kindred. That’s reason enough for me to invest.

