Building a Telecom Dictionary scraping web using rvest in R by Abdul Majed Raja.
From the post:
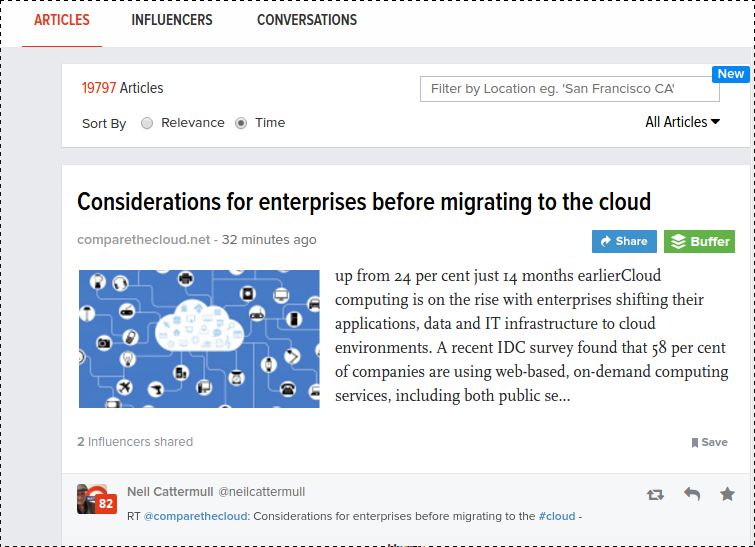
One of the biggest problems in Business to carry out any analysis is the availability of Data. That is where in many cases, Web Scraping comes very handy in creating that data that’s required. Consider the following case: To perform text analysis on Textual Data collected in a Telecom Company as part of Customer Feedback or Reviews, primarily requires a dictionary of Telecom Keywords. But such a dictionary is hard to find out-of-box. Hence as an Analyst, the most obvious thing to do when such dictionary doesn’t exist is to build one. Hence this article aims to help beginners get started with web scraping with rvest in R and at the same time, building a Telecom Dictionary by the end of this exercise.
…
Great for scraping an existing glossary but as always, it isn’t possible to extract information that isn’t captured by the original glossary.
Things like the scope of applicability for the terms, language, author, organization, even characteristics of the subjects the terms represent.
Of course, if your department invested in collecting that information for every subject in the glossary, there is no external requirement that on export all that information be included.
That is your “data silo” can have tunable transparency, that is you enable others to use your data with as much or as least semantic friction as the situation merits.
For some data borrowers, they get opaque spreadsheet field names, column1, column2, etc.
Other data borrowers, perhaps those willing to help defray the cost of semantic annotation, well, they get a more transparent view of the data.
One possible method of making semantic annotation and its maintenance a revenue center as opposed to a cost one.