Intel Exec: Extracting Value From Big Data Remains Elusive by George Leopold.
From the post:
Intel Corp. is convinced it can sell a lot of server and storage silicon as big data takes off in the datacenter. Still, the chipmaker finds that major barriers to big data adoption remain, most especially what to do with all those zettabytes of data.
“The dirty little secret about big data is no one actually knows what to do with it,” Jason Waxman, general manager of Intel’s Cloud Platforms Group, asserted during a recent company datacenter event. Early adopters “think they know what to do with it, and they know they have to collect it because you have to have a big data strategy, of course. But when it comes to actually deriving the insight, it’s a little harder to go do.”
Put another way, industry analysts rate the difficulty of determining the value of big data as far outweighing considerations like technological complexity, integration, scaling and other infrastructure issues. Nearly two-thirds of respondents to a Gartner survey last year cited by Intel stressed they are still struggling to determine the value of big data.
“Increased investment has not led to an associated increase in organizations reporting deployed big data projects,” Gartner noted in its September 2014 big data survey. “Much of the work today revolves around strategy development and the creation of pilots and experimental projects.”
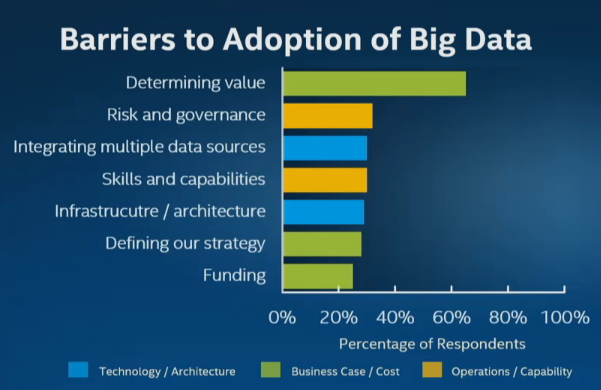
It may just be me, but “determing value,” “risk and governance,” and “integrating multiple data sources,” the top three barriers to use of big data, all depend on knowing the identities represented in big data.
The trivial data integration demos that share “customer-ID” fields, don’t inspire a lot of confidence about data integration when “customer-ID” maybe identified in as many ways as there are data sources. And that is a minor example.
It would be very hard to determine the value you can extract from data when you don’t know what the data represents, its accuracy (risk and governance), and what may be necessary to integrate it with other data sources.
More processing power from Intel is always welcome but churning poorly understood big data faster isn’t going to create value. Quite the contrary, investment in more powerful hardware isn’t going to be favorably reflected on the bottom line.
Investment in capturing the diverse identities in big data will empower easier valuation of big data, evaluation of its risks and uncovering how to integrate diverse data sources.
Capturing diverse identities won’t be easy, cheap or quick. But not capturing them will leave the value of Big Data unknown, its risks uncertain and integration a crap shoot when it is ever attempted.
Your call.
[…] http://tm.durusau.net/?p=64541 […]
Pingback by Barreres a l’adopció de tècniques i continguts de Big Data | Blog d'estadística oficial — September 16, 2015 @ 2:04 am