Using machine learning algorithms, Spark and Scala – Part 2 by Ofer Mendelevitch and Beau Plath.
From the post:
In this 2nd part of the blog post and its accompanying IPython Notebook in our series on Data Science and Apache Hadoop, we continue to demonstrate how to build a predictive model with Apache Hadoop, using existing modeling tools. And this time we’ll use Apache Spark and ML-Lib.
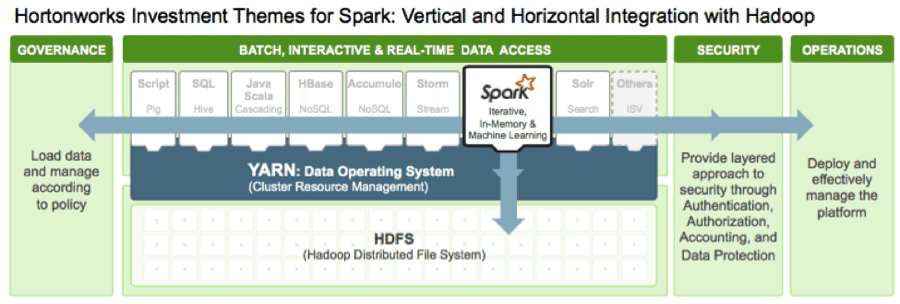
Apache Spark is a relatively new entrant to the Hadoop ecosystem. Now running natively on Apache Hadoop YARN, the architectural center of Hadoop, Apache Spark is an in-memory data processing API and execution engine that is effective for machine learning and data science use cases. And with Spark on YARN, data workers can simultaneously use Spark for data science workloads alongside other data access engines–all accessing the same shared dataset on the same cluster.
…
The next installment in this series continues the analysis with the same dataset but then with R!
The bar for user introductions to technology is getting higher even as we speak!