BigBench: Toward An Industry-Standard Benchmark for Big Data Analytics by Bhaskar D Gowda and Nishkam Ravi.
From the post:
Benchmarking Big Data systems is an open problem. To address this concern, numerous hardware and software vendors are working together to create a comprehensive end-to-end big data benchmark suite called BigBench. BigBench builds upon and borrows elements from existing benchmarking efforts in the Big Data space (such as YCSB, TPC-xHS, GridMix, PigMix, HiBench, Big Data Benchmark, and TPC-DS). Intel and Cloudera, along with other industry partners, are working to define and implement extensions to BigBench 1.0. (A TPC proposal for BigBench 2.0 is in the works.)
BigBench Overview
BigBench is a specification-based benchmark with an open-source reference implementation kit, which sets it apart from its predecessors. As a specification-based benchmark, it would be technology-agnostic and provide the necessary formalism and flexibility to support multiple implementations. As a “kit”, it would lower the barrier of entry to benchmarking by providing a readily available reference implementation as a starting point. As open source, it would allow multiple implementations to co-exist in one place and be reused by different vendors, while providing consistency where expected for the ability to provide meaningful comparisons.
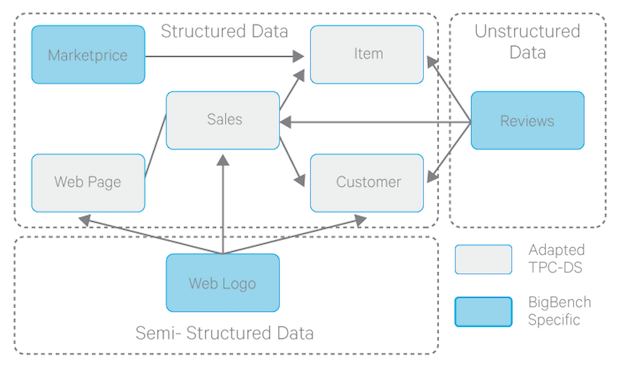
The BigBench specification comprises two key components: a data model specification, and a workload/query specification. The structured part of the BigBench data model is adopted from the TPC-DS data model depicting a product retailer, which sells products to customers via physical and online stores. BigBench’s schema uses the data of the store and web sales distribution channel and augments it with semi-structured and unstructured data as shown in Figure 1.
Figure 1: BigBench data model specification
The data model specification is implemented by a data generator, which is based on an extension of PDGF. Plugins for PDGF enable data generation for an arbitrary schema. Using the BigBench plugin, data can be generated for all three pats of the schema: structured, semi-structured and unstructured.
BigBench 1.0 workload specification consists of 30 queries/workloads. Ten of these queries have been taken from the TPC-DS workload and run against the structured part of the schema. The remaining 20 were adapted from a McKinsey report on Big Data use cases and opportunities. Seven of these run against the semi-structured portion and five run against the unstructured portion of the schema. The reference implementation of the workload specification is available here.
BigBench 1.0 specification includes a set of metrics (focused around execution time calculation) and multiple execution modes. The metrics can be reported for the end-to-end execution pipeline as well as each individual workload/query. The benchmark also defines a model for submitting concurrent workload streams in parallel, which can be extended to simulate the multi-user scenario.
…
The post continues with plans for BigBench 2.0 and Intel tests using BigBench 1.0 against various hardware configurations.
An important effort and very much worth your time to monitor.
None other than the Open Data Institute and Thomson Reuters have found that identifiers are critical to bringing value to data. With that realization and the need to map between different identifiers, there is an opportunity for identifier benchmarks in BigData. Identifiers that have documented semantics and the ability to merge with other identifiers.
A benchmark for BigData identifiers would achieve two very important goals:
First, it would give potential users a rough gauge of the amount of effort required to reach some X goal of identifiers. The cost of identifiers will vary for data set to data set but having no cost information at all, leaves potential users to expect the worst.
Second, as with the BigBench benchmark, potential users could compare apples to apples in judging the performance and characteristics of identifier schemes (such as topic map merging).
Both of those goals seem like worthy ones to me.
You?