Visual Classification Simplified
From the post:
Virtually all information governance initiatives depend on being able to accurately and consistently classify the electronic files and scanned documents being managed. Visual classification is the only technology that classifies both types of documents regardless of the amount or quality of text associated with them.
From the user perspective, visual classification is extremely easy to understand and work with. Once documents are collected, visual classification clusters or groups documents based on their appearance. This normalizes documents regardless of the types of files holding the content. The Word document that was saved to PDF will be grouped with that PDF and with the TIF that was made from scanning a paper copy of either document.
The clustering is automatic, there are no rules to write up front, no exemplars to select, no seed sets to try to tune. This is what a collection of documents might look like before visual classification is applied – no order and no way to classify the documents:
When the initial results of visual classification are presented to the client, the clusters are arranged according to the number of documents in each cluster. Reviewing the first clusters impacts the most documents. Based on reviewing one or two documents per cluster, the reviewer is able to determine (a) should the documents in the cluster be retained, and (b) if they should be retained, what document-type label to associate with the cluster.
By easily eliminating clusters that have no business or regulatory value, content collections can be dramatically reduced. Clusters that remain can have granular retention policies applied, be kept under appropriate access restrictions, and can be assigned business unit owners. Plus of course, the document-type labels can greatly assist users trying to find specific documents. (emphasis in original)

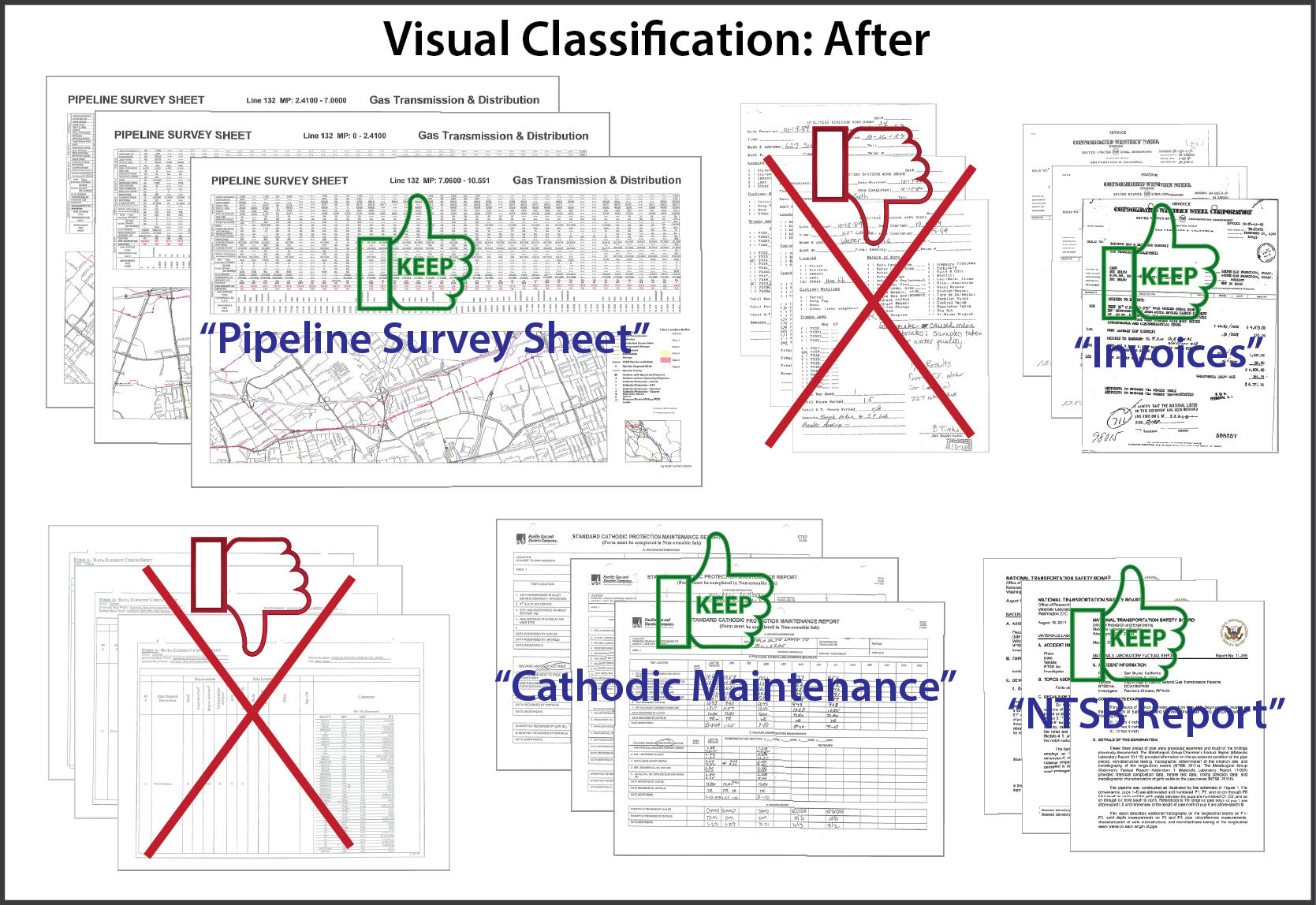
I suspect that BeyondRecognition, the host of this post, really means classification at the document level. A granularity that has plagued information retrieval for decades. Better than no retrieval at all but only just.
However, the graphics of visualization were just too good to pass up! Imagine that you are selecting merging criteria for a set of topics that represent subjects at a far lower granularity than document level.
With the results of those selections being returned to you as part of an interactive process.
If most topic map authoring is for aggregation, that is you author so that topics will merge, this would be aggregation by selection.
Hard to say for sure but I suspect that aggregation (merging) by selection would be far easier than authoring for aggregation.
Suggestions on how to test that premise?