Benefit of data clustering for osm2pgsql/mapnik rending by Christian Quest.
The main server for OpenStreetMap France had an I/O problem:
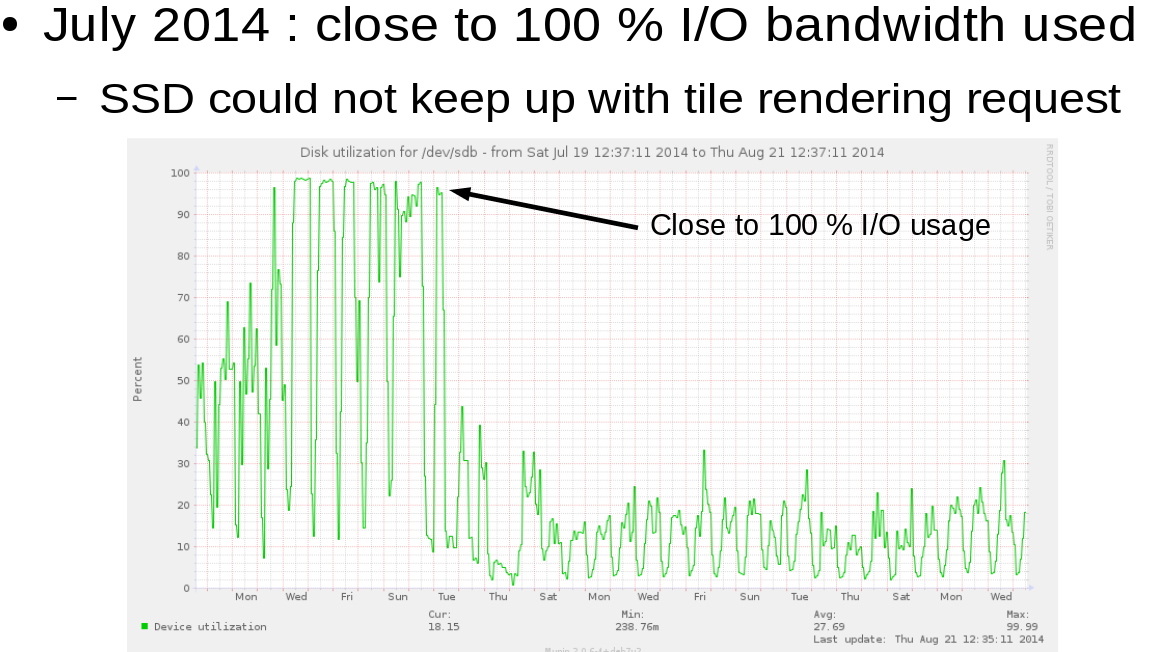
See Christian’s post for the details but the essence of the solution was to cluster geographic data on the basis of its location. To reduce the amount of I/O. Not unlike randomly seeking topics with similar characteristics.
How much did clustering reduce the I/O?
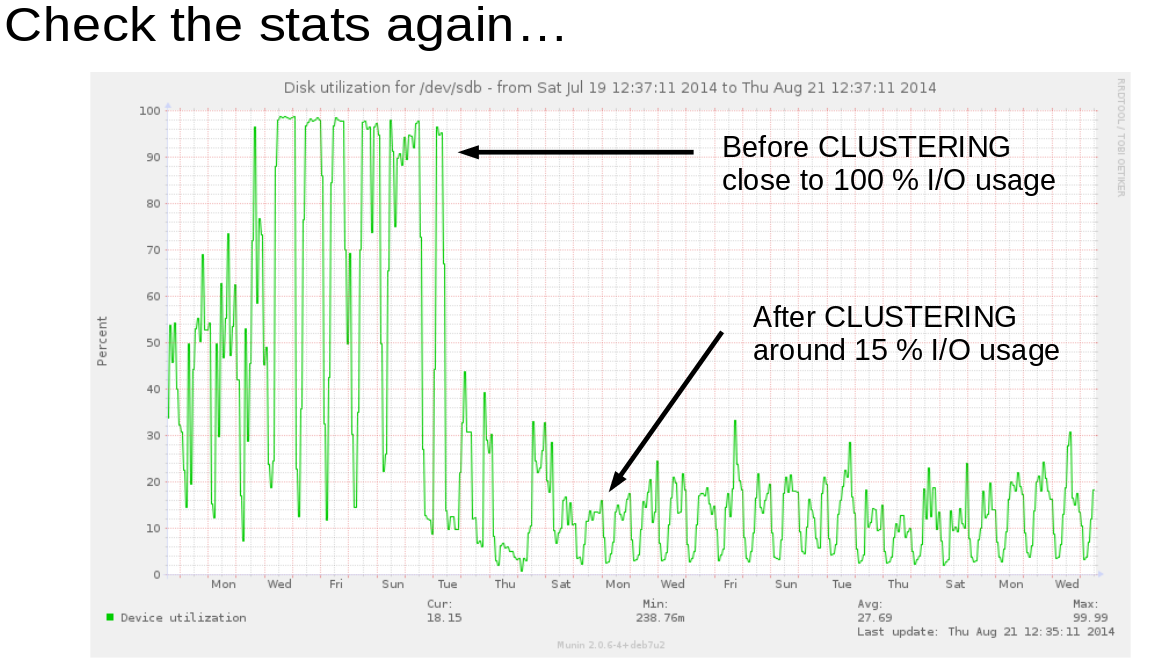
Nearly 100% I/O was reduced to 15% I/O. 85% improvement.
An 85% improvement in I/O doesn’t look bad on a weekly/monthly activity report!
Now imagine clustering topics for dynamic merging and presentation to a user. Among other things, you can have an “auditing” view that shows all the topics that will merge to form a single topic in a presentation view.
Or a “pay-per-view” view that uses a different cluster to reveal more information for paying customers.
All while retaining the capacity to produce a serialized static file as an information product.