Hadoop YARN by Steve Loughran, Devaraj Das & Eric Baldeschwieler.
From the post:
A next-generation framework for Hadoop data processing.
Apache™ Hadoop® YARN is a sub-project of Hadoop at the Apache Software Foundation introduced in Hadoop 2.0 that separates the resource management and processing components. YARN was borne of a need to enable a broader array of interaction patterns for data stored in HDFS beyond MapReduce. The YARN-based architecture of Hadoop 2.0 provides a more general processing platform that is not constrained to MapReduce.
As part of Hadoop 2.0, YARN takes the resource management capabilities that were in MapReduce and packages them so they can be used by new engines. This also streamlines MapReduce to do what it does best, process data. With YARN, you can now run multiple applications in Hadoop, all sharing a common resource management. Many organizations are already building applications on YARN in order to bring them IN to Hadoop.
(…)
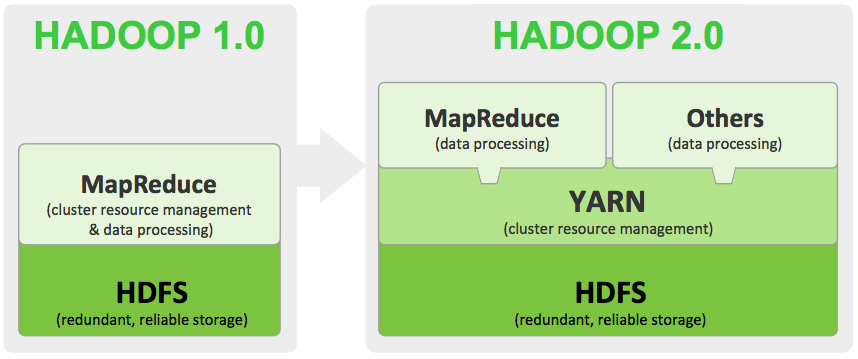
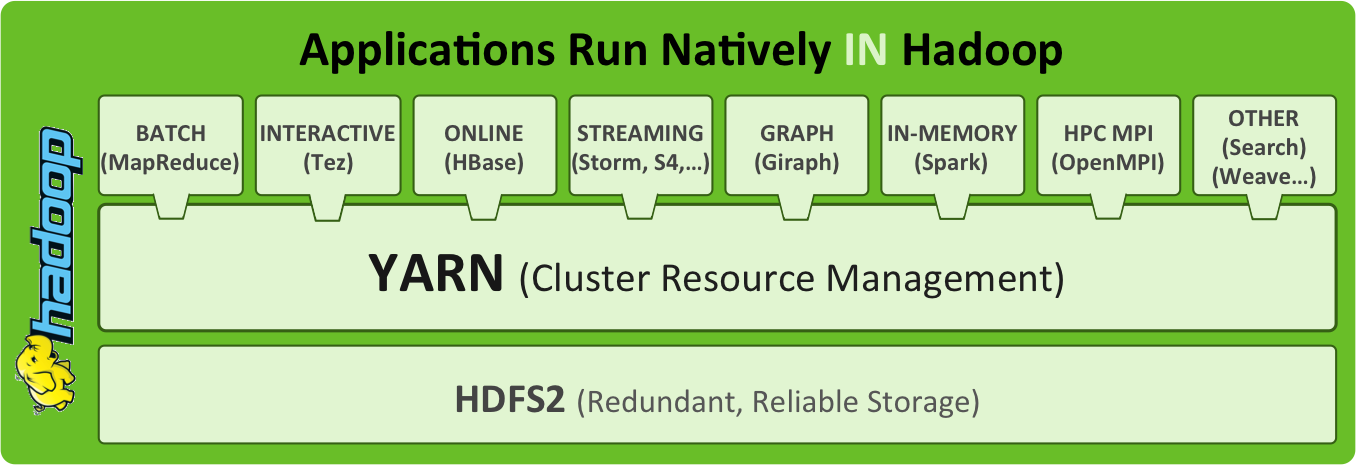
One of the more accessible explanations of the importance of Hadoop YARN.
Likely not anything new to you but may be helpful when talking to others.