I saw some ad-copy from a company that “wrote the book” on data virtualization (well, “a” book on data virtualization anyway).
Searched a bit in their documentation and elsewhere, but could not find an answer to my questions (below).
Assume departments 1 and 2, each with a data virtualization layer between their apps and the same backend resources:
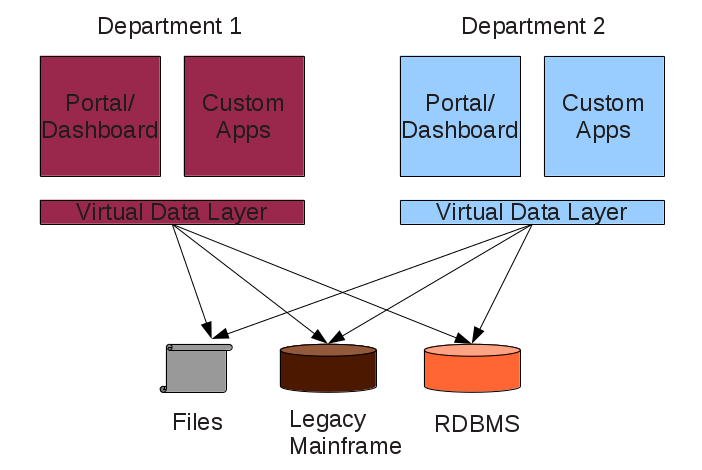
Requirement: Don’t maintain two separate data virtualization layers for the same resources.
Desired result is:
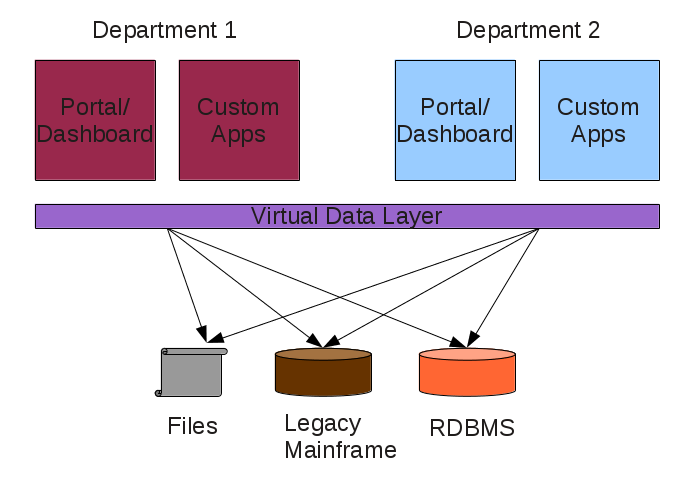
Questions: Must I return to the data resources to discover their semantices? To merge the two data virtualization layers?
Some may object there should only be one data virtualization layer.
OK, so we have Department 1 – circa 2013 and Department 1 – circa 2015, different data virtualization requirements:
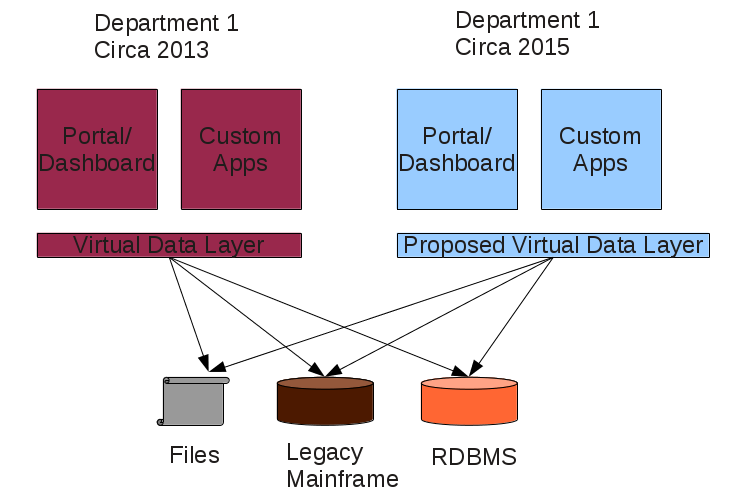
Desired result:
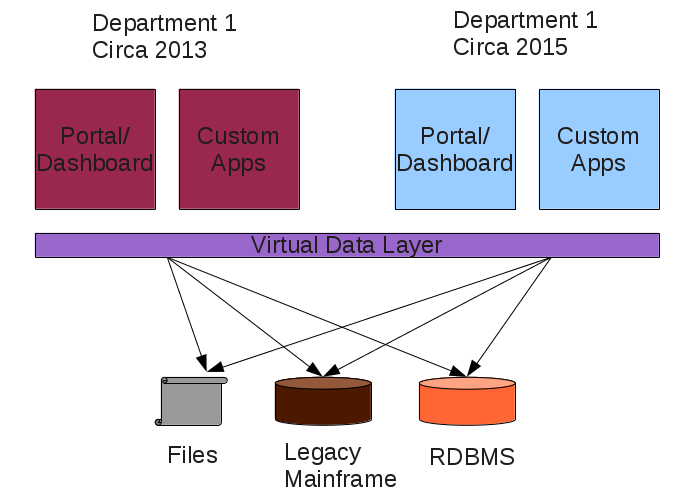
Same Questions:
Question: Must I return to the data resources to discover their semantics? To merge the existing and proposed data virtualizaton layers?
The semantics of each item in the data sources (one hopes) was determined for the original data virtualization layer.
It’s wasteful to re-discover the same semantics for changes in data virtualization layers.
Curious, how rediscovery of semantics is avoided in data virtualization software?
Or for that matter, how do you interchange data virtualization layer mappings?