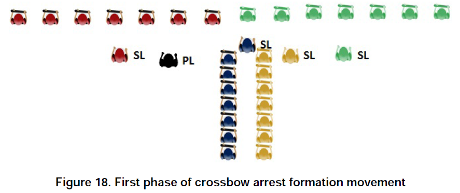
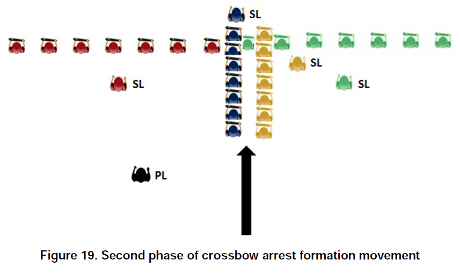
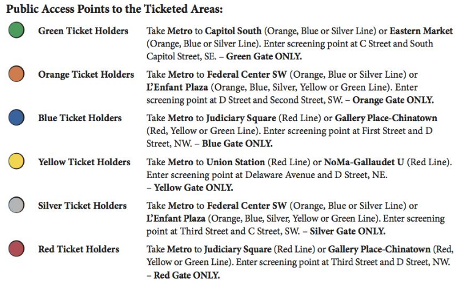
I wish my headline was some of the “fake news” Democrats complain about but Alexandra Rosemann proves the truth of that headline in:
Ignoring anti-Trumpers: Why we can expect media blackout of protests against Trump’s inauguration.
Not ignored by just anybody, ignored by the media.
On Jan. 20 — 16 years ago — thousands of protesters lined the inauguration parade route of the incoming Republican president. “Not my president,” they chanted. But despite the enormity of the rally, it was largely ignored. Instead, pundits marveled over how George W. Bush “filled out the suit” and confirmed authority.
“The inauguration of George W. Bush was certainly a spectacle on Inauguration Day,” marvels Robin Andersen, the director of Peace and Justice studies at Fordham University, in the 2001 short documentary “Not My President: Voices From the Counter Coup.”
It’s nearly impossible not to anticipate the eerie parallels between George W. Bush’s inauguration and that of Donald Trump.
“Forty percent of the public still believed that Bush had not been legitimately elected, yet there’s almost no discussion of these electoral problems or the constitutional crisis,” Andersen explains in the film. “Instead, Bush undergoes a kind of transformation where he fills out the suit and becomes a leader. Forgotten are any of the questions about his ability, his experience or his mangling of the English language. His transformation is almost magical,” she adds.
…
Andersen estimated the inauguration protests, which occurred throughout the country, garnered approximately 10 minutes of total coverage on all the major networks.
“When we did see images of protesters, there was no explanation as to why. We were asked to be passive spectators in this ritual of legitimation when the real democratic issues that should have been being discussed were ignored,” Andersen says in the film, reflecting on the “real democracy” in the streets of Washington, D.C.
…
Your choice. Ten minutes of coverage out of over 24 hours of permitted protesting, or the media covering a 24 hour blockade of the DC Beltway.
Which one do you think draws more attention to your issues?
A new president will be inaugurated on January 20, 2017, but its your choice whether its him, his wife and a few cronies in attendance or hundreds of thousands.
See protests for more ideas on that possibility.