Mapping Metaphor with the Historical Thesaurus: Visualization of Links
From the post:
By the end of the Mapping Metaphor with the Historical Thesaurus project we will have a web resource which allows the user to find pathways into our data. It will show a map of the conceptual metaphors of English over the last thousand years, showing links between each semantic area where we find evidence of metaphorical overlap. Unsurprisingly, given the visual and spatial metaphors which we are necessarily already using to describe our data and the analysis of it (e.g pathways and maps), this will be represented graphically as well as in more traditional forms.
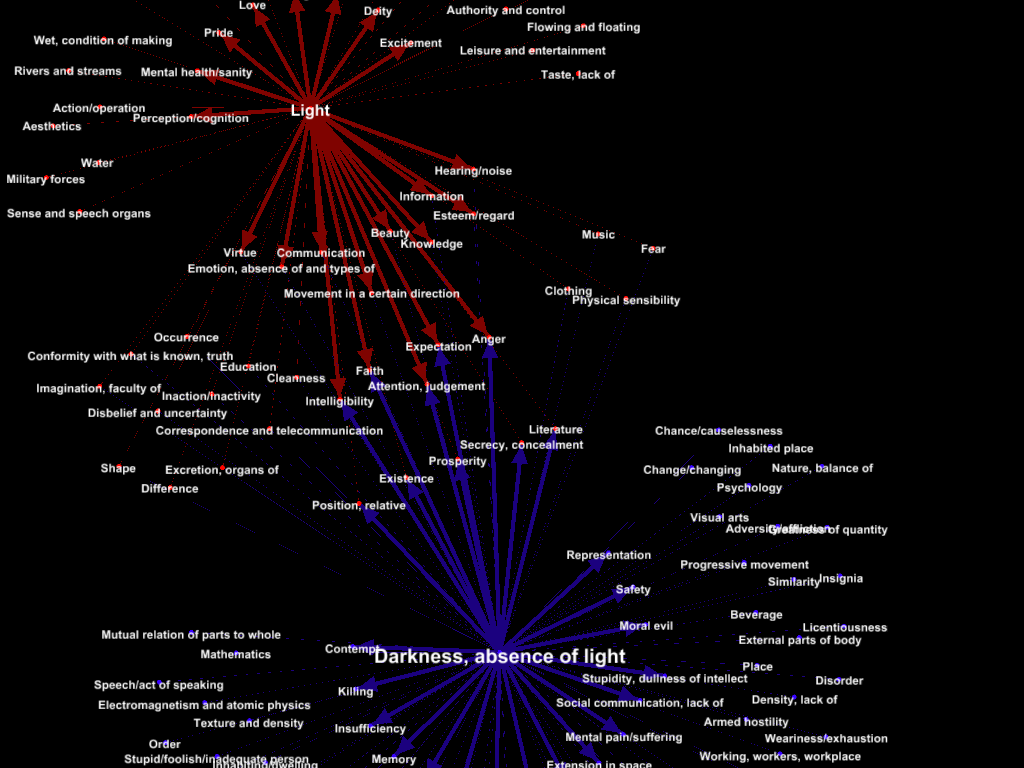
Below is a very early (in the project) example of a visualisation of the semantic domains of ‘Light’ and ‘Darkness, absence of light’, showing their metaphorical links with other semantic areas in the Historical Thesaurus data. We produced this using the program Gephi, which allows links between nodes to be shown using different colours, thickness of lines, etc.
From the project description at University of Glasgow, School of Critical Studies:
Over the past 30 years, it has become clear that metaphor is not simply a literary phenomenon; metaphorical thinking underlies the way we make sense of the world conceptually. When we talk about ‘a healthy economy’ or ‘a clear argument’ we are using expressions that imply the mapping of one domain of experience (e.g. medicine, sight) onto another (e.g. finance, perception). When we describe an argument in terms of warfare or destruction (‘he demolished my case’), we may be saying something about the society we live in. The study of metaphor is therefore of vital interest to scholars in many fields, including linguists and psychologists, as well as to scholars of literature.
Key questions about metaphor remain to be answered; for example, how did metaphors arise? Which domains of experience are most prominent in metaphorical expressions? How have the metaphors available in English developed over the centuries in response to social changes? With the completion of the Historical Thesaurus, published as the Historical Thesaurus of the Oxford English Dictionary by OUP (Kay, Roberts, Samuels, Wotherspoon eds, 2009), we can begin to address these questions comprehensively and in detail for the first time. We now have the opportunity to track how metaphorical ways of thinking and expressing ourselves have changed over more than a millennium.
Almost half a century in the making, the Historical Thesaurus is the first source in the world to offer a comprehensive semantic classification of the words forming the written record of a language. In the case of English, this record covers thirteen centuries of change and development, in metaphor as in other areas. We will use the Historical Thesaurus evidence base to investigate how the language of one domain of experience (e.g. medicine) contributes to others (e.g. finance). As we proceed, we will be able to see innovations in metaphorical thinking at particular periods or in particular areas of experience, such as the Renaissance, the scientific revolution, and the early days of psychoanalysis.
To achieve our goals, we will devise tools for the analysis of metaphor historically, beginning with a systematic identification of instances where words extend their meanings from one domain into another. An annotated ‘Metaphor Map’, which will be freely available online, will allow us to demonstrate when and how significant shifts in meaning took place. On the basis of this evidence, the team will produce series of case studies and a book examining key domains of metaphorical meaning.
Conference papers from the project.
What a wickedly topic map-like idea!