European Commission’s Low Attack on Open Source by Glyn Moody.
From the post:
If ACTA was the biggest global story of 2012, more locally there’s no doubt that the UK government’s consultation on open standards was the key event. As readers will remember, this was the final stage in a long-running saga with many twists and turns, mostly brought about by some uncricket-like behaviour by proprietary software companies who dread a truly level playing-field for government software procurement.
Justice prevailed in that particular battle, with open standards being defined as those with any claimed patents being made available on a royalty-free basis. But of course these things are never that simple. While the UK has seen the light, the EU has actually gone backwards on open standards in recent times.
Again, as long-suffering readers may recall, the original European Interoperability Framework also required royalty-free licensing, but what was doubtless a pretty intense wave of lobbying in Brussels overturned that, and EIF v2 ended up pushing FRAND, which effectively locks out open source – the whole point of the exercise.
Shamefully, some parts of the European Commission are still attacking open source, as I revealed a couple of months ago when Simon Phipps spotted a strange little conference with the giveaway title of “Implementing FRAND standards in Open Source: Business as usual or mission impossible?”
The plan was pretty transparent: organise something in the shadows, so that the open source world would be caught hopping. The fact that I only heard about it a few weeks beforehand, when I spend most of my waking hours scouting out information on the open source world, open standards and Europe, reading thousands of posts and tweets a week, shows how quiet the Commission kept about this.
This secrecy allowed the organisers to cherry pick participants to tilt the discussion in favour of software patents in Europe (which shouldn’t even exist, of course, according to the European Patent Convention), FRAND supporters and proprietary software companies, even though the latter are overwhelmingly American (so much for loyalty to the European ideal.) The plan was clearly to produce the desired result that open source was perfectly compatible with FRAND, because enough people at this conference said so.
But the “EU” hasn’t “gone backwards” on open standards. Organizations, as juridical entities, can’t go backwards or forwards on any topic. Officers, members, representatives of organizations, that is a different matter.
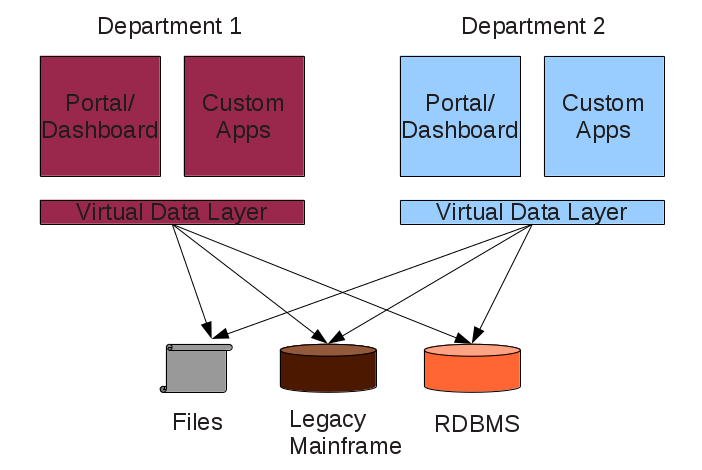
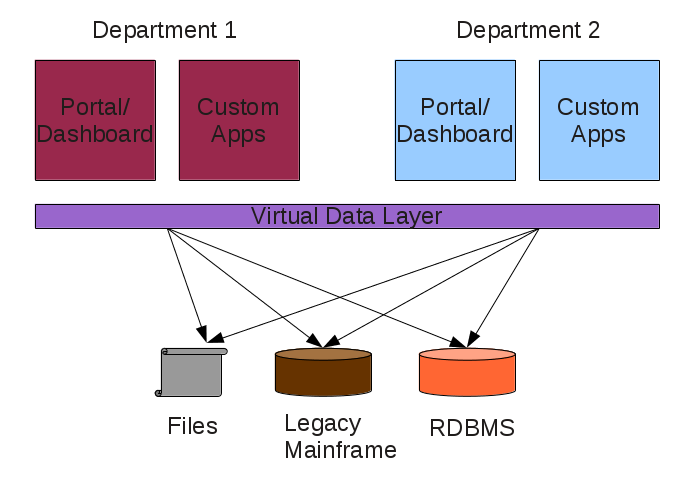
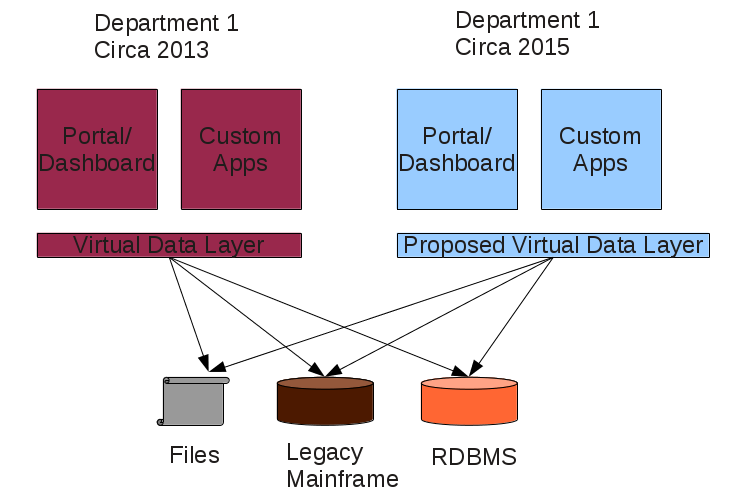
That is where topic maps could help bring transparency to a process such as the opposition to open source software.
For example, it is not:
- “some parts of the European Commission” but named individuals with photographs and locations
- “the organizers” but named individuals with specified relationships to commercial software vendors
- “enough people at this conference” but paid representatives of software vendors and others financially interested in a no open source outcome
TM’s can help tear aware the governmental and corporate veil over these “consultations.”
What you will find are people who are profiting or intend to do so from their opposition to open source software.
Their choice, but they should be forced to declare their allegiance to seek personal profit over public good.
I first saw this at: EU Experiences Setback in Open Source.