Did EMC Just Say Fork You To The Hadoop Community? by Shaun Connolly.
I need to quote Shaun for context before I explain why my answer is no.
All in on Hadoop?
Glancing at the Pivotal HD diagram in the GigaOM article, they’ve made it easy to distinguish the EMC proprietary components in Blue from the Apache Hadoop-related components in Green. And based on what Scott Yara says “We literally have over 300 engineers working on our Hadoop platform”.
Wow, that’s a lot of engineers focusing on Hadoop! Since Scott Yara admitted that “We’re all in on Hadoop, period.”, a large number of those engineers must be working on the open source Apache Hadoop-related projects labeled in Green in the diagram, right?
So a simple question is worth asking: How many of those 300 engineers are actually committers* to the open source projects Apache Hadoop, Apache Hive, Apache Pig, and Apache HBase?
John Furrier actually asked this question on Twitter and got a reply from Donald Miner from the Greenplum team. The thread is as follows:
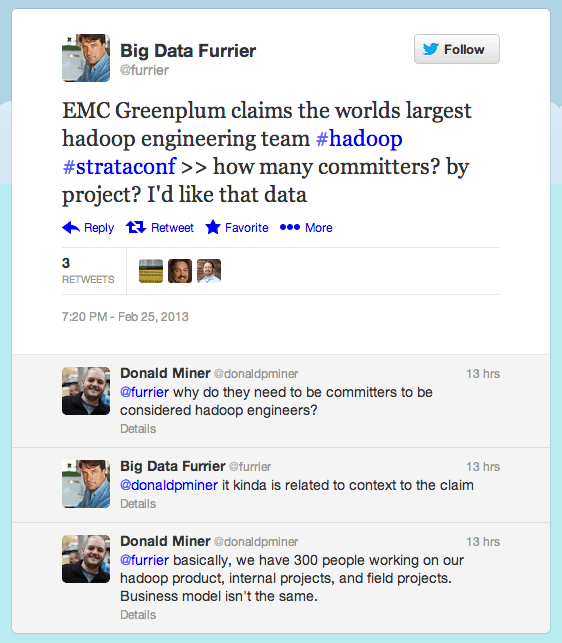
Since I agree with John Furrier that understanding the number of committers is kinda related to the context of Scott Yara’s claim, I did a quick scan through the committers pages for Hadoop, Hive, Pig and HBase to seek out the large number of EMC engineers spending their time improving these open source projects. Hmmm….my quick scan yielded a curious absence of EMC engineers directly contributing to these Apache projects. Oh well, I guess the vast majority of those 300 engineers are working on the EMC proprietary technology in the blue boxes.
Why Do Committers Matter?
Simply put: Just because you can read Moby-Dick doesn’t make you talented enough to have authored it.
Committers matter because they are the talented authors who devote their time and energy on working within the Apache Software Foundation community adding features, fixing bugs, and reviewing and approving changes submitted by the other committers. At Hortonworks, we have over 50 committers, across the various Hadoop-related projects, authoring code and working with the community to make their projects better.
This is simply how the community-driven open source model works. And believe it or not, you actually have to be in the community before you can claim you are leading the community and authoring the code!
So when EMC says they are “all-in on Hadoop” but have nary a committer in sight, then that must mean they are “all-in for harvesting the work done by others in the Hadoop community”. Kind of a neat marketing trick, don’t you think?
Scott Yara effectively says that it would take about $50 to $100 million dollars and 300 engineers to do what they’ve done. Sounds expensive, hard, and untouchable doesn’t it? Well, let’s take a close look at the Apache Hadoop community in comparison. Over the lifetime of just the Apache Hadoop project, there have been over 1200 people across more than 80 different companies or entities who have contributed code to Hadoop. Mr. Yara, I’ll see your 300 and raise you a community!
I say no because I remember another Apache project, the Apache webserver.
At last count, the Apache webserver has 63% of the market. The nearest competitor is Microsoft-IIS with 16.6%. Microsoft is in the Hadoop fold thanks to Hortonworks. Assuming Nginx to be the equivalent of Cloudera, there is another 15% of the market. (From Usage of web servers for websites)
If my math is right, that’s approximately 95% of the market.*
The longer EMC remains in self-imposed exile, the more its “Hadoop improvements” will drift from the mainstream releases.
So, my answer is: No, EMC has announced they are forking themselves.
That will carry reward enough without the Hadoop community fretting over much about it.
* Yes, the market share is speculation on my part but has more basis in reality than Mandiant’s claims about Chinese hackers.