Using machine learning algorithms, Pig and Python – Part 1 by Ofer Mendelevitch.
From the post:
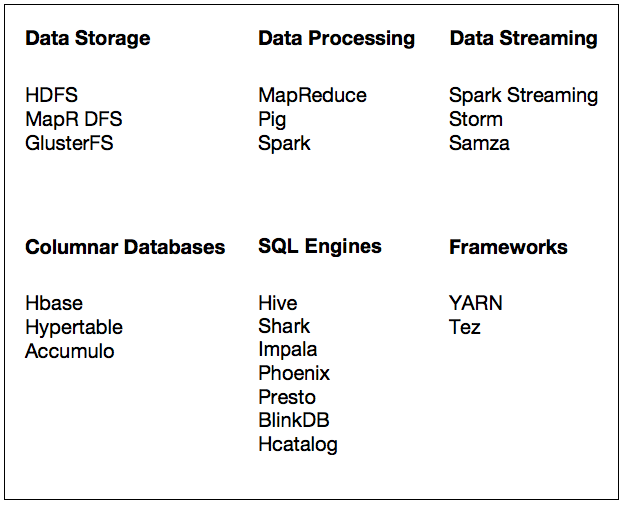
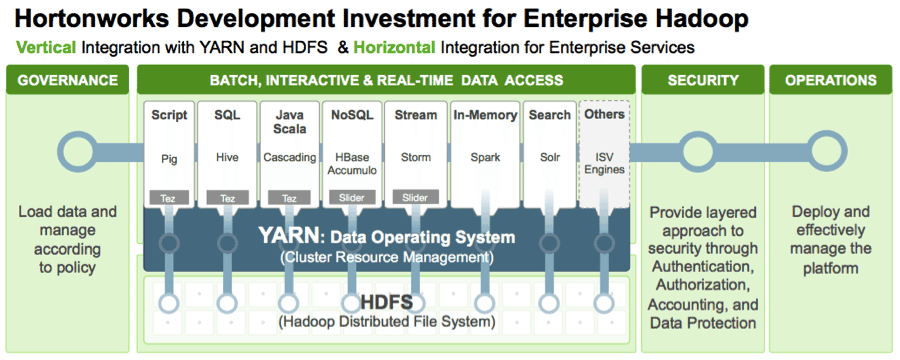
With the rapid adoption of Apache Hadoop, enterprises use machine learning as a key technology to extract tangible business value from their massive data assets. This derivation of business value is possible because Apache Hadoop YARN as the architectural center of Modern Data Architecture (MDA) allows purpose-built data engines such as Apache Tez and Apache Spark to process and iterate over multiple datasets for data science techniques within the same cluster.
It is a common misconception that the way data scientists apply predictive learning algorithms like Linear Regression, Random Forest or Neural Networks to large datasets requires a dramatic change in approach, in tooling, or in usage of siloed clusters. Not so: no dramatic change; no dedicated clusters; using existing modeling tools will suffice.
In fact, the big change is in what is known as “feature engineering”—the process by which very large raw data is transformed into a “feature matrix.” Enabled by Apache Hadoop with YARN as an ideal platform, this transformation of large raw datasets (terabytes or petabytes) into a feature matrix is now scalable and not limited by RAM or compute power of a single node.
Since the output of the feature engineering step (the “feature matrix”) tends to be relatively small in size (typically in the MB or GB scale), a common choice is to run the learning algorithm on a single machine (often with multiple cores and high amount of RAM), allowing us to utilize a plethora of existing robust tools and algorithms from R packages, Python’s Scikit-learn, or SAS.
In this multi-part blog post and its accompanying IPython Notebook, we will demonstrate an example step-by-step solution to a supervised learning problem. We will show how to solve this problem with various tools and libraries and how they integrate with Hadoop. In part I we focus on Apache PIG, Python, and Scikit-learn, while in subsequent parts, we will explore and examine other alternatives such as R or Spark/ML-Lib
…
With the IPython notebook, this becomes a great example of how to provide potential users hands-on experience with a technology.
An example that Solr, for example, might well want to imitate.
PS: When I was traveling, a simpler way to predict flight delays was to just ping me for my travels plans. 😉 You?