Server-side clustering of geo-points on a map using Elasticsearch by Gianluca Ortelli.
From the post:
Plotting markers on a map is easy using the tooling that is readily available. However, what if you want to add a large number of markers to a map when building a search interface? The problem is that things start to clutter and it’s hard to view the results. The solution is to group results together into one marker. You can do that on the client using client-side scripting, but as the number of results grows, this might not be the best option from a performance perspective.
This blog post describes how to do server-side clustering of those markers, combining them into one marker (preferably with a counter indicating the number of grouped results). It provides a solution to the “too many markers” problem with an Elasticsearch facet.
The Problem
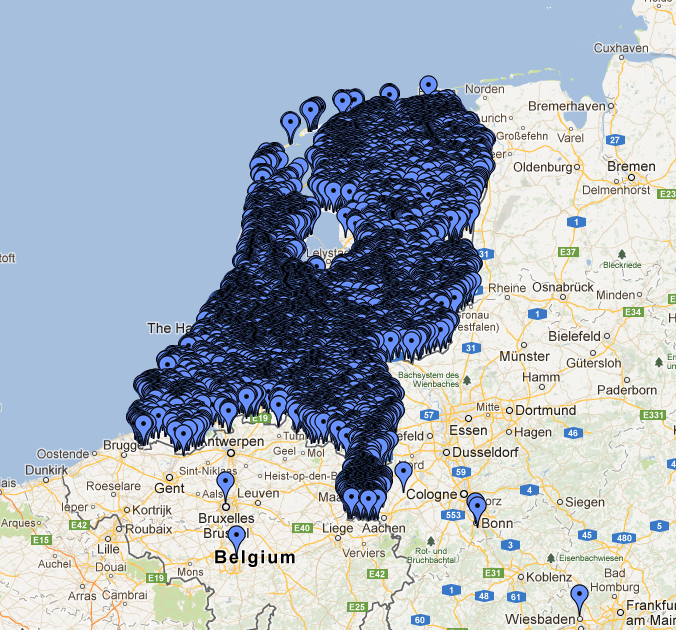
The image below renders quite well the problem we were facing in a project:
The mass of markers is so dense that it replicates the shape of the Netherlands! These items represent monuments and other things of general interest in the Netherlands; for an application we developed for a customer we need to manage about 200,000 of them and they are especially concentrated in the cities, as you can see in this case in Amsterdam: The “draw everything” strategy doesn’t help much here.
Server-side clustering of geo-points will be useful for representing dense geo-points.
Such as an Interactive Surveillance Map.
Or if you were building a map of police and security force sightings over multiple days to build up a pattern database.