I find find the following statement troubling. See if you can see what’s missing from:
In terms of research, the area may be studied from two rather distinct and complementary points of view: a computer-centered one and a human-centered one. In the computer-centered view, IR consists mainly of building up efficient indexes, processing user queries with high performance, and developing ranking algorithms to improve the results. In the human-centered view, IR consists mainly of studying the behavior of the user, understanding their main needs, and of determining how such understanding affects the organization and operation of the retrieval system. In this book, we focus mainly on the computer-centered view of IR, which is dominant in academia and in the market place. (page 1, Modern Information Retrieval, 2nd ed., Ricardo Baeza-Yates and Berthier Ribeiro-Neto, Pearson 2011)
I am not challenging the accuracy of the statement. Although I might explain some of it differently from the authors.
The terminology by which computer-centered IR is described is one clue: “….efficient…, ….high performance, ….improve the results.” That is computer-centered IR is mostly concerned with measurable results. Things to which we can put numbers and rank one as higher than others. Nothing wrong with that. Personally I have a great deal of interest in such approaches.
Human-centered IR is said: “….behavior…, ….needs, ….understanding….organization and operation….” Human-centered IR is mostly concerned with how users perform IR. Not as measurable but just as important as computer-centered IR. The authors point out, computer-centered IR dominates in academia and in the market place. I suspect because what can be easily measured is more attractive.
Do you notice something missing yet?
I thought it was quite remarkable that semantics weren’t mentioned. That is whatever computer or human centered approaches you take, the efficacy of those are going to vary by the semantics of the language on which IR is being performed. If that seems like an odd claim, consider the utility of an IR system that does not properly sort European much less Asian words, whether written in their scripts or transliteration.
True enough, we can make an IR system that is very fast that simply ignores the correct sort orders for such languages and in the past have taught readers of such languages to accept what the IR system was providing. So the behavior of the users was adapted to the systems. Human-centered I suppose but not the way I usually think about it.
And, after all, semantics are the reason we want to do IR in the first place. If the contents we were searching had no semantics, it is very unlikely we would want to search them at all. No matter now efficient or well organized a system might be.
My real concern is that semantics are being assumed as a matter of course. We all “know” the semantics. Hardly worth discussing. But that is why search results so seldom meet our expectations. We didn’t discuss the semantics up front. Everyone from system architect, programmer, UI designer, content author, all the way to and including the searcher, “knew” the semantics.
Trouble is, the semantics they “know,” are often different.
Of course the authors are free to include or exclude any content they wish and to fully cover semantic issues in general, would require a volume at least as long as this one. (A little over 900 pages with the index.)
I would start with something like:
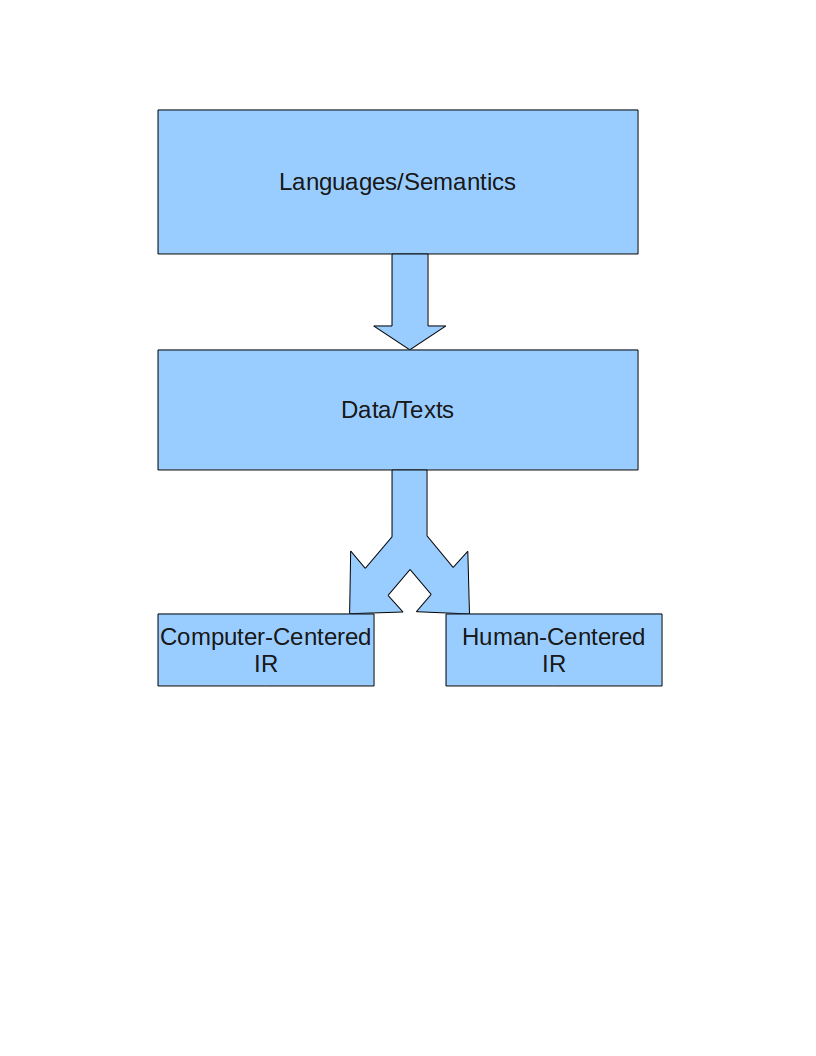
to make the point that we always start with languages and semantics and that data/texts are recorded in systems using languages and semantics. Our data structures are not neutral bystanders. They determine as much of what we can find as they determine the how we will interpret it.
Try running a modern genealogy for someone and when you find an arrest record for being a war criminal or child molester of a close relative, see if the family wants that included. Suddenly that will be more important that other prizes or honors they have won. Still the same person but the label on the data, arrest record, makes us suspect the worse. Had it read: “False Arrests, a record of false charges during the regime of XXX,” we are likely to react differently.
I am going to use Baeza-Yates and Ribeiro-Neto as one of the required texts in the next topic maps class. So we can cover some of the mining techniques that will help populate topic maps.
But I will also cover the issue of languages/semantics as well as data/texts (in how they are stored and the semantics of the same).
Does anyone have a favorite single volume on languages/semantics. I would lean towards Doing What Comes Naturally by Stanley Fish but I am sure there are other volumes equally as good.
The data/text formats an their semantics is likely to be harder to come by. I don’t know of anything off hand that is focused on that in monograph length treatment. Suggestions?
PS: I know I got the image wrong but I am about to post. I will post a slightly amended image tomorrow when I have thought about it some more.
Don’t let that deter you from posting criticisms of the current image in the meantime.
