FAU Neuroscientists Receive Patent for New 5D Method to Understand Big Data
From the news release:
Florida Atlantic University received a U.S. patent for a new method to display large amounts of data in a color-coded, easy-to-read graph. Neuroscientists Emmanuelle Tognoli, Ph.D., and Scott Kelso, Ph.D., both researchers at the Center for Complex Systems and Brain Sciences at FAU, originally designed the method to interpret enormous amounts of data derived from their research on the human brain. The method, called a five dimensional (5D) colorimetric technique, is able to graph spatiotemporal data (data that includes both space and time), which has not previously been achieved. Until now, spatiotemporal problems were analyzed either from a spatial perspective (for instance, a map of gas prices in July 2013), or from a time-based approach (evolution of gas prices in one county over time), but not simultaneously from both perspectives. Without both space and time, analysts have been faced with an incomplete picture until now, with the creation of the 5D colorimetric technique.
…
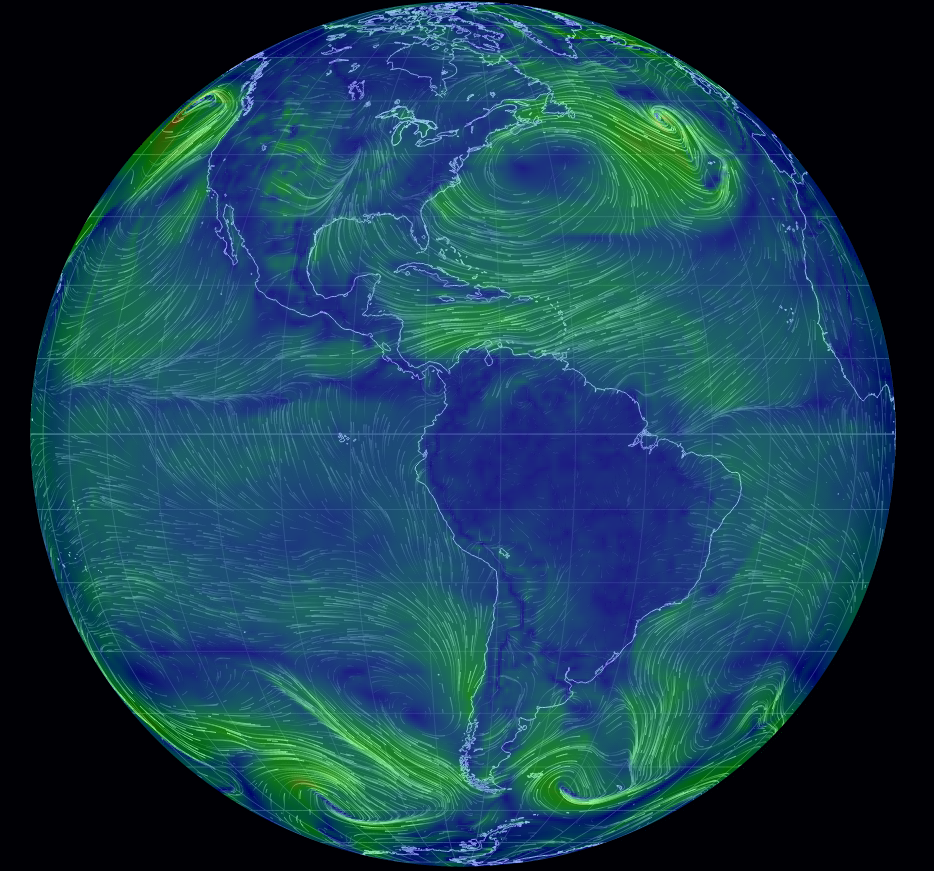
The new method has already been used to examine climatic records of sea surface temperature at 65,000 points around the world over a period of 28 years and provided scientists with a clear understanding of when and where temperature fluctuations occur. While the possibilities are endless, a few practical examples of use for the 5D colorimetric technique could include tracking gas prices per county, analyzing foreclosure rates in different states or tracking epidemiological data for a virus.
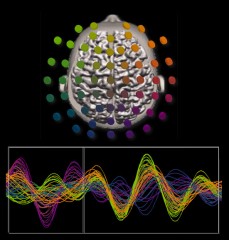
Tognoli and Kelso’s research involves tracking neural activity from different areas of the human brain every one thousandth of a second. This creates a massive amount of data that is not easy to understand using conventional methods.
“Using the 5D colorimetric technique, these huge datasets are transformed into a series of color-coded dynamic patterns that actually reveal the neural choreography completely,” said Kelso. Combining this new method with conceptual and theoretical tools in real experiments will help us and others elucidate the basic coordination dynamics of the human brain.”
…
A new visualization technique for big data.
Interesting that we experience multiple dimensions of data embedded in a constant stream of time and space, yet have no difficulty interacting with it and others embedded in the same context.
When we have to teach our benighted servants (computers) to display what we intuitively understand, difficulties ensue.
Just in case you are interested: System and method for analysis of spatio-temporal data, Patent #8,542,916.