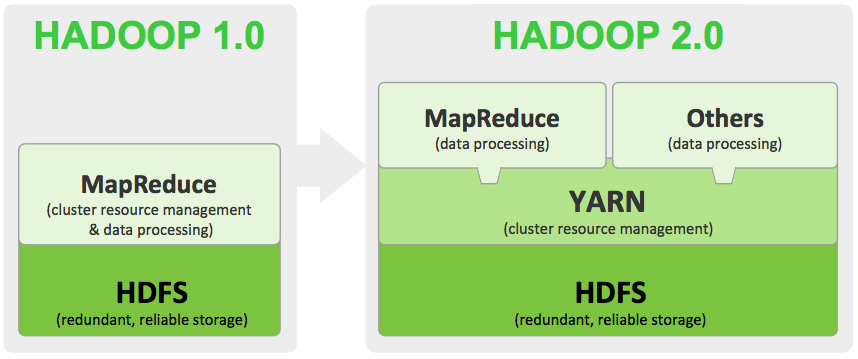
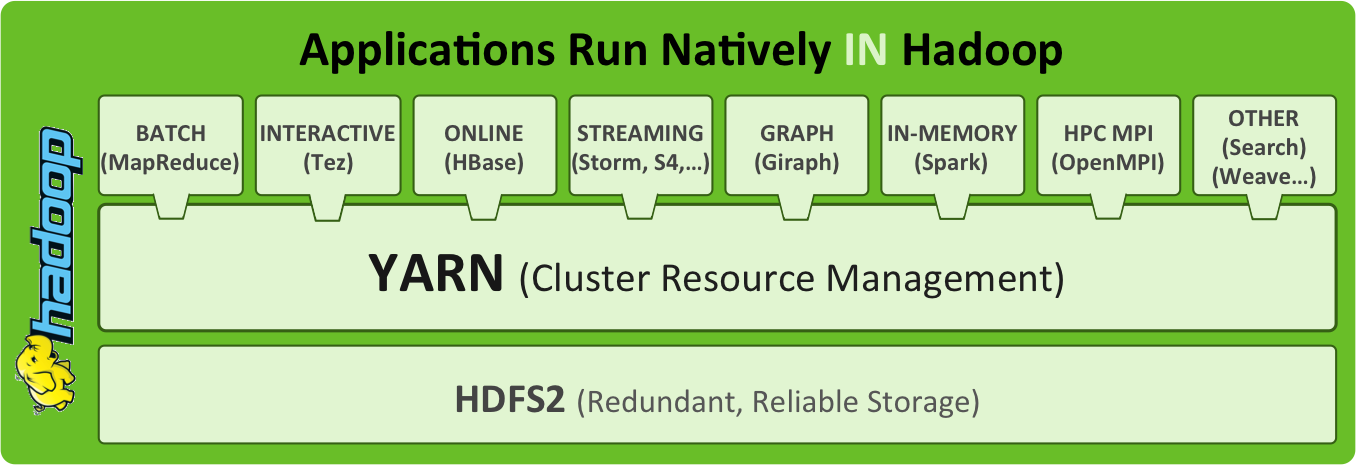
With the GA release of Hadoop 2, it seems appropriate to list a set of tutorials for the Hortonworks Sandbox.
Tutorial 1: Hello World – An Overview of Hadoop with HCatalog, Hive and Pig
Tutorial 2: How To Process Data with Apache Pig
Tutorial 3: How to Process Data with Apache Hive
Tutorial 4: How to Use HCatalog, Pig & Hive Commands
Tutorial 5: How to Use Basic Pig Commands
Tutorial 6: How to Load Data for Hadoop into the Hortonworks Sandbox
Tutorial 7: How to Install and Configure the Hortonworks ODBC driver on Windows 7
Tutorial 8: How to Use Excel 2013 to Access Hadoop Data
Tutorial 9: How to Use Excel 2013 to Analyze Hadoop Data
Tutorial 10: How to Visualize Website Clickstream Data
Tutorial 11: How to Install and Configure the Hortonworks ODBC driver on Mac OS X
Tutorial 12: How to Refine and Visualize Server Log Data
Tutorial 13: How To Refine and Visualize Sentiment Data
Tutorial 14: How To Analyze Machine and Sensor Data
By the time you finish these, I am sure there will be more tutorials or even proposed additions to the Hadoop stack!
(Updated December 3, 2013 to add #13 and #14.)