The Israeli algorithm criminalizing Palestinians for online dissent by Nadim Nashif and Marwa Fatafta.
From the post:
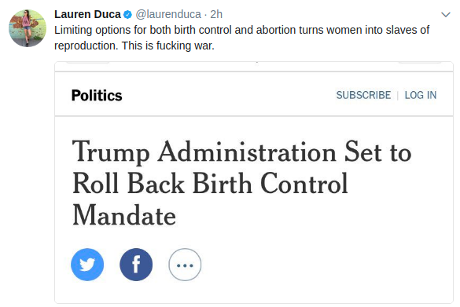
The Palestinian Authority’s (PA) arrest of West Bank human rights defender Issa Amro for a Facebook post last month is the latest in the the PA’s recent crackdown on online dissent among Palestinians. Yet it’s a tactic long used by Israel, which has been monitoring social media activity and arresting Palestinians for their speech for years – and has recently created a computer algorithm to aid in such oppression.
Since 2015, Israel has detained around 800 Palestinians because of content they wrote or shared online, mainly posts that are critical of Israel’s repressive policies or share the reality of Israeli violence against Palestinians. In the majority of these cases, those detained did not commit any attack; mere suspicion was enough for their arrest.
The poet Dareen Tatour, for instance, was arrested on October 2015 for publishing a poem about resistance to Israel’s 50-year-old military rule on her Facebook page. She spent time in jail and has been under house arrest for over a year and a half. Civil rights groups and individuals in Israel, the Occupied Palestinian Territory (OPT), and abroad have criticized Israel’s detention of Tatour and other Palestinian internet users as violations of civil and human rights.
Israeli officials have accused social media companies of hosting and facilitating what they claim is Palestinian incitement. The government has pressured these companies, most notably Facebook, to remove such content. Yet the Israeli government is mining this content. Israeli intelligence has developed a predictive policing system – a computer algorithm – that analyzes social media posts to identify Palestinian “suspects.”
…
One response to Israel’s predictive policing is to issue a joint statement: Predictive Policing Today: A Shared Statement of Civil Rights Concerns.
Another response, undertaken by Nadim Nashif and Marwa Fatafta, is to document the highly discriminatory and oppressive use of Israel’s predictive policing.
Both of those responses depend upon 1) the Israeli government agreeing it has acted wrongfully, and 2) the Israeli government in fact changing its behavior.
No particular reflection on the Israeli government but I don’t trust any government claiming, unverified, to have changed its behavior. How would you ever know for sure? Trusting any unverified answer from any government (read party) is a fool’s choice.
Discovering the Israeli algorithm for social media based arrests
What facts do we have about Israeli monitoring of social media?
- Identity of those arrested on basis of social media posts
- Content posted prior to their arrests
- Content posted by others who were not arrested
- Relationships with others, etc.
Think of the problem as being similar to breaking the Engima machine during WWII. We don’t have to duplicate the algorithm in use by Israel, we only have to duplicate it output. We have on hand some of the inputs and the outcomes of those inputs to start our research.
Moreover, as Israel uses social media monitoring, present guesses at the algorithm can be refined on the basis of more arrests.
Knowing Israeli’s social media algorithm is cold comfort to arrested Palestinians, but that knowledge can help prevent future arrests or make the cost of the method too high to be continued.
Social Media Noise Based on Israeli Social Media Algorithm
What makes predictive policing algorithms effective is their narrowing of the field of suspects to a manageable number. If instead of every male between the ages of 16 and 30 you have 20 suspects with scattered geographic locations, you can reduce the number of viable suspects fairly quickly.
But that depends upon being able to distinguish between all the males between the ages of 16 and 30. What if based on the discovered parallel algorithm to the Israeli predictive policing one, a group of 15,000 or 20,000 young men were “normalized” so they present the Israeli algorithm with the same profile?
If instead of 2 or 3 people who seem to be angry enough to commit violence, you have real and fake, 10,000 people right on the edge of extreme violence.
Judicious use of social media noise, informed by a parallel to the Israeli social media algorithm, could make the Israeli algorithm useless in practice. There would be too much noise for it to be effective. Or the resources required to eliminate the noise would be prohibitively expensive.
For predictive policing algorithms based on social media, “noise” is its Achilles heel.
PS: Actually defeating a predictive policing algorithm, to say nothing of generating noise on social media, isn’t a one man band sort of project. Experts in data mining, predictive algorithms, data analysis, social media plus support personnel. Perhaps a multi-university collaboration?
PPS: I don’t dislike the Israeli government any more or less than any other government. It was happenstance Israel was the focus of this particular article. I see the results of such research as applicable to all other governments and private entities (such as Facebook, Twitter).