XML Calabash version 1.0.25 by Norm Walsh.
New release of Calabash as of 10 February 2015.
Updated to support XML Inclusions (XInclude) Version 1.1, which was a last call working draft on 16 December 2014.
Time to update your XML toolkit again!
XML Calabash version 1.0.25 by Norm Walsh.
New release of Calabash as of 10 February 2015.
Updated to support XML Inclusions (XInclude) Version 1.1, which was a last call working draft on 16 December 2014.
Time to update your XML toolkit again!
Mercury Registration Deadline: February 17, 2015.
From the post:
The Intelligence Advanced Research Projects Activity (IARPA) will host a Proposers’ Day Conference for the Mercury Program on March 5, in anticipation of the release of a new solicitation in support of the program. The Conference will be held from 8:30 AM to 5:00 PM EST in the Washington, DC metropolitan area. The purpose of the conference will be to provide introductory information on Mercury and the research problems that the program aims to address, to respond to questions from potential proposers, and to provide a forum for potential proposers to present their capabilities and identify potential team partners.
Program Description and Goals
Past research has found that publicly available data can be used to accurately forecast events such as political crises and disease outbreaks. However, in many cases, relevant data are not available, have significant lag times, or lack accuracy. Little research has examined whether data from foreign Signals Intelligence (SIGINT) can be used to improve forecasting accuracy in these cases.
The Mercury Program seeks to develop methods for continuous, automated analysis of SIGINT in order to anticipate and/or detect political crises, disease outbreaks, terrorist activity, and military actions. Anticipated innovations include: development of empirically driven sociological models for population-level behavior change in anticipation of, and response to, these events; processing and analysis of streaming data that represent those population behavior changes; development of data extraction techniques that focus on volume, rather than depth, by identifying shallow features of streaming SIGINT data that correlate with events; and development of models to generate probabilistic forecasts of future events. Successful proposers will combine cutting-edge research with the ability to develop robust forecasting capabilities from SIGINT data.
Mercury will not fund research on U.S. events, or on the identification or movement of specific individuals, and will only leverage existing foreign SIGINT data for research purposes.
The Mercury Program will consist of both unclassified and classified research activities and expects to draw upon the strengths of academia and industry through collaborative teaming. It is anticipated that teams will be multidisciplinary, and might include social scientists, mathematicians, statisticians, computer scientists, content extraction experts, information theorists, and SIGINT subject matter experts with applied experience in the U.S. SIGINT System.
…
Attendees must register no later than 6:00 pm EST, February 27, 2015 at http://events.SignUp4.com/MercuryPDRegistration_March2015. Directions to the conference facility and other materials will be provided upon registration. No walk-in registrations will be allowed.
…
I might be interested if you can hide me under a third or fourth level sub-contractor. 😉
Seriously, it isn’t that I despair of the legitimate missions of intelligence agencies but I do despise waste on ways known to not work. Government funding, even unlimited funding, isn’t going to magically confer the correct semantics on data or enable analysts to meaningfully share their work products across domains.
You would think going on fourteen (14) years post-9/11 and not being one step closer to preventing a similar event, that would be a “wake-up” call to someone. If not in the U.S. intelligence community, perhaps in intelligence communities who tire of aping the U.S. community with no better results.
OpenGov Voices: Bringing transparency to earmarks buried in the budget by Matthew Heston, Madian Khabsa, Vrushank Vora, Ellery Wulczyn and Joe Walsh.
From the post:
Last week, President Obama kicked off the fiscal year 2016 budget cycle by unveiling his $3.99 trillion budget proposal. Congress has the next eight months to write the final version, leaving plenty of time for individual senators and representatives, state and local governments, corporate lobbyists, bureaucrats, citizens groups, think tanks and other political groups to prod and cajole for changes. The final bill will differ from Obama’s draft in major and minor ways, and it won’t always be clear how those changes came about. Congress will reveal many of its budget decisions after voting on the budget, if at all.
We spent this past summer with the Data Science for Social Good program trying to bring transparency to this process. We focused on earmarks – budget allocations to specific people, places or projects – because they are “the best known, most notorious, and most misunderstood aspect of the congressional budgetary process” — yet remain tedious and time-consuming to find. Our goal: to train computers to extract all the earmarks from the hundreds of pages of mind-numbing legalese and numbers found in each budget.
Watchdog groups such as Citizens Against Government Waste and Taxpayers for Common Sense have used armies of human readers to sift through budget documents, looking for earmarks. The White House Office of Management and Budget enlisted help from every federal department and agency, and the process still took three months. In comparison, our software is free and transparent and generates similar results in only 15 minutes. We used the software to construct the first publicly available database of earmarks that covers every year back to 1995.
Despite our success, we barely scratched the surface of the budget. Not only do earmarks comprise a small portion of federal spending but senators and representatives who want to hide the money they budget for friends and allies have several ways to do it:
I was checking the Sunlight Foundation Blog for any updated information on the soon to be released indexes of federal data holdings when I encountered this jewel on earmarks.
Important to read/support because:
Will transparency reduce earmarks? I rather doubt it because a sense of shame doesn’t seem to motivate elected and appointed officials.
What transparency can do is create a more level playing field for those who want to buy government access and benefits.
For example, if I knew what it cost to have the following exemption in the FOIA:
Exemption 9: Geological information on wells.
it might be possible to raise enough funds to purchase the deletion of:
Exemption 5: Information that concerns communications within or between agencies which are protected by legal privileges, that include but are not limited to:
4 Deliberative Process Privilege
Which is where some staffers hide their negotiations with former staffers as they prepare to exit the government.
I don’t know that matching what Big Oil paid for the geological information on wells exemption would be enough but it would set a baseline for what it takes to start the conversation.
I say “Big Oil paid…” assuming that most of us don’t equate matters of national security with geological information. Do you have another explanation for such an offbeat provision?
If government is (and I think it is) for sale, then let’s open up the bidding process.
A big win for open government: Sunlight gets U.S. to release indexes of federal data by Matthew Rumsey and Sean Vitka and John Wonderlich.
From the post:
For the first time, the United States government has agreed to release what we believe to be the largest index of government data in the world.
On Friday, the Sunlight Foundation received a letter from the Office of Management and Budget (OMB) outlining how they plan to comply with our FOIA request from December 2013 for agency Enterprise Data Inventories. EDIs are comprehensive lists of a federal agency’s information holdings, providing an unprecedented view into data held internally across the government. Our FOIA request was submitted 14 months ago.
These lists of the government’s data were not public, however, until now. More than a year after Sunlight’s FOIA request and with a lawsuit initiated by Sunlight about to be filed, we’re finally going to see what data the government holds.
…
Since 2013, federal agencies have been required to construct a list of all of their major data sets, subject only to a few exceptions detailed in President Obama’s executive order as well as some information exempted from disclosure under the FOIA.
…
Many kudos to the Sunlight Foundation!
As to using the word “win,” do we need to wait and see what Enterprise Data Inventories are in fact produced?
I say that because the executive order of President Obama that is cited in the post, provides these exemptions from disclosure:
4 (d) (d) Nothing in this order shall compel or authorize the disclosure of privileged information, law enforcement information, national security information, personal information, or information the disclosure of which is prohibited by law.
Will that be taken as an excuse to not list the data collections at all?
Or, will the NSA say:
one (1) collection of telephone metadata, timeSpan: 4 (d) exempt, size: 4 (d) exempt, metadataStructure: 4 (d) exempt source: 4 (d) exempt
Do they mean internal NSA phone logs? Do they mean some other source?
Or will they simply not list telephone metadata at all?
What’s exempt under FOAI? (From FOIA.gov):
Not all records can be released under the FOIA. Congress established certain categories of information that are not required to be released in response to a FOIA request because release would be harmful to governmental or private interests. These categories are called "exemptions" from disclosures. Still, even if an exemption applies, agencies may use their discretion to release information when there is no foreseeable harm in doing so and disclosure is not otherwise prohibited by law. There are nine categories of exempt information and each is described below.
Exemption 1: Information that is classified to protect national security. The material must be properly classified under an Executive Order.
Exemption 2: Information related solely to the internal personnel rules and practices of an agency.
Exemption 3: Information that is prohibited from disclosure by another federal law. Additional resources on the use of Exemption 3 can be found on the Department of Justice FOIA Resources page.
Exemption 4: Information that concerns business trade secrets or other confidential commercial or financial information.
Exemption 5: Information that concerns communications within or between agencies which are protected by legal privileges, that include but are not limited to:
- Attorney-Work Product Privilege
- Attorney-Client Privilege
- Deliberative Process Privilege
- Presidential Communications Privilege
Exemption 6: Information that, if disclosed, would invade another individual’s personal privacy.
Exemption 7: Information compiled for law enforcement purposes if one of the following harms would occur. Law enforcement information is exempt if it:
- 7(A). Could reasonably be expected to interfere with enforcement proceedings
- 7(B). Would deprive a person of a right to a fair trial or an impartial adjudication
- 7(C). Could reasonably be expected to constitute an unwarranted invasion of personal privacy
- 7(D). Could reasonably be expected to disclose the identity of a confidential source
- 7(E). Would disclose techniques and procedures for law enforcement investigations or prosecutions
- 7(F). Could reasonably be expected to endanger the life or physical safety of any individual
Exemption 8: Information that concerns the supervision of financial institutions.
Exemption 9: Geological information on wells.
And the exclusions:
Congress has provided special protection in the FOIA for three narrow categories of law enforcement and national security records. The provisions protecting those records are known as “exclusions.” The first exclusion protects the existence of an ongoing criminal law enforcement investigation when the subject of the investigation is unaware that it is pending and disclosure could reasonably be expected to interfere with enforcement proceedings. The second exclusion is limited to criminal law enforcement agencies and protects the existence of informant records when the informant’s status has not been officially confirmed. The third exclusion is limited to the Federal Bureau of Investigation and protects the existence of foreign intelligence or counterintelligence, or international terrorism records when the existence of such records is classified. Records falling within an exclusion are not subject to the requirements of the FOIA. So, when an office or agency responds to your request, it will limit its response to those records that are subject to the FOIA.
You can spot the truck sized holes as well as I can that may prevent disclosure.
One analytic challenge upon the release of the Enterprise Data Inventories will be to determine what is present and what is missing but should be present. Another will be to assist the Sunlight Foundation in its pursuit of additional FOIAs to obtain data listed but not available. Perhaps I should call this an important victory although of a battle and not the long term war for government transparency.
Thoughts?
From the webpage:
American FactFinder provides access to data about the United States, Puerto Rico and the Island Areas. The data in American FactFinder come from several censuses and surveys. For more information see Using FactFinder and What We Provide.
As I was writing this post I returned to CensusReporter (2013) which reported on an effort to make U.S. census data easier to use. Essentially a common toolkit.
At that time CensusReporter was in “beta” but has long passed that stage! Whether you will prefer American FactFinder or CensusReporter better will depend upon you and your requirements.
I can say that CensusReporter is working on A tool to aggregate American Community Survey data to non-census geographies. That could prove to be quite useful.
Enjoy!
Thank Snowden: Internet Industry Now Considers The Intelligence Community An Adversary, Not A Partner by Mike Masnick
From the post:
We already wrote about the information sharing efforts coming out of the White House cybersecurity summit at Stanford today. That’s supposedly the focus of the event. However, there’s a much bigger issue happening as well: and it’s the growing distrust between the tech industry and the intelligence community. As Bloomberg notes, the CEOs of Google, Yahoo and Facebook were all invited to join President Obama at the summit and all three declined. Apple’s CEO Tim Cook will be there, but he appears to be delivering a message to the intelligence and law enforcement communities, if they think they’re going to get him to drop the plan to encrypt iOS devices by default:
In an interview last month, Timothy D. Cook, Apple’s chief executive, said the N.S.A. “would have to cart us out in a box” before the company would provide the government a back door to its products. Apple recently began encrypting phones and tablets using a scheme that would force the government to go directly to the user for their information. And intelligence agencies are bracing for another wave of encryption.
Disclosure: I have been guilty of what I am about to criticize Mike Masnick about and will almost certainly be guilty of it in the future. That, however, does not make it right.
What would you say is being assumed in the Mike’s title?
Guesses anyone?
What if it read: U.S. Internet Industry Now Considers The U.S. Intelligence Community An Adversary, Not A Partner?
Does that help?
The trivial point is that the “Internet Industry” isn’t limited to the U.S. and Mike’s readership isn’t either.
More disturbing though is that the “U.S. (meant here descriptively) Internet Industry” at one point did consider the “U.S. (again descriptively) Intelligence Community” as a partner at one point.
That being the case and seeing how Mike duplicates that assumption in his title, how should countries besides the U.S. view the reliability (in terms of government access) of U.S. produced software?
That’s a simple enough question.
What is your answer?
The assumption of partnership between the “U.S. Internet Industry” and the “U.S. Intelligence Community” would have me running to back an alternative to China’s recent proposal for source code being delivered to the government (in that case China).
Rather than every country having different import requirements for software sales, why not require the public posting of commercial software source for software sales anywhere?
Posting of source code doesn’t lessen your rights to the code (see copyright statutes) and it makes detection of software piracy trivially easy since all commercial software has to post its source code.
Oh, some teenager might compile a copy but do you really think major corporations in any country are going to take that sort of risk? It just makes no sense.
As far as the “U.S. Intelligence Community” concerns, remember “The treacherous are ever distrustful…” The ill-intent of the world they see is a reflection of their own malice towards others. Or after years of systematic abuse, the smoldering anger of the abused.
In Defense of the Good Old-Fashioned Map – Sometimes, a piece of folded paper takes you to places the GPS can’t by Jason H. Harper.
A great testimonial to hard copy maps in addition to being a great read!
From the post:
…
But just like reading an actual, bound book or magazine versus an iPad or Kindle, you consume a real map differently. It’s easier to orient yourself on a big spread of paper, and your eye is drawn to roads and routes and green spaces you’d never notice on a small screen. A map invites time and care and observance of the details. It encourages the kind of exploration that happens in real life, when you’re out on the road, instead of the turn-by-turn rigidity of a digital device.
…
You can scroll or zoom with a digital map or digital representation of a topic map, but that isn’t quite the same as using a large, hard copy representation. Digital scrolling and zooming is like exploring a large scale world map through a toilet paper tube. It’s doable but I would argue it is a very different experience from a physical large scale world map.
Unless you are at a high-end visualization center or until we have walls as high resolution displays, you may want to think about production of topic maps as hard copy maps for some applications. While having maps printed isn’t cheap, it pales next to the intellectual effort that goes into constructing a useful topic map.
A physical representation of a topic map would have all the other advantages of a hard copy map. It would survive and be accessible without electrical power, it could be manually annotated, it could shared with others in the absence of computers, it could be compared to observations and/or resources, in fact it could be rather handy.
I don’t have a specific instance in mind but raise the point to keep in mind the range of topic map deliverables.
Principal Component Analysis – Explained Visually by Victor Powell.
From the website:
Principal component analysis (PCA) is a technique used to emphasize variation and bring out strong patterns in a dataset. It’s often used to make data easy to explore and visualize.
Another stunning visualization (2D, 3D and 17D, yes, not a typo, 17D) from Explained Visually.
Probably not the top item in your mind on Valentine’s Day but you should bookmark it and return when you have more time. 😉
I first saw this in a tweet by Mike Loukides.
An R Client for the Internet Archive API by Lincoln Mullen.
From the webpage:
In support of some of my research projects, I created a simple R package to access the Internet Archive’s API. The package is intended to search for items, to retrieve their metadata in a usable form, and to download the files associated with the items. The package, called internetarchive, is available on GitHub. The README and the vignette have a full explanation, but here is a brief overview.
This is cool!
And a great way to contrast NSA data collection with useful data collection.
If you were the NSA, you would suck down all the new Internet Archive content everyday. Then you would “explore” that plus lots of other content for “relationships.” Which abound in any data set that large.
If you are Lincoln Mullen or someone empowered by his work, you search for items and incrementally build a set of items with context and additional information you add to that set.
If you were paying the bill, which of those approaches seems the most likely to produce useful results?
Information/data/text mining doesn’t change in nature due to size or content or the purpose of the searching or whose paying the bill. The goal is useful (or should be) useful results for some purpose X.
I did manage to file seventeen (17) comments today on the XPath/XQuery/FO/XDM 3.1 drafts!
I haven’t mastered bugzilla well enough to create an HTML list of them to paste in here but no doubt will do so over the weekend.
Remember these are NOT “bugs” until they are accepted by the working group as “bugs.” Think of them as being suggestions on my part where the drafts were unclear or could be made clearer in my view.
Did you remember to post comments?
I will try to get a couple of short things posted tonight but getting the comments in was my priority today.

From a post by Dmitri Sotnikov
I saw a tweet from Anshum Gupta today saying:
Though the vote passed, seems like there’s need for another RC for #Apache #Lucene / #Solr 5.0. Hopefully we’d be third time lucky.
To brighten your weekend prospects, the Apache Solr Reference Guide for Solr 5.0 is available.
With an other Solr RC on the horizon, now would be a good time to spend some time with the reference guide. Both in terms of new features and to smooth out any infelicities in the documentation.
From the webpage:
An Apache Storm topology that will, by design, trigger failures at run-time.
The purpose of this bolt-of-death topology is to help testing Storm cluster stability. It was originally created to identify the issues surrounding the Storm defects described at STORM-329 and STORM-404.
This reminds me of PANIC! UNIX System Crash Dump Analysis Handbook by Chris Drake. Has it really been twenty (20) years since that came out?
If you need something a bit more up to date, Linux Kernel Crash Book: Everything you need to know by Igor Ljubuncic aka Dedoimedo, is available as both free and $ PDF files (to support the website).
Everyone needs a hobby, perhaps analyzing clusters and core dumps will be yours!
Enjoy!
I first saw storm-bolt-of-death in a tweet by Michael G. Noll.
Akin’s Laws of Spacecraft Design* by David Adkins.
I started to do some slight editing to make these laws of “software” design but if you can’t make that transposition for yourself, my doing isn’t going to help.
From the site of origin (unchanged):
1. Engineering is done with numbers. Analysis without numbers is only an opinion.
2. To design a spacecraft right takes an infinite amount of effort. This is why it’s a good idea to design them to operate when some things are wrong .
3. Design is an iterative process. The necessary number of iterations is one more than the number you have currently done. This is true at any point in time.
4. Your best design efforts will inevitably wind up being useless in the final design. Learn to live with the disappointment.
5. (Miller’s Law) Three points determine a curve.
6. (Mar’s Law) Everything is linear if plotted log-log with a fat magic marker.
7. At the start of any design effort, the person who most wants to be team leader is least likely to be capable of it.
8. In nature, the optimum is almost always in the middle somewhere. Distrust assertions that the optimum is at an extreme point.
9. Not having all the information you need is never a satisfactory excuse for not starting the analysis.
10. When in doubt, estimate. In an emergency, guess. But be sure to go back and clean up the mess when the real numbers come along.
11. Sometimes, the fastest way to get to the end is to throw everything out and start over.
12. There is never a single right solution. There are always multiple wrong ones, though.
13. Design is based on requirements. There’s no justification for designing something one bit "better" than the requirements dictate.
14. (Edison’s Law) "Better" is the enemy of "good".
15. (Shea’s Law) The ability to improve a design occurs primarily at the interfaces. This is also the prime location for screwing it up.
16. The previous people who did a similar analysis did not have a direct pipeline to the wisdom of the ages. There is therefore no reason to believe their analysis over yours. There is especially no reason to present their analysis as yours.
17. The fact that an analysis appears in print has no relationship to the likelihood of its being correct.
18. Past experience is excellent for providing a reality check. Too much reality can doom an otherwise worthwhile design, though.
19. The odds are greatly against you being immensely smarter than everyone else in the field. If your analysis says your terminal velocity is twice the speed of light, you may have invented warp drive, but the chances are a lot better that you’ve screwed up.
20. A bad design with a good presentation is doomed eventually. A good design with a bad presentation is doomed immediately.
21. (Larrabee’s Law) Half of everything you hear in a classroom is crap. Education is figuring out which half is which.
22. When in doubt, document. (Documentation requirements will reach a maximum shortly after the termination of a program.)
23. The schedule you develop will seem like a complete work of fiction up until the time your customer fires you for not meeting it.
24. It’s called a "Work Breakdown Structure" because the Work remaining will grow until you have a Breakdown, unless you enforce some Structure on it.
25. (Bowden’s Law) Following a testing failure, it’s always possible to refine the analysis to show that you really had negative margins all along.
26. (Montemerlo’s Law) Don’t do nuthin’ dumb.
27. (Varsi’s Law) Schedules only move in one direction.
28. (Ranger’s Law) There ain’t no such thing as a free launch.
29. (von Tiesenhausen’s Law of Program Management) To get an accurate estimate of final program requirements, multiply the initial time estimates by pi, and slide the decimal point on the cost estimates one place to the right.
30. (von Tiesenhausen’s Law of Engineering Design) If you want to have a maximum effect on the design of a new engineering system, learn to draw. Engineers always wind up designing the vehicle to look like the initial artist’s concept.
31. (Mo’s Law of Evolutionary Development) You can’t get to the moon by climbing successively taller trees.
32. (Atkin’s Law of Demonstrations) When the hardware is working perfectly, the really important visitors don’t show up.
33. (Patton’s Law of Program Planning) A good plan violently executed now is better than a perfect plan next week.
34. (Roosevelt’s Law of Task Planning) Do what you can, where you are, with what you have.
35. (de Saint-Exupery’s Law of Design) A designer knows that he has achieved perfection not when there is nothing left to add, but when there is nothing left to take away.
36. Any run-of-the-mill engineer can design something which is elegant. A good engineer designs systems to be efficient. A great engineer designs them to be effective.
37. (Henshaw’s Law) One key to success in a mission is establishing clear lines of blame.
38. Capabilities drive requirements, regardless of what the systems engineering textbooks say.
39. Any exploration program which "just happens" to include a new launch vehicle is, de facto, a launch vehicle program.
39. (alternate formulation) The three keys to keeping a new manned space program affordable and on schedule:
1) No new launch vehicles.
2) No new launch vehicles.
3) Whatever you do, don’t develop any new launch vehicles.40. (McBryan’s Law) You can’t make it better until you make it work.
41. Space is a completely unforgiving environment. If you screw up the engineering, somebody dies (and there’s no partial credit because most of the analysis was right…)
I left the original as promised for for software projects I would re-cast #1 to read:
1. Software Engineering is based on user feedback. Analysis without user feedback is fantasy (yours).
Enjoy!
I first saw this in a tweet by Neal Richter.
Digital Cartography [87] by Tiago Veloso.
Tiago has collected twenty-two (22) interactive maps that cover everything from “Why Measles May Just Be Getting Started | Bloomberg Visual Data” and “A History of New York City Basketball | NBA” (includes early stars as well) to “Map of 73 Years of Lynchings | The New York Times” and “House Vote 58 – Repeals Affordable Care Act | The New York Times.”
Sad to have come so far and yet not so far. Rather than a mob we have Congress, special interest groups and lobbyists. Rather than lynchings, everyone outside of the top 5% or so becomes poorer, less healthy, more stressed and more disposable. But we have a “free market” Shouting that at Galgotha would not have been much comfort.
The “news” from 8 December 2014 (that I missed) reports:
British History Online (BHO) is pleased to launch version 5.0 of its website. Work on the website redevelopment began in January 2014 and involved a total rebuild of the BHO database and a complete redesign of the site. We hope our readers will find the new site easier to use than ever before. New features include:
- A new search interface that allows you to narrow your search results by place, period, source type or subject.
- A new catalogue interface that allows you to see our entire catalogue at a glance, or to browse by place, period, source type or subject.
- Three subject guides on local history, parliamentary history and urban history. We are hoping to add more subject guides throughout the year. If you would like to contribute, contact us.
- Guidelines on using BHO, which include searching and browsing help, copyright and citation information, and a list of external resources that we hope will be useful to readers.
- A new about page that includes information about our team, past and present, as well as a history of where we have come from and where we want to go next.
- A new subscription interface (at last!) which includes three new levels of subscription in addition to the usual premium content subscription: gold subscription, which includes access to page scans and five- and ten-year long-term BHO subscriptions.
- Increased functionality to the maps interface, which are now fully zoomable and can even go full screen. We have also replaced the old map scans with high-quality versions.
- We also updated the site with a fresh, new look! We aimed for easy-to-read text, clear navigation, clean design and bright new images.
Version 5.0 has been a labour of love for the entire BHO team, but we have to give special thanks to Martin Steer, our tireless website manager who rebuilt the site from the ground up.
For over a decade, you have turned to BHO for reliable and accessible sources for the history of Britain and Ireland. We started off with 29 publications in 2003 and here is where we are now:
- 1.2 million page views per month
- 365,000 sessions per month
- 1,241 publications
- 108,227 text files
- 184,355 images
- 10,380 maps
We are very grateful to our users who make this kind of development possible. Your support allows BHO to always be growing and improving. 2014 has been a busy year for BHO and 2015 promises to be just as busy. Version 5.0 was a complete rebuild of BHO. We stripped the site down and began rebuilding from scratch. The goal of the new site is to make it as easy as possible for you to find materials relevant to your research. The new site was designed to be able to grow and expand easily, while always preserving the most important features of BHO. Read about our plans for 2015 and beyond.
We’d love to hear your feedback on our new site! If you want to stay up-to-date on what we are doing at BHO, follow us on Twitter.
Subscriptions are required for approximately 20% of the content, which enables the BHO to offer the other 80% for free.
A resource such as the BHO is a joyful reminder that not all projects sanctioned by government and its co-conspirators are venal and ill-intended.
For example, can you imagine a secondary school research paper on the Great Fire of 1666 that includes observations based on Leake’s Survey of the City After the Great Fire of 1666 Engraved By W. Hollar, 1667? With additional references from BHO materials?
I would have struck a Faustian bargain in high school had such materials been available!
That is just one treasure among many.
Teachers of English, history, humanities, etc., take note!
I first saw this in a tweet by Institute of Historical Research, U. of London.
Swati Khandelwal in China Demands Tech Companies to give them Backdoor and Encryption Keys misses a delicious irony she writes:
In May 2014, Chinese government announced that it will roll out a new set of regulations for IT hardware and software being sold to key industries in their country. China have repeatedly blamed U.S. products and criticize that U.S. products are itself threat to national security, as they may also contain NSA backdoors, among other things.
The New York Times article that she quotes, New Rules in China Upset Western Tech Companies by Paul Mozur, points out that:
The United States has made it virtually impossible for Huawei, a major Chinese maker of computer servers and cellphones, to sell its products in the United States, arguing that its equipment could have “back doors” for the Chinese government.
Which is more amazing?
I’m really hard pressed to choose between the two. Most of us have assumed for years (decades?) that binary software of any source was a security risk. Or as Mr. Weasley says to Ginny in Harry Potter and The Chamber of Secrets:
Never trust anything that can think for itself if you can’t see where it keeps its brain. (emphasis added)
Despite my doubt about artificial intelligence, software does perform actions without its users knowledge or permission and binary code makes it impossible for a user to discover those actions. What if an ftp client, upon successful authentication, uploads the same file to two separate locations? One chosen by the user and another in the background? The only notice the user has is of the visible upload and has no easy way to detect the additional upload. On *nix systems it would be easy to detect if the user knew what to look for but the vast majority of handlers of secure data aren’t on *nix systems.
The bottom line on binary files is: you can’t see where it keeps its brain.
At least China, reportedly, no source pointed to the new regulations or other documents, is going to require “backdoors” plus source code. Verifying a vendor installed “backdoor” should not be difficult but knowing whether there are other “backdoors,” requires the source code. So +1 to China for realizing that without source code, conforming software may have one (1) or more “backdoors.”
Swati Khandelwal goes on to quote a communication (no link for the source) from the U.S. Chamber of Commerce and others:
An overly broad, opaque, discriminatory approach to cybersecurity policy that restricts global internet and ICT products and services would ultimately isolate Chinese ICT firms from the global marketplace and weaken cybersecurity, thereby harming China’s economic growth and development and restricting customer choice
Sorry, that went by a little quickly, let’s try that again (repeat):
An overly broad, opaque, discriminatory approach to cybersecurity policy that restricts global internet and ICT products and services would ultimately isolate Chinese ICT firms from the global marketplace and weaken cybersecurity, thereby harming China’s economic growth and development and restricting customer choice
Even after the third or fourth reading, the U.S. Chamber of Commerce position reads like gibberish.
How requiring “backdoors” and source code is “discriminatory” isn’t clear. Vendors can sell their software with a Chinese “backdoor” built in worldwide. Just as they have done with software with United States “backdoors.”
I suppose there is some additional burden on vendors who have U.S. “backdoors” but not ones for China. But there is some cost to entering any market.
There is a solution that avoids “backdoors” for all, enables better enforcement of intellectual property rights, and results in a better global Internet and ICT products and services market.
The name of that solution is: Public Open Source.
Think about it for a minute. Public open source does not mean that you have a license to compile and run the code. It certainly doesn’t mean that you can sell the code. It does mean you can read the source code. As in create other products that work with that source code.
If a country were to require posting of source code for all products sold in that country, then detection of software piracy would be nearly trivial. The source code of all software products is posted for public searching and analysis. Vendors can run check-sums on software installations to verify that their software key was used to compile software. Software that doesn’t match the check-sum should be presumed to be pirated.
Posting source code for commercial software would enhance the IP protection of software, while at the same time making it possible to avoid U.S., Chinese or any other “backdoors” that may exist in binary software.
Summary:
China requiring public posting of source code results in these benefits:
What is there to not like about a public open source position for China?
PS: Public Open Source doesn’t answer China’s desire for software “backdoors.” I would urge China to pursue “backdoors” on a one-off basis to avoid the big data trap that now mires U.S. security agencies. The NSA has yet to identify a single terrorist from telephone records going back for years. If China has “backdoors” in all software/hardware, it will fall into the same trap.
If something happens and in hind sight a “backdoor” could have found it, the person who could have accessed the “backdoor” will be punished. Best defense, collect all the data from all the “backdoors” so we don’t miss anything.
If we delete any “backdoor” data and it turns out it was important, we will be punished. Best defense, let’s store all the “backdoor” data, forever.
Upon request we have to search the “backdoor” data, etc. You see where this is going. You will have so much data that the number of connections will overwhelm any information system and your ability to make use of the data.
A better solution has two parts. First, using the public open source, design your own “backdoors.” Vendors can’t betray you. Second, use “backdoors” only in cases of ongoing and focused investigations. Requiring current investigations means you will have contextual information to validate and coordinate with the data from “backdoors.”
China can spend its funds on supporting open source projects that create economic opportunity and growth or on bloated and largely ineffectual security apparatus collecting data from “backdoors.” I am confident it will choose wisely.
From the webpage:
The Vault is our new FOIA Library, containing 6,700 documents and other media that have been scanned from paper into digital copies so you can read them in the comfort of your home or office.
Included here are many new FBI files that have been released to the public but never added to this website; dozens of records previously posted on our site but removed as requests diminished; files from our previous FOIA Library, and new, previously unreleased files.
The Vault includes several new tools and resources for your convenience:
- Searching for Topics: You can browse or search for specific topics or persons (like Al Capone or Marilyn Monroe) by viewing our alphabetical listing, by using the search tool in the upper right of this site, or by checking the different category lists that can be found in the menu on the right side of this page. In the search results, click on the folder to see all of the files for that particular topic.
- Searching for Key Words: Thanks to new technology we have developed, you can now search for key words or phrases within some individual files. You can search across all of our electronic files by using the search tool in the upper right of this site, or you can search for key words within a specific document by typing in terms in the search box in the upper right hand of the file after it has been opened and loaded. Note: since many of the files include handwritten notes or are not always in optimal condition due to age, this search feature does not always work perfectly.
- Viewing the Files: We are now using an open source web document viewer, so you no longer need your own file software to view our records. When you click on a file, it loads in a reader that enables you to view one or two pages at a time, search for key words, shrink or enlarge the size of the text, use different scroll features, and more. In many cases, the quality and clarity of the individual files has also been improved.
- Requesting a Status Update: Use our new Check the Status of Your FOI/PA Request tool to determine where your request stands in our process. Status information is updated weekly. Note: You need your FOI/PA request number to use this feature.
Please note: the content of the files in the Vault encompasses all time periods of Bureau history and do not always reflect the current views, policies, and priorities of the FBI.
New files will be added on a regular basis, so please check back often.
This may be meant as a distraction but I don’t know from what?
I suppose there is some value in knowing that ineffectual law enforcement investigations did not begin with 9/11.
Darpa Is Developing a Search Engine for the Dark Web by Kim Zetter.
From the post:
A new search engine being developed by Darpa aims to shine a light on the dark web and uncover patterns and relationships in online data to help law enforcement and others track illegal activity.
The project, dubbed Memex, has been in the works for a year and is being developed by 17 different contractor teams who are working with the military’s Defense Advanced Research Projects Agency. Google and Bing, with search results influenced by popularity and ranking, are only able to capture approximately five percent of the internet. The goal of Memex is to build a better map of more internet content.
…
Reading how Darpa is build yet another bigger dirt pile, I was reminded of Rick Searle saying:
…
Rather than think of Big Data as somehow providing us with a picture of reality, “naturally emerging” as Mayer-Schönberger quoted above suggested we should start to view it as a way to easily and cheaply give us a metric for the potential validity of a hypothesis. And it’s not only the first step that continues to be guided by old fashioned science rather than computer driven numerology but the remaining steps as well, a positive signal followed up by actual scientist and other researchers doing such now rusting skills as actual experiments and building theories to explain their results. Big Data, if done right, won’t end up making science a form of information promising, but will instead be used as the primary tool for keeping scientist from going down a cul-de-sac.The same principle applied to mass surveillance means a return to old school human intelligence even if it now needs to be empowered by new digital tools. Rather than Big Data being used to hoover up and analyze all potential leads, espionage and counterterrorism should become more targeted and based on efforts to understand and penetrate threat groups themselves. The move back to human intelligence and towards more targeted surveillance rather than the mass data grab symbolized by Bluffdale may be a reality forced on the NSA et al by events. In part due to the Snowden revelations terrorist and criminal networks have already abandoned the non-secure public networks which the rest of us use. Mass surveillance has lost its raison d’etre.
…
In particular because the project is designed to automatically discover “relationships:”
…
But the creators of Memex don’t want just to index content on previously undiscovered sites. They also want to use automated methods to analyze that content in order to uncover hidden relationships that would be useful to law enforcement, the military, and even the private sector. The Memex project currently has eight partners involved in testing and deploying prototypes. White won’t say who the partners are but they plan to test the system around various subject areas or domains. The first domain they targeted were sites that appear to be involved in human trafficking. But the same technique could be applied to tracking Ebola outbreaks or “any domain where there is a flood of online content, where you’re not going to get it if you do queries one at a time and one link at a time,” he says.
…
I for one am very sure the new system (I refuse to sully the historical name by associating it with this doomed DARPA project), will find relationships, many relationships in fact. Too many relationships for any organization, now matter how large, to sort the relevant for the irrelevant.
If you want to segment the task, you could say that data mining is charged with finding relationships.
However, the next step is data analysis is to evaluate the evidence for the relationships found in the preceding step.
The step after evaluating the evidence for relationships discovered is to determine what, if anything, those relationships mean to some question at hand.
In all but the simplest of cases, there will be even more steps than the ones I listed. All of which must occur before you have extracted reliable intelligence from the data mining exercise.
Having data to search is a first step. Searching for and finding relationships in data is another step. But if that is where the search trail ends, you have just wasted another $10 to $20 million that could have gone for worthwhile intelligence gathering.
Cyrus Farivar writes in: FBI really doesn’t want anyone to know about “stingray” use by local cops:
If you’ve ever filed a public records request with your local police department to learn more about how cell-site simulators are used in your community—chances are good that the FBI knows about it. And the FBI will attempt to “prevent disclosure” of such information.
Not only can these devices, commonly known as “stingrays,” be used to determine a phone’s location, but they can also intercept calls and text messages. During the act of locating a phone, stingrays also sweep up information about nearby phones. Last fall, Ars reported on how a handful of cities across America are currently upgrading to new hardware that can target 4G LTE phones.
The newest revelation about the FBI comes from a June 2012 letter written by the law enforcement agency to the Minnesota Bureau of Criminal Apprehension. It was first acquired and published by the Minneapolis Star Tribune in December 2014—similar language likely exists between the FBI and other local authorities that use stingrays.
As the letter states:
In the event that the Minnesota Bureau of Criminal Apprehension receives a request pursuant to the Freedom of Information Act (5 USC 552) or an equivalent state or local law, the civil or criminal discovery process, or other judicial, legislative, or administrative process, to disclose information concerning the Harris Corporation [REDACTED] the Minnesota Bureau of Criminal Apprehension will immediately notify the FBI of any such request telephonically and in writing in order to allow sufficient time for the FBI to seek to prevent disclosure through appropriate channels.
While the FBI did not immediately respond to Ars’ request for comment, privacy activists were dismayed to see this language.
“It’s remarkable to see collusion by state and federal agencies to undermine public records requests, which are clearly aimed at keeping the public in the dark about the use of Stingray technology,” Hanni Fakhoury, a lawyer with the Electronic Frontier Foundation, told Ars. “After all, any truly sensitive law enforcement details could be redacted under traditional public records act law. But the notion that the federal government would work to actively block disclosure of records seems clearly to have a chilling effect on obtaining information about this controversial surveillance tool.”
…
Coming to the attention of the FBI is a honor that puts you in good company, Lucille Ball, Truman Capote, Charlie Chaplin, John Denver, Walt Disney, Rock Hudson, Whitney Houston, Steve Jobs, Hellen Keller, Martin Luther King, Marilyn Monroe, Jackie Robinson, Anna Nicole Smith, George Steinbrenner, just to name some of the honorees.
But Hanni Fakhoury points out, the meek and mild are unlikely to ask, even if it means better protecting their privacy and the privacy of others.
Freedom of Information requests are a rope-a-dope strategy that relies on the largesse of government agencies in releasing details of their own misdeeds. Not to lessen the importance of Freedom of Information act like requests, shouldn’t we be more proactive, that is to say preventative, in the protection of our privacy?
For example, you use your cellphone ever day but most likely transition between a limited number of cell towers. Which cell phone towers? You can check any of these three sources: CellMapper.net, MapMuse.com, CellReception.com. (All from: Cell Phone Tower Locations by Michael Kwan.)
If you know your usual cellphone towers and you bother to check before sending text messages, you can eek out a little more privacy.
For searching purposes you can use “stingray” if you want to be confused with lots of entries about marine life (it does look like an FBI agent and cars (one of my favorites). Otherwise, use IMSI-Catcher (the privacy invading device) and/or IMSI-Catcher Detector (the defensive side). The Android IMSI-Catcher Detector (#AIMSICD) is an example of one IMSI-Catcher-Detector and they have a great list of other projects in the same area (software and hardware).
If you are afraid of being noticed by the FBI, I’m not sure having software on your phone to detect their snooping is the best option for you. For the moderately bolder, have a look. Contribute to the projects if at all possible.
Detecting IMSI-Catchers on your own is a great first step, but that doesn’t increases everyone’s privacy, just your own. What if there was a more aggressive way to protect your cellphone privacy and the cellphone privacy of others?
I ask because in reading the documentation at #AIMSICD, I ran across OpenCellID.
From the OpenCellID wiki:
OpenCellID is the world’s largest collaborative community project that collects GPS positions of cell towers, used free of charge, for a multitude of commercial and private purposes.
More than 49,000 contributors have already registered with OpenCellID, contributing more than 1 million new measurements every day in average to the OpenCellID database. Detailed statistics are available in real time.
The OpenCellID project was primarily created to serve as a data source for GSM localisation.
As of Jan, 2015, the database contained almost 7 million unique GSM Cell IDs and 1.2 Billion measurements.OpenCellID provides 100% free Cell ID data (CC-BY-SA 3.0 license).
The OpenCellID database is published under a Creative Commons open content license with the intention of promoting free use and redistribution of the data.All data uploaded by any of the contributors can also be downloaded again free of charge – no exceptions!
So, any GPS reading for a cell tower that is NOT registered with the FCC and that DOES NOT appear in OpenCellID (at least in the United States), is either a criminal or some government agency (is there a difference these days?) trying to invade your privacy. Reasoning than unregistered and cell towers that “move,” aren’t public structures delivering cellphone service.
Agreed?
Rather than asking the government for invoices for purchases of IMSI-catcher software, why not create listening posts for IMSI-catchers and de-dupe that data against the known (legitimate) cell towers and contribute the legitimate data back to OpenCellID under the OpenCellID license?
For a fee (think $$$ in your local currency), you can text warnings to your subscribers about IMSI-catchers that have been detected in their area.
For example, I want to visit the U.S. District Court in Atlanta and while near the courthouse, I want to send private text messages to a client and/or an attorney. Today, can I do that safely?
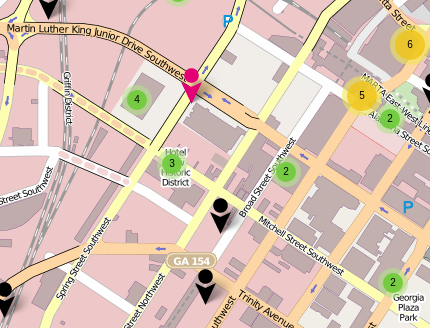
Judging from the map portion I have reproduced from OpenCellID, I would guess, remember, guess only, yes.
But that is a guess in the absent of any data on IMSI-catchers in the area.
How much would you pay to turn that “guess” into a fact?
For example, what if I had deployed sensitive IMSI-Catcher-Detectors in the area:

(Amazing what a handful of asphalt and a traffic cone can conceal in plain sight.)
With a grid of IMSI-Catcher-Detectors in place, I can answer your question about texting a client or attorney in the vicinty of the U.S. District Courthouse with a fact-based YES or NO! For a fee.
IMSI-Catcher-Detectors in temporary, permanent or semi-permanent locations, deduped against the OpenCellID database, enables the creation of commercially valuable data to sell in real time to cellphone users who value their privacy. Moreover, with enough coverage, the history of such data will provide insights simply not possible to obtain from purchase dates of IMSI-catchers by criminals (governmental and otherwise).
Monetizing the right to privacy isn’t the only way to defend it but it could hardly do worse than civil libertarians have done over the past couple of decades.
Yes?
PS: You do realize that with enough granularity of tracking that IMSI-catchers can be tracked in real time with inferred GPS locations? Just in case you want to say “hello” to anyone trying to intercept your communications. Think of it as an “Eaves-Dropper-Near-Me” app. Certainly an additional fee item.
Define and Process Data Pipelines in Hadoop with Apache Falcon
From the webpage:
Apache Falcon simplifies the configuration of data motion with: replication; lifecycle management; lineage and traceability. This provides data governance consistency across Hadoop components.
Scenario
In this tutorial we will walk through a scenario where email data lands hourly on a cluster. In our example:
- This cluster is the primary cluster located in the Oregon data center.
- Data arrives from all the West Coast production servers. The input data feeds are often late for up to 4 hrs.
The goal is to clean the raw data to remove sensitive information like credit card numbers and make it available to our marketing data science team for customer churn analysis.
To simulate this scenario, we have a pig script grabbing the freely available Enron emails from the internet and feeding it into the pipeline.
…
Not only a great tutorial on Falcon, this tutorial is a great example of writing a tuturial!
New agency to sniff out threats in cyberspace by Ellen Nakashima.
Don’t laugh!
From the post:
The Obama administration is establishing a new agency to combat the deepening threat from cyberattacks, and its mission will be to fuse intelligence from around the government when a crisis occurs.
The agency is modeled after the National Counterterrorism Center, which was launched in the wake of the Sept. 11, 2001, attacks amid criticism that the government failed to share intelligence that could have unraveled the al-Qaeda plot.
…
Others question why a new agency is needed when the government already has several dedicated to monitoring and analyzing cyberthreat data. The Department of Homeland Security, the FBI and the National Security Agency all have cyber-operations centers, and the FBI and the NSA are able to integrate information, noted Melissa Hathaway, a former White House cybersecurity coordinator and president of Hathaway Global Strategies.
…
Obama will issue a memorandum creating the center, which will be part of the Office of the Director of National Intelligence. The new agency will begin with a staff of about 50 and a budget of $35 million, officials said.
…
I said, “Don’t laugh!”
If the center gets created, if, it would be the logical place to locate intelligence integration. Not that I think that is what will happen but accidents do happen.
How that will diminish the turf wars between the agencies it is hard to say. Perhaps they will increase the budget for the center so it can spy on the other collectors of intelligence. Probably cheaper than asking them to share it.
CrowdFlower 2015 DATA SCIENTIST REPORT (local copy). If you want to give up your email, go here.
Survey of one hundred and fifty-three (that’s what more than 150 means) data scientists. Still, the results don’t vary much from those I have seen cited elsewhere.
A couple of interested tidbits:
66.7% say cleaning and organizing data is one of their two most time-consuming tasks
Yet when you read the report, how many data scientists say that creation of cleaner, more organized data would make their lives easier?
Survey says:
#1 “to acquire all necessary tools to effectively do the job” (cited by 54.3 percent of respondents)
#2 “set clearer goals and objectives on projects” (cited by 52.3 percent of respondents).
#3 “invest more in training and development to help team members continually grow their capabilities” (cited by 47.7 percent of respondents)
Someone may have asked about cleaner and better organized data but it didn’t make the reported survey results.
Amazing yes? Over sixty-six (66) percent of their time spent cleaning data and no voiced desire to create cleaner data.
Maybe it was just these one hundred and fifty-three data scientists or perhaps the survey instrument.
Making it possible to reduce the amount of time you spend on janitorial work with data would be a priority for me.
You?
Microsoft researchers say their newest deep learning system beats humans — and Google
Two stories for the price of one! Microsoft’s deep learning project beats human recognition on a data set and Microsoft is modest about it. 😉
From the post:
The Microsoft creation got a 4.94 percent error rate for the correct classification of images in the 2012 version of the widely recognized ImageNet data set , compared with a 5.1 percent error rate among humans, according to the paper. The challenge involved identifying objects in the images and then correctly selecting the most accurate categories for the images, out of 1,000 options. Categories included “hatchet,” “geyser,” and “microwave.”
…
[modesty]
“While our algorithm produces a superior result on this particular dataset, this does not indicate that machine vision outperforms human vision on object recognition in general,” they wrote. “On recognizing elementary object categories (i.e., common objects or concepts in daily lives) such as the Pascal VOC task, machines still have obvious errors in cases that are trivial for humans. Nevertheless, we believe that our results show the tremendous potential of machine algorithms to match human-level performance on visual recognition.”
You can grab the paper here.
Hoping that Microsoft sets a trend in reporting breakthroughs in big data and machine learning. Stating the achievement but also its limitations may lead to more accurate reporting of technical news. Not holding my breath but I am hopeful.
I first saw this in a tweet by GPUComputing.
Data as “First Class Citizens” by Łukasz Bolikowski, Nikos Houssos, Paolo Manghi, Jochen Schirrwagen.
The guest editorial to D-Lib Magazine, January/February 2015, Volume 21, Number 1/2, introduces a collection of articles focusing on data as “first class citizens,” saying:
Data are an essential element of the research process. Therefore, for the sake of transparency, verifiability and reproducibility of research, data need to become “first-class citizens” in scholarly communication. Researchers have to be able to publish, share, index, find, cite, and reuse research data sets.
The 2nd International Workshop on Linking and Contextualizing Publications and Datasets (LCPD 2014), held in conjunction with the Digital Libraries 2014 conference (DL 2014), took place in London on September 12th, 2014 and gathered a group of stakeholders interested in growing a global data publishing culture. The workshop started with invited talks from Prof. Andreas Rauber (Linking to and Citing Data in Non-Trivial Settings), Stefan Kramer (Linking research data and publications: a survey of the landscape in the social sciences), and Dr. Iain Hrynaszkiewicz (Data papers and their applications: Data Descriptors in Scientific Data). The discussion was then organized into four full-paper sessions, exploring orthogonal but still interwoven facets of current and future challenges for data publishing: “contextualizing and linking” (Semantic Enrichment and Search: A Case Study on Environmental Science Literature and A-posteriori Provenance-enabled Linking of Publications and Datasets via Crowdsourcing), “new forms of publishing” (A Framework Supporting the Shift From Traditional Digital Publications to Enhanced Publications and Science 2.0 Repositories: Time for a Change in Scholarly Communication), “dataset citation” (Data Citation Practices in the CRAWDAD Wireless Network Data Archive, A Methodology for Citing Linked Open Data Subsets, and Challenges in Matching Dataset Citation Strings to Datasets in Social Science) and “dataset peer-review” (Enabling Living Systematic Reviews and Clinical Guidelines through Semantic Technologies and Data without Peer: Examples of Data Peer Review in the Earth Sciences).
We believe these investigations provide a rich overview of current issues in the field, by proposing open problems, solutions, and future challenges. In short they confirm the urgent and fascinating demands of research data publishing.
The only stumbling point in this collection of essays is the notion of data as “First Class Citizens.” Not that I object to a catchy title but not all data is going to be equal when it comes to first class citizenship.
Take Semantic Enrichment and Search: A Case Study on Environmental Science Literature, for example. Great essay on using multiple sources to annotate entities once disambiguation had occurred. But some entities are going to have more annotations than others and some entities may not be recognized at all. Not to mention it is rather doubtful that the markup containing those entities was annotated at all?
Are we sure we want to exclude from data the formats that contain the data? Isn’t a format a form of data? As well as the instructions for processing that data? Perhaps not in every case but shouldn’t data and the formats that hold date be equally treated as first class citizens? I am mindful that hundreds of thousands of people saw the pyramids being built but we have not one accurate report on the process.
Will the lack of that one accurate report deny us access to data quite skillfully preserved in a format that is no longer accessible to us?
While I support the cry for all data to be “first class citizens,” I also support a very broad notion of data to avoid overlooking data that may be critical in the future.
Big Data as statistical masturbation by Rick Searle.
From the post:
It’s just possible that there is a looming crisis in yet another technological sector whose proponents have leaped too far ahead, and too soon, promising all kinds of things they are unable to deliver. It strange how we keep ramming our head into this same damned wall, but this next crisis is perhaps more important than deflated hype at other times, say our over optimism about the timeline for human space flight in the 1970’s, or the “AI winter” in the 1980’s, or the miracles that seemed just at our fingertips when we cracked the Human Genome while pulling riches out of the air during the dotcom boom- both of which brought us to a state of mania in the 1990’s and early 2000’s.
The thing that separates a potentially new crisis in the area of so-called “Big-Data” from these earlier ones is that, literally overnight, we have reconstructed much of our economy, national security infrastructure and in the process of eroding our ancient right privacy on it’s yet to be proven premises. Now, we are on the verge of changing not just the nature of the science upon which we all depend, but nearly every other field of human intellectual endeavor. And we’ve done and are doing this despite the fact that the the most over the top promises of Big Data are about as epistemologically grounded as divining the future by looking at goat entrails.
Well, that might be a little unfair. Big Data is helpful, but the question is helpful for what? A tool, as opposed to a supposedly magical talisman has its limits, and understanding those limits should lead not to our jettisoning the tool of large scale data based analysis, but what needs to be done to make these new capacities actually useful rather than, like all forms of divination, comforting us with the idea that we can know the future and thus somehow exert control over it, when in reality both our foresight and our powers are much more limited.
Start with the issue of the digital economy. One model underlies most of the major Internet giants- Google, FaceBook and to a lesser extent Apple and Amazon, along with a whole set of behemoths who few of us can name but that underlie everything we do online, especially data aggregators such as Axicom. That model is to essentially gather up every last digital record we leave behind, many of them gained in exchange for “free” services and using this living archive to target advertisements at us.
It’s not only that this model has provided the infrastructure for an unprecedented violation of privacy by the security state (more on which below) it’s that there’s no real evidence that it even works.
Ouch! I wonder if Searle means “works” as in satisfies a business goal or objective? Not just work in the sense it doesn’t crash?
That would go a long way to explain the failure of the original Semantic Web vision despite the investment of $billions in its promotion. With the lack of a “works” for some business goal or objective, who cares if it “works” in some other sense?
You need to read Serle in full but one more tidbit to tempt you into doing so:
…
Here’s the problem with this line of reasoning, a problem that I think is the same, and shares the same solution to the issue of mass surveillance by the NSA and other security agencies. It begins with this idea that “the landscape will become apparent and patterns will naturally emerge.”The flaw that this reasoning suffers has to do with the way very large data sets work. One would think that the fact that sampling millions of people, which we’re now able to do via ubiquitous monitoring, would offer enormous gains over the way we used to be confined to population samples of only a few thousand, yet this isn’t necessarily the case. The problem is the larger your sample size the greater your chance at false correlations.
…
Searle does cite Stefan Thurner, which we talked about in Newly Discovered Networks among Different Diseases…, who makes the case that any patterns you discover with big data are the starting point for research, not conclusions to be drawn from big data. Not the same thing.
PS: I do concede that Searle overlooks the non-healthy and incestuous masturbation among and between business management, management consultancies, vendors, and others with regard to big data. Quick or easy answers are never quick, easy, or even satisfying.
I first saw this in a post by Kirk Borne.
Statistics are a bloodless way to tell the story of a war but in the absence of territory to claim (or claim/reclaim as was the case in Vietnam) and lacking an independent press to document the war, there isn’t much else to report. But even the simple statistics are twisted.
In the “war” against ISIS (unauthorized, Obama soon to ask Congress for ISIS war authority), Nancy A. Youssef reports in U.S. Won’t Admit to Killing a Single Civilian in the ISIS War:
Five months and 1,800-plus strikes into the U.S. air campaign against ISIS, and not a single civilian has been killed, officially. But Pentagon officials concede that they really have no way of telling for sure who has died in their attacks‚—and admit that no one will ever know how many have been slain.
A free and independent press reported the My Lai Massacre, which was only one of the untold number of atrocities against civilians in Vietname. The current generation of “journalists” drink the military’s Kool-Aid with no effort to document the impact of its airstrikes. Instead of bemoaning the lack of independent reports, the media should be the origin of independent reports.
How do you square the sheepish admission from the Pentagon that they don’t know who had dies in their attacks with statements by the U.S. Ambassador to Iraq, Stuart Jones, claiming that 6,000 ISIS fighters and half their leadership has been killed?
That sounds administration top-heavy if one out of every two fighters is a leader. Inside the beltway in D.C. is the only known location with that ratio of “leaders” to “followers.” But realistically, if the Pentagon had those sort of numbers, they would be repeating them in every daily briefing. Yes? Unless you think Ambassador Jones has a crystal ball, the most likely case is those numbers are fictional.
I don’t doubt there have been civilian casualties. In war there are always civilian casualties. What troubles me is the don’t look, don’t tell position of the U.S. military command in order to make war palatable to a media savvy public.
War should be unpalatable. It should be presented in its full gory details, videos of troops bleeding out on the battlefield, burials, families torn apart, women, children and men killed in ways we don’t want to imagine, all of the aspects that make it unpalatable.
If nothing else, it will sharpen the debate on war powers in Congress because then the issue won’t be model towns and cars but people who are dying before our very eyes on social media. How many more lives will we take to save the Arab world from Arabs?
Reagent and laboratory contamination can critically impact sequence-based microbiome analyses by Susannah J Salter, et al. (BMC Biology 2014, 12:87 doi:10.1186/s12915-014-0087-z)
Abstract:
Background
The study of microbial communities has been revolutionised in recent years by the widespread adoption of culture independent analytical techniques such as 16S rRNA gene sequencing and metagenomics. One potential confounder of these sequence-based approaches is the presence of contamination in DNA extraction kits and other laboratory reagents.
Results
In this study we demonstrate that contaminating DNA is ubiquitous in commonly used DNA extraction kits and other laboratory reagents, varies greatly in composition between different kits and kit batches, and that this contamination critically impacts results obtained from samples containing a low microbial biomass. Contamination impacts both PCR-based 16S rRNA gene surveys and shotgun metagenomics. We provide an extensive list of potential contaminating genera, and guidelines on how to mitigate the effects of contamination.
Conclusions
These results suggest that caution should be advised when applying sequence-based techniques to the study of microbiota present in low biomass environments. Concurrent sequencing of negative control samples is strongly advised.
I first saw this in a tweet by Nick Loman, asking
what’s the point in publishing stuff like biomedcentral.com/1741-7007/12/87 if no-ones gonna act on it
I’m not sure what Nick’s criteria is for “no-ones gonna act on it,” but perhaps softly saying results could be better with better control for contamination isn’t a stark enough statement of the issue. Try:
Reagent and Laboratory Contamination – Garbage In, Garbage Out
Uncontrolled and/or unaccounted for contamination is certainly garbage in and results that contain uncontrolled and/or unaccounted for contamination fits my notion of garbage out.
Phrased as the choice between producing garbage and producing quality research frames the issue in such a way as to produce an impetus for change. Yes?
Working Group on Astroinformatics and Astrostatistics (WGAA)
From the webpage:
History: The WG was established at the 220th Meeting, June 2012 in Anchorage in response to a White Paper report submitted to the Astro2010 Decadal Survey.
Members: Any AAS member with an interest in these fields is invited to join.
Steering Committee: ~10 members including the chair; initially appointed by Council and in successive terms, nominated by the Working Group and confirmed by the AAS Council
Term: Three years staggered, with terms beginning and ending at the close of the Annual Summer Meeting. Members may be re-appointed.
Chair: Initially appointed by Council after consultation with the inaugural WG members. In successive terms, nominated by the Working Group; confirmed by the AAS Council.
Charge: The Working Group is charged with developing and spreading awareness of the applications of advanced computer science, statistics and allied branches of applied mathematics to further the goals of astronomical and astrophysical research.
The Working Group may interact with other academic, international, or governmental organizations, as appropriate, to advance the fields of astroinformatics and astrostatistics. It must report to Council annually on its activities, and is encouraged to make suggestions and proposals to the AAS leadership on ways to enhance the utility and visibility of its activities.
Astroinformatics and astronstatistics, modern astronomy in general, doesn’t have small data. All of its data is “Big Data.”
Members of your data team should select not-your-domain groups to monitor for innovations and new big data techniques.
I first saw this in a tweet by Kirk Borne.
PS: Kirk added a link to the paper that resulted in this group: Astroinformatics: A 21st Century Approach to Astronomy.
Warning High-Performance Data Mining and Big Data Analytics Warning by Khosrow Hassibi.
Before you order this book, there are three things you need to take into account.
First, the book claims to target eight (8) separate audiences:
Target Audience: This book is intended for a variety of audiences:
(1) There are many people in the technology, science, and business disciplines who are curious to learn about big data analytics in a broad sense, combined with some historical perspective. They may intend to enter the big data market and play a role. For this group, the book provides an overview of many relevant topics. College and high school students who have interest in science and math, and are contemplating about what to pursue as a career, will also find the book helpful.
(2) For the executives, business managers, and sales staff who also have an interest in technology, believe in the importance of analytics, and want to understand big data analytics beyond the buzzwords, this book provides a good overview and a deeper introduction of the relevant topics.
(3) Those in classic organizations—at any vertical and level— who either manage or consume data find this book helpful in grasping the important topics in big data analytics and its potential impact in their
organizations.(4) Those in IT benefit from this book by learning about the challenges of the data consumers: data miners/scientists, data analysts, and other business users. Often the perspectives of IT and analytics users are different on how data is to be managed and consumed.
(5) Business analysts can learn about the different big data technologies and how it may impact what they do today.
(6) Statisticians typically use a narrow set of statistical tools and usually work on a narrow set of business problems depending on their industry. This book points to many other frontiers in which statisticians can continue to play important roles.
(7) Since the main focus of the book is high-performance data mining and contrasting it with big data analytics in terms of commonalities and differences, data miners and machine learning practitioners gain a holistic view of how the two relate.
(8) Those interested in data science gain from the historical viewpoint of the book since the practice of data science—as opposed to the name itself—has existed for a long time. Big data revolution has significantly helped create awareness about analytics and increased the need for data science professionals.
Second, are you wondering how a book covers that many audiences and that much technology in a little over 300 pages? Review the Table of Contents. See how in depth the coverage appears to be to you.
Third, you do know that Mining of Massive Datasets by Jure Leskovec, Anand Rajaraman, Jeff Ullman, is available for free (electronic copy) and in hard copy from Cambridge University Press. Yes?
Its prerequisites are:
1. An introduction to database systems, covering SQL and related programming systems.
2. A sophomore-level course in data structures, algorithms, and discrete math.
3. A sophomore-level course in software systems, software engineering, and programming languages.
With one audience, satisfying technical prerequisites, Mining Massive Datasets (MMD) runs over five hundred (500) pages.
Up to you but I prefer narrower in depth coverage of topics.
Powered by WordPress
