Graphs by MIT Students Show the Enormously Intrusive Nature of Metadata by Kade Crockford.
From the post (as is the image):
You’ve probably heard politicians or pundits say that “metadata doesn’t matter.” They argue that police and intelligence agencies shouldn’t need probable cause warrants to collect information about our communications. Metadata isn’t all that revealing, they say, it’s just numbers.
But the digital metadata trails you leave behind every day say more about you than you can imagine. Now, thanks to two MIT students, you don’t have to imagine—at least with respect to your email.
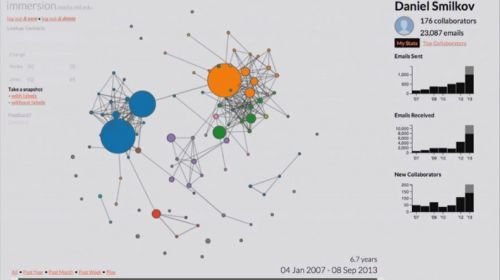
Deepak Jagdish and Daniel Smilkov’s Immersion program maps your life, using your email account. After you give the researchers access to your email metadata—not the content, just the time and date stamps, and “To” and “Cc” fields—they’ll return to you a series of maps and graphs that will blow your mind. The program will remind you of former loves, illustrate the changing dynamics of your professional and personal networks over time, mark deaths and transitions in your life, and more. You’ll probably learn something new about yourself, if you study it closely enough. (The students say they delete your data on your command.)
…
If you have any interest in privacy at all, you need to read Kade’s post in full and watch video.
Personally I don’t think we can recover our privacy from the government. After all, it is already illegal for the NSA to be spying on U.S. citizens. Their excuse (now and in the future), “it was necessary.”
On the upside, we can and should deprive government toadies and others of privacy in the performance of official government functions. There is no right to privacy in order to loot the U.S. treasury or to use elected/appointed office for political or personal gain.
Keep the locations of nuclear weapons and codes secret. Throw the rest of it wide open.
As the Supreme Court stated in United States v. Nixon
The expectation of a President to the confidentiality of his conversations and correspondence, like the claim of confidentiality of judicial deliberations, for example, has all the values to which we accord deference for the privacy of all citizens and, added to those values, is the necessity for protection of the public interest in candid, objective, and even blunt or harsh opinions in Presidential decision-making. A President and those who assist him must be free to explore alternatives in the process of shaping policies and making decisions and to do so in a way many would be unwilling to express except privately. These are the considerations justifying a presumptive privilege for Presidential communications. (emphasis added)
Since we as citizens have no privacy from the government, it only stands to reason that the government, including the President, has no privacy from citizens.
BTW, as a historical note, there has been no shortage of self-serving advisers for presidents following Nixon and the disclosure of the Watergate tapes.