Modern Healthcare Architectures Built with Hadoop by Justin Sears.
From the post:
We have heard plenty in the news lately about healthcare challenges and the difficult choices faced by hospital administrators, technology and pharmaceutical providers, researchers, and clinicians. At the same time, consumers are experiencing increased costs without a corresponding increase in health security or in the reliability of clinical outcomes.
One key obstacle in the healthcare market is data liquidity (for patients, practitioners and payers) and some are using Apache Hadoop to overcome this challenge, as part of a modern data architecture. This post describes some healthcare use cases, a healthcare reference architecture and how Hadoop can ease the pain caused by poor data liquidity.
As you would guess, I like the phrase data liquidity. 😉
And Justin lays out the areas where we are going to find “poor data liquidity.”
Source data comes from:
- Legacy Electronic Medical Records (EMRs)
- Transcriptions
- PACS
- Medication Administration
- Financial
- Laboratory (e.g. SunQuest, Cerner)
- RTLS (for locating medical equipment & patient throughput)
- Bio Repository
|
- Device Integration (e.g. iSirona)
- Home Devices (e.g. scales and heart monitors)
- Clinical Trials
- Genomics (e.g. 23andMe, Cancer Genomics Hub)
- Radiology (e.g. RadNet)
- Quantified Self Sensors (e.g. Fitbit, SmartSleep)
- Social Media Streams (e.g. FourSquare, Twitter)
|
But then I don’t see what part of the Hadoop architecture addresses the problem of “poor data liquidity.”
Do you?
I thought I had found it when Charles Boicey (in the UCIH case study) says:
“Hadoop is the only technology that allows healthcare to store data in its native form. If Hadoop didn’t exist we would still have to make decisions about what can come into our data warehouse or the electronic medical record (and what cannot). Now we can bring everything into Hadoop, regardless of data format or speed of ingest. If I find a new data source, I can start storing it the day that I learn about it. We leave no data behind.”
But that’s not “data liquidity,” not in any meaningful sense of the word. Dumping your data to paper would be just as effective and probably less costly.
To be useful, “data liquidity” must has a sense of being integrated with data from diverse sources. To present the clinician, researcher, health care facility, etc. with all the data about a patient, not just some of it.
I also checked the McKinsey & Company report “The ‘Big Data’ Revolution in Healthcare.” I didn’t expect them to miss the data integration question and they didn’t.
The second exhibit in the McKinsey and Company report (the full report):
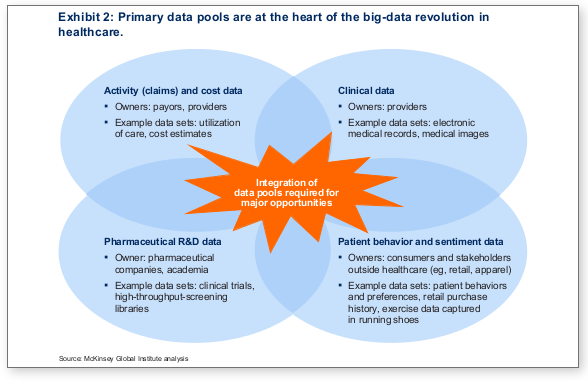
The part in red reads:
Integration of data pools required for major opportunities.
I take that to mean that in order to have meaningful healthcare reform, integration of health care data pools is the first step.
Do you disagree?
And if that’s true, that we need integration of health care data pools first, do you think Hadoop can accomplish that auto-magically?
I don’t either.