Setting up a Hadoop cluster – Part 1: Manual Installation by Lars Francke.
From the post:
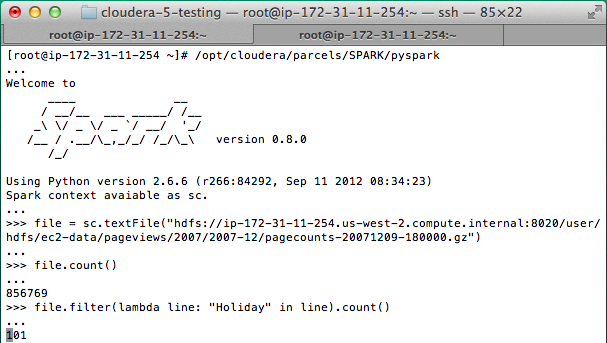
In the last few months I was tasked several times with setting up Hadoop clusters. Those weren’t huge – two to thirteen machines – but from what I read and hear this is a common use case especially for companies just starting with Hadoop or setting up a first small test cluster. While there is a huge amount of documentation in form of official documentation, blog posts, articles and books most of it stops just where it gets interesting: Dealing with all the stuff you really have to do to set up a cluster, cleaning logs, maintaining the system, knowing what and how to tune etc.
I’ll try to describe all the hoops we had to jump through and all the steps involved to get our Hadoop cluster up and running. Probably trivial stuff for experienced Sysadmins but if you’re a Developer and finding yourself in the “Devops” role all of a sudden I hope it is useful to you.
While working at GBIF I was asked to set up a Hadoop cluster on 15 existing and 3 new machines. So the first interesting thing about this setup is that it is a heterogeneous environment: Three different configurations at the moment. This is where our first goal came from: We wanted some kind of automated configuration management. We needed to try different cluster configurations and we need to be able to shift roles around the cluster without having to do a lot of manual work on each machine. We decided to use a tool called Puppet for this task.
While Hadoop is not currently in production at GBIF there are mid- to long-term plans to switch parts of our infrastructure to various components of the HStack. Namely MapReduce jobs with Hive and perhaps Pig (there is already strong knowledge of SQL here) and also storing of large amounts of raw data in HBase to be processed asynchronously (~500 million records until next year) and indexed in a Lucene/Solr solution possibly using something like Katta to distribute indexes. For good measure we also have fairly complex geographic calculations and map-tile rendering that could be done on Hadoop. So we have those 18 machines and no real clue how they’ll be used and which services we’d need in the end.
Dated, 2011, but illustrates some of the issues I raised in: Hadoop Ecosystem Configuration Woes?
Do you keep this level of documentation on your Hadoop installs?
I first saw this in a tweet by Marko A. Rodriguez.