New RDF search engine from Yahoo, built on Hadoop (0.23) and MG4j.
I first saw this in a tweet by Yves Raimond.
The best part being pointed to the MG4j project, which I haven’t looked at in a year or more.
More news on that tomorrow!
New RDF search engine from Yahoo, built on Hadoop (0.23) and MG4j.
I first saw this in a tweet by Yves Raimond.
The best part being pointed to the MG4j project, which I haven’t looked at in a year or more.
More news on that tomorrow!
Videos from Lucene/Solr Revolution 2013 San Diego (April 29th – May 2nd, 2013)
Sorted by author, duplicates removed, etc.
These videos merit far more views than they have today. Pass this list along.
Work through the videos and related docs. There are governments out there that want useful search results.
James Atherton, Search Team Lead, 7digital Implementing Search with Solr at 7digital
A usage/case study, describing our journey as we implemented Lucene/Solr, the lessons we learned along the way and where we hope to go in the future.How we implemented our instant search/search suggest. How we handle trying to index 400 million tracks and metadata for over 40 countries, comprising over 300GB of data, and about 70GB of indexes. Finally where we hope to go in the future.
Ben Brown, Software Architect, Cerner Corporation Brahe – Mass scale flexible indexing
Our team made their first foray into Solr building out Chart Search, an offering on top of Cerner's primary EMR to help make search over a patient's chart smarter and easier. After bringing on over 100 client hospitals and indexing many tens of billions of clinical documents and discrete results we've (thankfully) learned a couple of things.
The traditional hashed document ID over many shards and no easily accessible source of truth doesn't make for a flexible index.
Learn the finer points of the strategy where we shifted our source of truth to HBase. How we deploy new indexes with the click of a button, take an existing index and expand the number of shards on the fly, and several other fancy features we enabled.
Paul Doscher, CEO LucidWorks Lucene Revolution 2013, Opening Remarks – Paul Doscher, CEO LucidWorks
Ted Dunning, Chief Application Architect, MapR & Grant Ingersoll, Chief Technology Officer, LucidWorks Crowd-sourced intelligence built into Search over Hadoop
Search has quickly evolved from being an extension of the data warehouse to being run as a real time decision processing system. Search is increasingly being used to gather intelligence on multi-structured data leveraging distributed platforms such as Hadoop in the background. This session will provide details on how search engines can be abused to use not text, but mathematically derived tokens to build models that implement reflected intelligence. In such a system, intelligent or trend-setting behavior of some users is reflected back at other users. More importantly, the mathematics of evaluating these models can be hidden in a conventional search engine like SolR, making the system easy to build and deploy. The session will describe how to integrate Apache Solr/Lucene with Hadoop. Then we will show how crowd-sourced search behavior can be looped back into analysis and how constantly self-correcting models can be created and deployed. Finally, we will show how these models can respond with intelligent behavior in realtime.
Stephane Gamard, Chief Technology Officer, Searchbox How to make a simple cheap high-availability self-healing Solr cluster
In this presentation we aim to show how to make a high availability Solr cloud with 4.1 using only Solr and a few bash scripts. The goal is to present an infrastructure which is self healing using only cheap instances based on ephemeral storage. We will start by providing a comprehensive overview of the relation between collections, Solr cores, shardes, and cluster nodes. We continue by an introduction to Solr 4.x clustering using zookeeper with a particular emphasis on cluster state status/monitoring and solr collection configuration. The core of our presentation will be demonstrated using a live cluster.
We will show how to use cron and bash to monitor the state of the cluster and the state of its nodes. We will then show how we can extend our monitoring to auto generate new nodes, attach them to the cluster, and assign them shardes (selecting between missing shardes or replication for HA). We will show that using a high replication factor it is possible to use ephemeral storage for shards without the risk of data loss, greatly reducing the cost and management of the architecture. Future work discussions, which might be engaged using an open source effort, include monitoring activity of individual nodes as to scale the cluster according to traffic and usage.
Trey Grainger, Search Technology Development Manager, CareerBuilder Building a Real-time, Big Data Analytics Platform with Solr
Having "big data" is great, but turning that data into actionable intelligence is where the real value lies. This talk will demonstrate how you can use Solr to build a highly scalable data analytics engine to enable customers to engage in lightning fast, real-time knowledge discovery.
At CareerBuilder, we utilize these techniques to report the supply and demand of the labor force, compensation trends, customer performance metrics, and many live internal platform analytics. You will walk away from this talk with an advanced understanding of faceting, including pivot-faceting, geo/radius faceting, time-series faceting, function faceting, and multi-select faceting. You'll also get a sneak peak at some new faceting capabilities just wrapping up development including distributed pivot facets and percentile/stats faceting, which will be open-sourced.
The presentation will be a technical tutorial, along with real-world use-cases and data visualizations. After this talk, you'll never see Solr as just a text search engine again.
Chris Hostetter (aka Hoss) Stump The Chump: Get On The Spot Solutions To Your Real Life Lucene/Solr Challenges
Got a tough problem with your Solr or Lucene application? Facing
challenges that you'd like some advice on? Looking for new approaches to
overcome a Lucene/Solr issue? Not sure how to get the results you
expected? Don't know where to get started? Then this session is for you.
Now, you can get your questions answered live, in front of an audience of
hundreds of Lucene Revolution attendees! Back again by popular demand,
"Stump the Chump" at Lucene Revolution 2013 puts Chris Hostetter (aka Hoss) in the hot seat to tackle questions live.
All you need to do is send in your questions to us here at
stump@lucenerevolution.org. You can ask anything you like, but consider
topics in areas like: Data modelling Query parsing Tricky faceting Text analysis Scalability
You can email your questions to stump@lucenerevolution.org. Please
describe in detail the challenge you have faced and possible approach you
have taken to solve the problem. Anything related to Solr/Lucene is fair game.
Our moderator, Steve Rowe, will will read the questions, and Hoss have to formulate a solution on the spot. A panel of judges will decide if he has provided an effective answer. Prizes will be awarded by the panel for the best question – and for those deemed to have "Stumped the Chump".
Rahul Jain, System Analyst (Software Engineer), IVY Comptech Pvt Ltd Building a Near Real-time Search Engine and Analytics for logs using Solr
Consolidation and Indexing of logs to search them in real time poses an array of challenges when you have hundreds of servers producing terabytes of logs every day. Since the log events mostly have a small size of around 200 bytes to few KBs, makes it more difficult to handle because lesser the size of a log event, more the number of documents to index. In this session, we will discuss the challenges faced by us and solutions developed to overcome them. The list of items that will be covered in the talk are as follows.
Methods to collect logs in real time.
How Lucene was tuned to achieve an indexing rate of 1 GB in 46 seconds
Tips and techniques incorporated/used to manage distributed index generation and search on multiple shards
How choosing a layer based partition strategy helped us to bring down the search response times.
Log analysis and generation of analytics using Solr.
Design and architecture used to build the search platform.
Mikhail Khludnev, eCommerce Search Platform, Grid Dynamics Concept Search for eCommerce with Solr
This talk describes our experience in eCommerce Search: challenges which we've faced and the chosen approaches. It's not indented to be a full description of implementation, because too many details need to be touched. This talk is more like problem statement and general solutions description, which have a number of points for technical or even academic discussion. It's focused on text search use-case, structures (or scoped) search is out of agenda as well as faceted navigation.
Hilary Mason, Chief Scientist, bitly Search is not a solved problem.
Remi Mikalsen, Search Engineer, The Norwegian Centre for ICT in Education Multi-faceted responsive search, autocomplete, feeds engine and logging
Learn how utdanning.no leverages open source technologies to deliver a blazing fast multi-faceted responsive search experience and a flexible and efficient feeds engine on top of Solr 3.6. Among the key open source projects that will be covered are Solr, Ajax-Solr, SolrPHPClient, Bootstrap, jQuery and Drupal. Notable highlights are ajaxified pivot facets, multiple parents hierarchical facets, ajax autocomplete with edge-n-gram and grouping, integrating our search widgets on any external website, custom Solr logging and using Solr to deliver Atom feeds. utdanning.no is a governmental website that collects, normalizes and publishes study information for related to secondary school and higher education in Norway. With 1.2 million visitors each year and 12.000 indexed documents we focus on precise information and a high degree of usability for students, potential students and counselors.
Mark Miller, Software Engineer, Cloudera SolrCloud: the 'Search First' NoSQL database
As the NoSQL ecosystem looks to integrate great search, great search is naturally beginning to expose many NoSQL features. Will these Goliath's collide? Or will they remain specialized while intermingling — two sides of the same coin.
Come learn about where SolrCloud fits into the NoSQL landscape. What can it do? What will it do? And how will the big data, NoSQL, Search ecosystem evolve. If you are interested in Big Data, NoSQL, distributed systems, CAP theorem and other hype filled terms, than this talk may be for you.
Dragan Milosevic, Senior Architect, zanox Analytics in OLAP with Lucene and Hadoop
Analytics powered by Hadoop is powerful tool and this talk addresses its application in OLAP built on top of Lucene. Many applications use Lucene indexes also for storing data to alleviate challenges concerned with external data sources. The analyses of queries can reveal stored fields that are in most cases accessed together. If one binary compressed field replaces those fields, amount of data to be loaded is reduced and processing of queries is boosted. Furthermore, documents that are frequently loaded together can be identified. If those documents are saved in almost successive positions in Lucene stored files, benefits from file-system caches are improved and loading of documents is noticeably faster.
Large-scale searching applications typically deploy sharding and partition documents by hashing. The implemented OLAP has shown that such hash-based partitioning is not always an optimal one. An alternative partitioning, supported by analytics, has been developed. It places documents that are frequently used together in same shards, which maximizes the amount of work that can be locally done and reduces the communication overhead among searchers. As an extra bonus, it also identifies slow queries that typically point to emerging trends, and suggests the addition of optimized searchers for handling similar queries.
Christian Moen, Software Engineer, Atilika Inc. Language support and linguistics in Lucene/Solr and its eco-system
In search, language handling is often key to getting a good search experience. This talk gives an overview of language handling and linguistics functionality in Lucene/Solr and best-practices for using them to handle Western, Asian and multi-language deployments. Pointers and references within the open source and commercial eco-systems for more advanced linguistics and their applications are also discussed.
The presentation is mix of overview and hands-on best-practices the audience can benefit immediately from in their Lucene/Solr deployments. The eco-system part is meant to inspire how more advanced functionality can be developed by means of the available open source technologies within the Apache eco-system (predominantly) while also highlighting some of the commercial options available.
Chandra Mouleeswaran, Co Chair at Intellifest.org, ThreatMetrix Rapid pruning of search space through hierarchical matching
This talk will present our experiences in using Lucene/Solr to the classification of user and device data. On a daily basis, ThreatMetrix, Inc., handles a huge volume of volatile data. The primary challenge is rapidly and precisely classifying each incoming transaction, by searching a huge index within a very strict latency specification. The audience will be taken through the various design choices and the lessons learned. Details on introducing a hierarchical search procedure that systematically divides the search space into manageable partitions, yet maintaining precision, will be presented.
Kathy Phillips, Enterprise Search Services Manager/VP, Wells Fargo & Co. & Tom Lutmer, eBusiness Systems Consultant, Enterprise Search Services team, Wells Fargo & Co Beyond simple search — adding business value in the enterprise
What is enterprise search? Is it a single search box that spans all enterprise resources or is it much more than that? Explore how enterprise search applications can move beyond simple keyword search to add unique business value. Attendees will learn about the benefits and challenges to different types of search applications such as site search, interactive search, search as business intelligence, and niche search applications. Join the discussion about the possibilities and future direction of new business applications within the enterprise.
David Piraino and Daniel Palmer, Chief Imaging Information Officers, Imaging Institute Cleveland Clinic, Cleveland Clinic Next Generation Electronic Medical Records and Search: A Test Implementation in Radiology
Most patient specifc medical information is document oriented with varying amounts of associated meta-data. Most of pateint medical information is textual and semi-structured. Electronic Medical Record Systems (EMR) are not optimized to present the textual information to users in the most understandable ways. Present EMRs show information to the user in a reverse time oriented patient specific manner only. This talk discribes the construction and use of Solr search technologies to provide relevant historical information at the point of care while intepreting radiology images.
Radiology reports over a 4 year period were extracted from our Radiology Information System (RIS) and passed through a text processing engine to extract the results, impression, exam description, location, history, and date. Fifteen cases reported during clinical practice were used as test cases to determine if ""similar"" historical cases were found . The results were evaluated by the number of searches that returned any result in less than 3 seconds and the number of cases that illustrated the questioned diagnosis in the top 10 results returned as determined by a bone and joint radiologist. Also methods to better optimize the search results were reviewed.
An average of 7.8 out of the 10 highest rated reports showed a similar case highly related to the present case. The best search showed 10 out of 10 cases that were good examples and the lowest match search showed 2 out of 10 cases that were good examples.The talk will highlight this specific use case and the issues and advances of using Solr search technology in medicine with focus on point of care applications.
Timothy Potter, Architect, Big Data Analytics, Dachis Group Scaling up Solr 4.1 to Power Big Search in Social Media Analytics
My presentation focuses on how we implemented Solr 4.1 to be the cornerstone of our social marketing analytics platform. Our platform analyzes relationships, behaviors, and conversations between 30,000 brands and 100M social accounts every 15 minutes. Combined with our Hadoop cluster, we have achieved throughput rates greater than 8,000 documents per second. Our index currently contains more than 500,000,000 documents and is growing by 3 to 4 million documents per day.
The presentation will include details about:
Designing a Solr Cloud cluster for scalability and high-availability using sharding and replication with Zookeeper
Operations concerns like how to handle a failed node and monitoring
How we deal with indexing big data from Pig/Hadoop as an example of using the CloudSolrServer in SolrJ and managing searchers for high indexing throughput
Example uses of key features like real-time gets, atomic updates, custom hashing, and distributed facets. Attendees will come away from this presentation with a real-world use case that proves Solr 4.1 is scalable, stable, and is production ready. (note: we are in production on 18 nodes in EC2 with a recent nightly build off the branch_4x).
Ingo Renner, Software Engineer, Infield Design CMS Integration of Apache Solr – How we did it.
TYPO3 is an Open Source Content Management System that is very popular in Europe, especially in the German market, and gaining traction in the U.S., too.
TYPO3 is a good example of how to integrate Solr with a CMS. The challenges we faced are typical of any CMS integration. We came up with solutions and ideas to these challenges and our hope is that they might be of help for other CMS integrations as well.
That includes content indexing, file indexing, keeping track of content changes, handling multi-language sites, search and facetting, access restrictions, result presentation, and how to keep all these things flexible and re-usable for many different sites.
For all these things we used a couple additional Apache projects and we would like to show how we use them and how we contributed back to them while building our Solr integration.
David Smiley, Software Systems Engineer, Lead, MITRE Lucene / Solr 4 Spatial Deep Dive
Lucene's former spatial contrib is gone and in its place is an entirely new spatial module developed by several well-known names in the Lucene/Solr spatial community. The heart of this module is an approach in which spatial geometries are indexed using edge-ngram tokenized geohashes searched with a prefix-tree/trie recursive algorithm. It sounds cool and it is! In this presentation, you'll see how it works, why it's fast, and what new things you can do with it. Key features are support for multi-valued fields, and indexing shapes with area — even polygons, and support for various spatial predicates like "Within". You'll see a live demonstration and a visual representation of geohash indexed shapes. Finally, the session will conclude with a look at the future direction of the module.
David Smiley, Software Systems Engineer, Lead, MITRE Text Tagging with Finite State Transducers
OpenSextant is an unstructured-text geotagger. A core component of OpenSextant is a general-purpose text tagger that scans a text document for matching multi-word based substrings from a large dictionary. Harnessing the power of Lucene's state-of-the-art finite state transducer (FST) technology, the text tagger was able to save over 40x the amount of memory estimated for a leading in-memory alternative. Lucene's FSTs are elusive due to their technical complexity but overcoming the learning curve can pay off handsomely.
Marc Sturlese, Architect, Backend engineer, Trovit Batch Indexing and Near Real Time, keeping things fast
In this talk I will explain how we combine a mixed architecture using Hadoop for batch indexing and Storm, HBase and Zookeeper to keep our indexes updated in near real time.Will talk about why we didn't choose just a default Solr Cloud and it's real time feature (mainly to avoid hitting merges while serving queries on the slaves) and the advantages and complexities of having a mixed architecture. Both parts of the infrastucture and how they are coordinated will be explained with details.Finally will mention future lines, how we plan to use Lucene real time feature.
Tyler Tate, Cofounder, TwigKit Designing the Search Experience
Search is not just a box and ten blue links. Search is a journey: an exploration where what we encounter along the way changes what we seek. But in order to guide people along this journey, we must understand both the art and science of search.In this talk Tyler Tate, cofounder of TwigKit and coauthor of the new book Designing the Search Experience, weaves together the theories of information seeking with the practice of user interface design, providing a comprehensive guide to designing search.Pulling from a wealth of research conducted over the last 30 years, Tyler begins by establishing a framework of search and discovery. He outlines cognitive attributes of users—including their level of expertise, cognitive style, and learning style; describes models of information seeking and how they've been shaped by theories such as information foraging and sensemaking; and reviews the role that task, physical, social, and environmental context plays in the search process.
Tyler then moves from theory to practice, drawing on his experience of designing 50+ search user interfaces to provide practical guidance for common search requirements. He describes best practices and demonstrates reams of examples for everything from entering the query (including the search box, as-you-type suggestions, advanced search, and non-textual input), to the layout of search results (such as lists, grids, maps, augmented reality, and voice), to result manipulation (e.g. pagination and sorting) and, last but not least, the ins-and-outs of faceted navigation. Through it all, Tyler also addresses mobile interface design and how responsive design techniques can be used to achieve cross-platform search.This intensive talk will enable you to create better search experiences by equipping you with a well-rounded understanding of the theories of information seeking, and providing you with a sweeping survey of search user interface best practices.
Troy Thomas, Senior Manager, Internet Enabled Services, Synopsys & Koorosh Vakhshoori, Software Architect,Synopsys Make your GUI Shine with AJAX-Solr
With AJAX-Solr, you can implement widgets like faceting, auto-complete, spellchecker and pagination quickly and elegantly. AJAX-Solr is a JavaScript library that uses the Solr REST-like API to display search results in an interactive user interface. Come learn why we chose AJAX-Solr and Solr 4 for the SolvNet search project. Get an overview of the AJAX-Solr framework (Manager, Parameters, Widgets and Theming). Get a deeper understanding of the technical concepts using real-world examples. Best practices and lessons learned will also be presented.
Adrian Trenaman, Senior Software Engineer, Gilt Groupe Personalized Search on the Largest Flash Sale Site in America
Gilt Groupe is an innovative online shopping destination offering its members special access to the most inspiring merchandise, culinary offerings, and experiences every day, many at insider prices. Every day new merchandising is offered for sale at discounts of up to 70%. Sales start at 12 noon EST resulting in an avalanche of hits to the site, so delivering a rich user experience requires substantial technical innovation.
Implementing search for a flash-sales business, where inventory is limited and changes rapidly as our sales go live to a stampede of members every noon, poses a number of technical challenges. For example, with small numbers of fast moving inventory we want to be sure that search results reflect those products we still have available for sale. Also, personalizing search — where search listings may contain exclusive items that are available only to certain users — was also a big challenge
Gilt has built out keyword search using Scala, Play Framework and Apache Solr / Lucene. The solution, which involves less than 4,000 lines of code, comfortably provides search results to members in under 40ms. In this talk, we'll give a tour of the logical and physical architecture of the solution, the approach to schema definition for the search index, and how we use custom filters to perform personalization and enforce product availability windows. We'll discuss lessons learnt, and describe how we plan to adopt Solr to power sale, brand, category and search listings throughout all of Gilt's estate.
Doug Turnbull, Search and Big Data Architect, OpenSource Connections State Decoded: Empowering The Masses with Open Source State Law Search
The Law has traditionally been a topic dominated by an elite group of experts. Watch how State Decoded has transformed the law from a scary, academic topic to a friendly resource that empowers everyone using Apache Solr. This talk is a call to action for discovery and design to break open ivory towers of expertise by baking rich discovery into your UI and data structures.
Screaming fast Lucene searches using C++ via JNI by Michael McCandless.
From the post:
At the end of the day, when Lucene executes a query, after the initial setup the true hot-spot is usually rather basic code that decodes sequential blocks of integer docIDs, term frequencies and positions, matches them (e.g. taking union or intersection for BooleanQuery), computes a score for each hit and finally saves the hit if it’s competitive, during collection.
Even apparently complex queries like FuzzyQuery or WildcardQuery go through a rewrite process that reduces them to much simpler forms like BooleanQuery.
Lucene’s hot-spots are so simple that optimizing them by porting them to native C++ (via JNI) was too tempting!
So I did just that, creating the lucene-c-boost github project, and the resulting speedups are exciting:
(…)
Speedups range from 0.7 X to 7.8 X.
Read Michael’s post for explanations, warnings, caveats, etc.
But it is exciting news!
Discovering Emerging Tech through Graph Analysis by Henry Hwangbo.
Description:
With the torrent of data available to us on the Internet, it’s been increasingly difficult to separate the signal from the noise. We set out on a journey with a simple directive: Figure out a way to discover emerging technology trends. Through a series of experiments, trials, and pivots, we found our answer in the power of graph databases. We essentially built our “Emerging Tech Radar” on emerging technologies with graph databases being central to our discovery platform. Using a mix of NoSQL databases and open source libraries we built a scalable information digestion platform which touches upon multiple topics such as NLP, named entity extraction, data cleansing, cypher queries, multiple visualizations, and polymorphic persistence.
Sounds like Henry needs to go stand close to the NSA. 😉
Not really!
Henry’s use case isn’t trying to boil a random ocean of data to see if insights emerge.
Like on slide 19 where he recommends cleaning up data and eliminating duplicates before loading the data.
If you see a video link to this presentation, please post it.
Symposium on Visions of the Theory of Computing by the Simons Institute for the Theory of Computing.
Description:
May 29-31, 2013, UC Berkeley: This three-day symposium brought together distinguished speakers and participants from the Bay Area and all over the world to celebrate both the excitement of fundamental research on the Theory of Computing, and the accomplishments and promise of computational research in effecting progress in other sciences – the two pillars of the research agenda of the Institute.
I’m not sure if it is YouTube or the people who post videos to YouTube, but customary sorting rules, such as by an author’s last name appear to be lacking.
To facilitate your finding the lecture of your choice, I have sorted the videos by the speaker’s last name.
Should you have the occasion to post a list of videos, papers, presentations, please be courteous to readers who want to scan a list sorted by author/presenter.
It will still appear to be a random ordering to those unfamiliar with that technique. (Or ctrl-f or search engines.) 😉
Smart Visualization Annotation by Enrico Bertini.
From the post:
There are three research papers which have drawn my attention lately. They all deal with automatic annotation of data visualizations, that is, adding labels to the visualization automatically.
It seems to me that annotations, as an integral part of a visualization design, have received somewhat little attention in comparison to other components of a visual representation (shapes, layouts, colors, etc.). A quick check in the books I have in my bookshelf kind of support my hypothesis. The only exception I found is Colin Ware’s Information Visualization book, which has a whole section on “Linking Text with Graphical Elements“. This is weird because, think about it, text is the most powerful means we have to bridge the semantic gap between the visual representation and its interpretation. With text we can clarify, explain, give meaning, etc.
Smart annotations is an interesting area of research because, not only it can reduce the burden of manually annotating a visualization but it can also reveal interesting patterns and trends we might not know about or, worse, may get unnoticed. Here are the three papers (click on the images to see a higher resolution version).
(…)
What do you make of: “…bridge the semantic gap between the visual representation and its interpretation.”?
Is there a gap between the “visual representation and its interpretation,” or is there a semantic gap between multiple observers of a visual representation?
I ask because I am not sure annotations (text) limits the range of interpretation unless the observers are already very close in world views.
That is text cannot command us to accept interpretations unless we are already disposed to accept them.
I commend all three papers to you for a close reading.
Hosting a Page Description Workshop by Colin Butler and Andrew Wirtanen.
From the post:
You’ve met with your stakeholders, created personas, and developed some user stories, but you still find yourself having a difficult time starting the process of sketching layouts for your web project. Sound familiar?
It can be quite challenging making that last step from goals to content in a way that addresses your stakeholders’ needs well. You can build a Page Description Diagram (PDD) independently to help you determine the priority of each component on a web page, but you are still potentially missing some valuable information: input from stakeholders.
In our efforts to improve the requirements gathering process, we’ve had considerable success involving stakeholders by using what we call a Page Description Workshop (PDW).
Developing a topic map UI?
How is that different from a webpage?
At least from the user’s perspective?
Useful as well for ferreting out unspoken requirements for the topic map.
Terms filter lookup by Zachary Tong.
From the post:
There is a new feature in the 0.90 branch that is pretty awesome: the Terms Filter now supports document lookups.
In a normal Terms Filter, you provide a list of Terms that you want to filter against. This is fine for small lists, but what if you have 100 terms? A thousand terms? That is a lot of data to pass over the wire. If that list of terms is stored in your index somewhere, you also have to retrieve it first…just so you can pass it back to Elasticsearch.
The new lookup feature tells Elasticsearch to use another document as your terms array. Instead of passing 1000 terms, you simply tell the Terms Filter “Hey, all the terms I want are in this document”. Elasticsearch will fetch that document internally, extract the terms and perform your query.
Very cool!
Even has a non-Twitter example. 😉
Character Sorted Table Showing Entity Names and Unicode Values
I often need to look up just one character and guessing which part of Unicode will have it is a pain.
I found this thirty-seven (37) page summary of characters with entity names and Unicode values at the U. S. Government Printing Office (GPO).
I could not find any directories above it with an index page or pointers to this file.
I have not verified the entries in this listing. Use at your own risk.
To summarize: Elasticsearch indexer committed to the trunk of Apache Nutch in rev. 1494496.
Enjoy!
Fundamentals of Information Retrieval: Illustration with Apache Lucene by Majirus FANSI.
From the description:
Information Retrieval is becoming the principal mean of access to Information. It is now common for web applications to provide interface for free text search. In this talk we start by describing the scientific underpinning of information retrieval. We review the main models on which are based the main search tools, i.e. the Boolean model and the Vector Space Model. We illustrate our talk with a web application based on Lucene. We show that Lucene combines both the Boolean and vector space models.
The presentation will give an overview of what Lucene is, where and how it can be used. We will cover the basic Lucene concepts (index, directory, document, field, term), text analysis (tokenizing, token filtering, sotp words), indexing (how to create an index, how to index documents), and seaching (how to run keyword, phrase, Boolean and other queries). We’ll inspect Lucene indices with Luke.
After this talk, the attendee will get the fundamentals of IR as well as how to apply them to build a search application with Lucene.
I am assuming that the random lines in the background of the slides are an artifact of the recording. Quite annoying.
Otherwise, a great presentation!
Apache Nutch: Web-scale search engine toolkit by Andrezej Białecki.
From the description:
This slideset presents the Nutch search engine (http://lucene.apache.org/nutch). A high-level architecture is described, as well as some challenges common in web-crawling and solutions implemented in Nutch. The presentation closes with a brief look into the Nutch future.
One of the best component based descriptions of Nutch that I have ever seen.
Functional Javascript by Michael Fogus.
From the post:
After a seemingly endless journey, the publication of Functional JavaScript is complete and books have found their way into peoples’ homes. Below is a list of useful links related to the book:
- The official Functional JavaScript site
- My Twitter feed, where I will post coupons and inanities
- The Functional JavaScript paperback edition
- The Functional JavaScript Kindle edition
- The Functional JavaScript book source
- Errata
- O’Reilly’s official page
Enjoy.
More summer reading material!
Twitter Analytics Platform Gives Data Back to Users
From the post:
Previously reserved for advertising partners, Twitter Analytics now shows all users an overview of their timeline activity, reveals more detailed information about their followers and lets them download it all as a CSV.
Presented in a month-long timeline of activity, Twitter Analytics visualizes mentions, follows and something previously much harder to track: unfollows. Even this additional context makes Twitter Analytics a useful tool for any user.
The tool also lists out a complete record of your tweets with a few helpful columns added on; Favorites, Retweets and Replies. As you scroll, the timeline becomes fixed to the top of the browser and you can see the relationship between the content of a tweet and the response it got (if it happened in the last 30 days).
Embedded within the tweets column are some additional metrics detailing the number of clicks on links and some callouts highlighting extended reach of individual tweets. Unsurprisingly, this feed-oriented analytics interface reminds me of the ideas in Anil Dash’s Dashboards Should be Feeds. It certainly works well here.
(…)
If the government is going to have your data, then so should you! 😉
From the webpage:
Lux is an open source XML search engine formed by fusing two excellent technologies: the Apache Lucene/Solr search index and the Saxon XQuery/XSLT processor.
Release notes for 0.9 (released today)
This looks quite promising!
Lucene 4.3.1 — Lucene CHANGES.txt
There was a time when we all waited endlessly for bug fixes, patches.
Now that open source projects deliver them on a routine basis, have your upgrade habits changed?
Just curious.
Defending NSA Prism’s Big Data Tools by Doug Henschen.
From the post:
It’s understandable that democracy-loving citizens everywhere are outraged by the idea that the U.S. Government has back-door access to digital details surrounding email messages, phone conversations, video chats, social networks and more on the servers of mainstream service providers including Microsoft, Google, Yahoo, Facebook, YouTube, Skype and Apple.
But the more you know about the technologies being used by the National Security Agency (NSA), the agency behind the controversial Prism program revealed last week by whistleblower Edward Snowden, the less likely you are to view the project as a ham-fisted effort that’s “trading a cherished American value for an unproven theory,” as one opinion piece contrasted personal privacy with big data analysis.
Given my various posts on the Prism controversy, I felt compelled to point you to Doug Henschen’s defense of the same.
As you read Doug’s post, watch for the following themes:
Every piece of data in Accumulo can have a security label, therefore:
Accumulo makes it possible to interrogate certain details while blocking access to personally identifiable information. This capability is likely among the things James R. Clapper, the U.S. director of National Intelligence, was referring to in a statement on the Prism disclosure that mentioned “numerous safeguards that protect privacy and civil liberties.”
So the NSA has your private data but has forbidden itself to look at it. ???
We know that graph searching is effective because:
Kahn says a Sqrrl partner company that does graph analysis of internal network activity for security purposes recently identified suspicious activity using a graph algorithm. “Five days later, they got a knock on the door from the FBI letting them know that data was being exfiltrated from their network, likely by a foreign entity,” Kahn reports.
Did you spot the difference between going from a known target, the “internal network activity” to analyzing data exceeding the size of the WWW for patterns?
Apples aren’t oranges. Ever.
And Doug concludes with some unknown benefit that isn’t related to Prism:
One government insider informs InformationWeek that he knows with certainty that “semantic and visual analytics tools have prevented multiple acts of terrorism.” That insight predates recent advances in graph analysis that are undoubtedly giving the U.S. Government even more powerful tools. Privacy concerns and the desire for checks on government access to private information must be considered, but we can’t naively turn a blind eye to very real threats by not making the most of advanced big data intelligence tools now at our disposal.
Note the omission of PRISM. Yes, traditional wiretapping, surveillance, good old fashioned police work has no doubt prevent acts of terrorism.
What is lacking is PRISM playing a pivotal role in those cases.
As far as the spend any amount of money to guard against terrorism argument, consider that the U.S. population this morning was an estimated 316,075,225.
Including various supporters, etc., being generous, let’s say 10,000 Al-Qaeda members and active supporters.
Considering only the U.S. population, we have Al-Qaeda outnumbered by 3,160,752 to 1.
Do you think we are over reacting just a bit by making fighting terrorism (aside from traditional law enforcement) a priority?
Or to put it differently, who is benefiting from all those tax dollars being spend on the NSA information collecting toys?
Preparing a presentation I stumbled upon a graphic illustration of why we need better semantic techniques for the average author:
Linked Data in 2011:
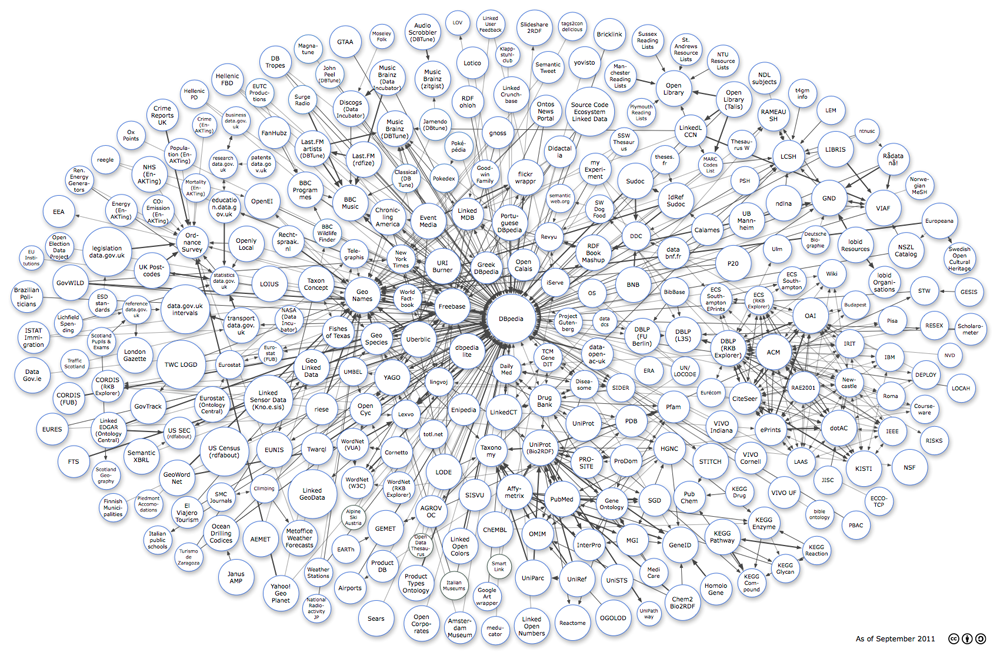
Versus the WWW:

This must be why you don’t see any updated linked data clouds. The comparison is too shocking.
Particularly when you remember the WWW itself is only part of a much larger data cloud. (Ask the NSA about the percentages.)
Data is being produced every day, pushing us further and further behind with regard to its semantics. (And making the linked data cloud an even smaller percentage of all data.)
Authors have semantics in mind when they write.
The question is how to capture those semantics in machine readable form as nearly as seamlessly as authors write?
Suggestions?
Steve Pepper has posted at the XTM group on Linkedin the following question:
If we were to redesign Topic Maps based on what we have learnt in the last decade, what would we do differently?
I’m good for one or two comments but wondering what you think should be different?
Open Access is open access by Peter Suber.
From the post:
I’m happy to announce that my book on OA (Open Access, MIT Press, 2012) is now OA. The book came out in mid-June last year, and the OA editions came out one year later, right on schedule. My thanks to MIT Press.
http://mitpress.mit.edu/books/open-accessToday MIT Press released four OA editions:
and Mobi.
A must forward to all your friends in academia.
Suber narrows the term open access to mean access to research publications, between researchers, without price and permission barriers.
By laying aside numerous other barriers to access and the profit making side of publishing, Suber makes the strongest possible case for open access to research.
A must read!
A heads up for the June 2013 OED release
From the post:
The shorter a word is, generally speaking, the more complex it is lexicographically. Short words are likely to be of Germanic origin, and so to derive from the earliest bedrock of English words; they have probably survived long enough in the language to spawn many new sub-senses; they are almost certain to have generated many fixed compounds and phrases often taking the word into undreamt-of semantic areas; and last but not least they have typically formed the basis of secondary derivative words which in turn develop a life of their own.
All of these conditions apply to the three central words in the current batch of revised entries: hand, head, and heart. Each one of these dates in English from the earliest times and forms part of a bridge back to the Germanic inheritance of English. The revised and updated range contains 2,875 defined items, supported by 22,116 illustrative quotations.
(…)
The noun and verb tweet (in the social-networking sense) has just been added to the OED. This breaks at least one OED rule, namely that a new word needs to be current for ten years before consideration for inclusion. But it seems to be catching on.
Dictionaries, particularly ones like the OED, should be all the evidence needed to prove semantic diversity is everywhere.
But I don’t think anyone really contests that point.
Disagreement arises when others refuse to abandon their incorrect understanding of terms and to adhere to the meanings intended by a speaker.
A speaker understands themselves perfectly and so expects their audience to put for the effort to do the same.
No surprise that we have so many silos, since we have personal, family, group and enterprise silos.
What is surprising is that we communicate as well as we do, despite the many layers of silos.
From NAND to Tetris: Building a Modern Computer from First Principles
From the website:
The official companion web site of Nand2Tetris courses
And of the book The Elements of Computing Systems, MIT Press, By Noam Nisan and Shimon Schocken.
The site contains all the software tools and project materials necessary to build a general-purpose computer system from the ground up. We also provide a set of lectures designed to support a typical course on the subject.
The materials are aimed at students, instructors, and self-learners. Everything is free and open-source; as long as you operate in a non-profit educational setting, you are welcome to modify and use our materials as you see fit.
Kris Geusebroek had me musing this morning about static database structures being a legacy of a shortage of CPU cycles. (I Mapreduced a Neo store [Legacy of CPU Shortages?])
What other limitations are due to system design?
This course could start you in the direction of answering that question.
GraphX preview: Interactive Graph Processing on Spark
Tuesday, July 2, 2013 6:30 PM
Flurry 360 3rd Street, 4th Floor, San Francisco, CA (map)
From the announcement:
This meetup will feature the first public preview of GraphX, a new graph processing framework for Spark. GraphX implements many ideas from an existing specialized graph processing system (in particular GraphLab) to make graph computation efficient. The new graph APIs builds on Spark’s existing RDD abstraction, and thus allows programmers to blend graph and tabular (RDD) views of graph data. For example, GraphX users will be able to use Spark to construct the graph from data on HDFS, and run graph computation (e.g. PageRank) directly on it in the same Spark cluster.
The proposed API enables extremely concise implementation of many graph algorithms. We provide implementations of 4 standard graph algorithms, including PageRank, Connected Components, Shortest Path all in less than 10 lines of code; we also implement the ALS algorithm for collaborative filtering in 40 lines of code. This simple API, coupled with the Scala REPL, enables users can use GraphX to interactively mine graph data in the console.
The talk will be presented by Reynold Xin and Joey Gonzalez. We would like to thank Flurry for providing the space and food.
Spots are going fast!
Register, attend, blog about it!
From the conference page:
Held regularly since 2001, the ADA conference series is focused on algorithms and information extraction from astrophysics data sets. The program includes keynote, invited and contributed talks, as well as posters. This conference series has been characterized by a range of innovative themes, including curvelet transforms, compressed sensing and clustering in cosmology, while at the same time remaining closely linked to front-line open problems and issues in astrophysics and cosmology.
ADA6 2010
ADA7 2011
Online presentations, papers, proposals, etc.
Astronomy – Home of really big data!
Google Visual Assets Guidelines – Part 1 [Link to 2]
From the post:
Google’s brand is shaped in many ways; one of which is through maintaining the visual coherence of our visual assets.
In January 2012, expanding on the new iconography style started by Creative Lab, we began creating this solid, yet flexible, set of guidelines that have been helping Google’s designers and vendors to produce high quality work that helps strengthen Google’s identity.
What you see here is a visual summary of the guidelines, divided into two Behance projects:
Part 1: Product icons and logo lockups
Part 2: User interface icons and Illustrations
This is a real treasure for improving your visual design.
Enjoy!
I first saw this at: Google’s Visual Design Guidelines
Timeline of NSA Domestic Spying
From the post:
All of the evidence found in this timeline can also be found in the Summary of Evidence we submitted to the court in Jewel v. NSA. It is intended to recall all the credible accounts and information of the NSA’s domestic spying program found in the media, congressional testimony, books, and court actions. For a short description of the people involved in the spying you can look at our Profiles page, which includes many of the key characters from the NSA Domestic Spying program.
A very interesting timeline with links to supporting materials.
The oldest entry is 1791, to mark the Bill of Rights, including the Fourth Amendment going into effect. The next oldest entry is 1952, when President Truman establishes the NSA.
While I understand and applaud all attempts to keep the heat on the NSA because of its widespread domestic spying, we should not lose sight of the fact that the NSA and it programs are only a symptom.
Domestic spying on Americans has a long and sordid history separate and apart the NSA.
I will run down the details for another post but in the early 20th century, the government broke into a corporation’s office, stole documents, which they then copied.
When forced to return the originals, for lack of a search warrant, the government proceeded to prosecute the defendants based on the copies.
How is that for overreaching?
The case had a happy result, at least from one point of view but I will cover that separately.
Press the NSA for all we are worth but realize the government as a whole has interests and goals that are not ours.
And that are not calculated to benefit anyone outside of present office holders and their favorites.
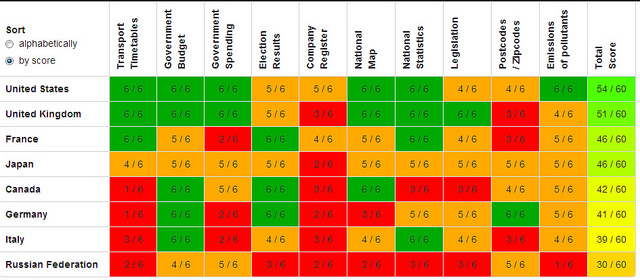
G8 countries must work harder to open up essential data by Rufus Pollock.
From the post:
Open data and transparency will be one of the three main topics at the G8 Summit in Northern Ireland next week. Today transparency campaigners released preview results from the global Open Data Census showing that G8 countries still have a long way to go in releasing essential information as open data.
The Open Data Census is run by the Open Knowledge Foundation, with the help of a network of local data experts around the globe. It measures the openness of data in ten key areas including those essential for transparency and accountability (such as election results and government spending data), and those vital for providing critical services to citizens (such as maps and transport timetables). Full results for the 2013 Open Data Census will be released later this year.
The preview results show that while both the UK and the US (who top the table of G8 countries) have made significant progress towards opening up key datasets, both countries still have work to do. Postcode data, which is required for almost all location-based applications and services, remains a major issue for all G8 countries except Germany. No G8 country scored the top mark for company registry data. Russia is the only G8 country not to have published any of the information included in the census as open data. The full results for G8 countries are online at: http://census.okfn.org/g8/
Apologies for the graphic, it is too small to read. See the original post for a more legible version.
The U.S. came in first with a score of 54 out of a possible 60.
I assume this evaluation was done prior the the revelation of the NSA data snooping?
The U.S. government has massive collections of data that not only isn’t visible, its existence is denied.
How is that for government transparency?
The most disappointing part is that other major players, China, Russia, you take your pick, has largely the small secret data as the United States. Probably not full sets of the day to day memos but the data that really counts, they all have.
So, who is it they are keeping information from?
Ah, that would be their citizens.
Who might not approve of their privileges, goals, tactics, and favoritism.
For example, despite the U.S. government’s disapproval/criticism of many other countries (or rather their governments), I can’t think of any reason for me to dislike unknown citizens of another country.
Whatever goals the U.S. government is pursuing in disadvantaging citizens of another country, it’s not on my behalf.
If the public knew who was benefiting from U.S. policy, perhaps new officials would change those policies.
But that isn’t the goal of the specter of government transparency that the United States leads.
I Mapreduced a Neo store by Kris Geusebroek.
From the post:
Lately I’ve been busy talking at conferences to tell people about our way to create large Neo4j databases. Large means some tens of millions of nodes and hundreds of millions of relationships and billions of properties.
Although the technical description is already on the Xebia blog part 1 and part 2, I would like to give a more functional view on what we did and why we started doing it in the first place.
Our use case consisted of exploring our data to find interesting patterns. The data we want to explore is about financial transactions between people, so the Neo4j graph model is a good fit for us. Because we don’t know upfront what we are looking for we need to create a Neo4j database with some parts of the data and explore that. When there is nothing interesting to find we go enhance our data to contain new information and possibly new connections and create a new Neo4j database with the extra information.
This means it’s not about a one time load of the current data and keep that up to date by adding some more nodes and edges. It’s really about building a new database from the ground up everytime we think of some new way to look at the data.
Deeply interesting work, particularly for its investigation of the internal file structure of Neo4j.
Curious about the
…building a new database from the ground up everytime we think of some new way to look at the data.
To what extent are static database structures a legacy of a shortage of CPU cycles?
With limited CPU cycles, it was necessary to create a static structure, against which query languages could be developed and optimized (again because of a shortage of CPU cycles), and the persisted data structure avoided the overhead of rebuilding the data structure for each user.
It may be that cellphones and tablets need the convenience of static data structures or at least representations of static data structures.
But what of server farms populated by TBs of 3D memory?
Isn’t it time to start thinking beyond the limitations imposed by decades of CPU cycle shortages?
neo4j/cypher/Lucene: Dealing with special characters by Mark Needham.
Mark outlines how to handle “special characters” in Lucene (indexer for Neo4j), only to find that an escape character for a Lucene query is also a special character for Cypher, which itself must be escaped.
There is a chart in Mastering Regular Expressions by Jeffrey E F Friedl of “special” characters but that doesn’t cover all the internal parsing choices software.
Over the last sixty plus years there has been little progress towards a common set of “special” characters in computer science.
Handling of “special” characters lies at the heart of accessing data and all programs have code to account for them.
With no common agreement on “special” characters, what reason would you offer to expect convergence elsewhere?
Quick Accumulo Install (Sqrrl Blog)
Accumulo Installation and Configuration Steps on a Ubuntu VirtualBox Instance
In case you are curious about how your data is being stored. 😉
I first saw this in a tweet by Mandar Chandorkar.
Powered by WordPress