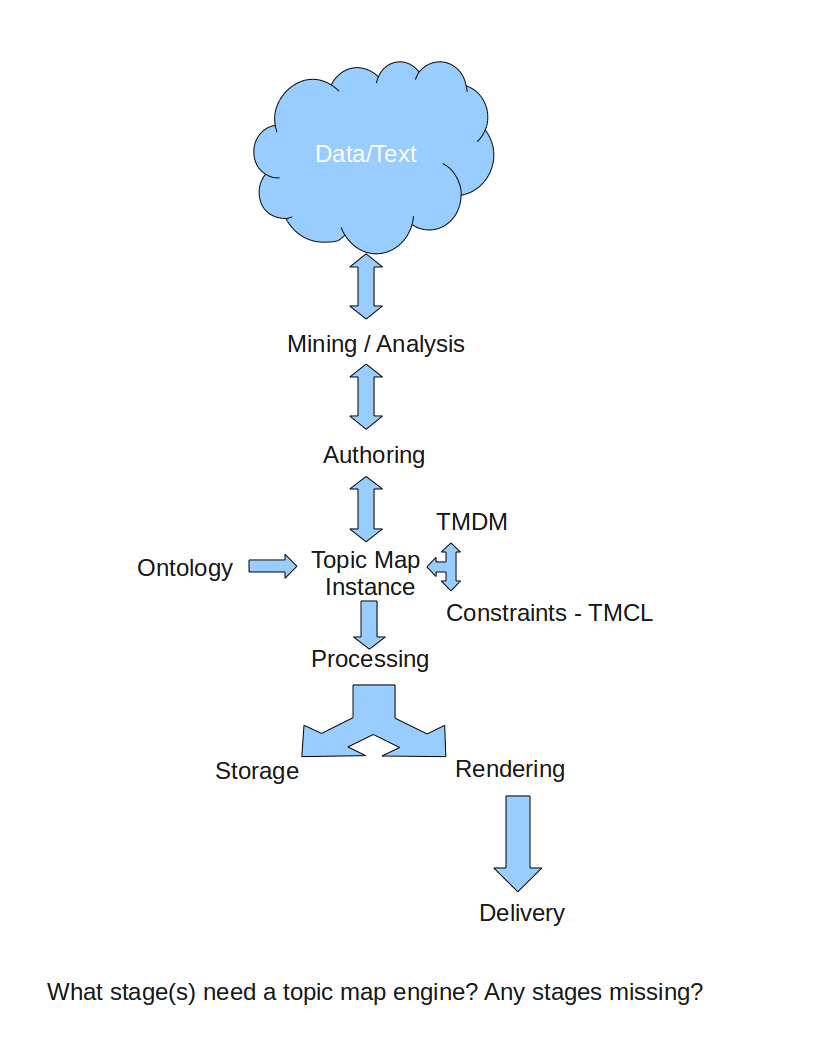
In An R function to analyze your Google Scholar Citations page I mused:
Scholars are fairly peripatetic these days and so have webpages, projects, courses, not to mention social media postings using various university identities. A topic map would be a nice complement to this function to gather up the “grey” literature that underlies final publications.
Matt O’Donnell follows that post up with a tweet asking what such a map would look like?
An example would help make the point but I did not want to choose one with a known outcome. Since I recently blogged about the Natural Language Processing being taught by Christoper Manning and Dan Jurafsky, I will use both of them as examples.
From the course description we know:
Dan Jurafsky is Professor of Linguistics and Professor by Courtesy of Computer Science at Stanford University. Dan received his Bachelors degree in Linguistics in 1983 and his Ph.D. in Computer Science in 1992, both from the University of California at Berkeley, and also taught at the University of Colorado, Boulder before joining the Stanford faculty in 2004. He is the recipient of a MacArthur Fellowship and has served on a variety of editorial boards, corporate advisory boards, and program committees. Dan’s research extends broadly throughout natural language processing as well as its application to the behavioral and social sciences.
Jurafsky has at least three (possibly more) email addresses:
- University of California at Berkley – ending somewhere in the early 1990’s
- University of Colorado, Boulder – between early 1990’s and 2004
- Stanford – starting in 2004
Just following the link in the class blurb we have: jurafsky(at)stanford.edu for his (current) email at Stanford (it may have changed, can’t say based on what we know now) and a URL to use as a subject identifier, http://www.stanford.edu/~jurafsky/.
I should make up some really difficult technique at this point for discovering prior email addresses. 😉 Some of those may be necessary but what follows is a technique that works for most academics.
We know that Jurafsky started at Stanford in 2004 and for purposes of this exercise we will assume his email at Stanford has been stable. So we need email addresses prior to 2004. At least for CS or CS related fields, the first place I would go is The DBLP Computer Science Bibliography. Choosing author search and inputting “jurafsky” I get two “hits.”
# Dan Jurafsky
# Daniel Jurafsky
You will note on the right hand side of the listing of articles, on the “Ask Others…” line, there is a text box with the value used by DBLP to conduct the search. For both “Dan Jurafsky” and “Daniel Jurafsky” it is using author:daniel_jurafsky:. That is it has regularized the name so that when you as for “Dan Jurafsky,” the search is on the longer form.
Sorry, digression. Anyway, we know we need an address for sometime prior to 2004 and scanning the publications prior to 2004, I saw the following citation:
Daniel Gildea, Daniel Jurafsky: Automatic Labeling of Semantic Roles. Computational Linguistics 28(3): 245-288 (2002)
The source in Computational Linguistics is important because if you follow the Computational Linguistics 28 link, it will take you to a listing of that article in that particular issue of Compuational Linguistics.
Oh, the icons:
 |
Link to electronic version if one exists (may be a pay-per-view site) |
 |
Searches the title as a string at CiteSeerX |
 |
Searches the title as a string at Google Scholar |
 |
Links to article if it appears in PubZone, a service of ETH Zurich in cooperation with ACM SIGMOD |
 |
The article’s citation in BibTeX format. |
 |
The article’s citation in XML. |
If you choose the first icon, it will take you to a paper by Dan Jurafsky in 2002, where his email address is listed as: jurafsky@colorado.edu. (Computational Linguistics is open access now, all issues. Reason why I suggested it first.)
You could also look at Jurafsky’s publication page and find the same paper.
Where there is a listing of publications, try there first but realize that DPLP is a valuable research tool.
The oldest paper that Jurafsky has listed:
Jurafsky, Daniel, Chuck Wooters, Gary Tajchman, Jonathan Segal, Andreas Stolcke, Eric Fosler, and Nelson Morgan. 1994. Integrating Experimental Models of Syntax, Phonology, and Accent/Dialect in a Speech Recognizer (in AAAI-94 workshop)
Gives us his old Berkeley address: jurafsky@icsi.berkeley.edu.
Updating the information we have for Jurafsky:
- University of California at Berkeley – jurafsky@icsi.berkeley.edu
- University of Colorado, Boulder – jurafsky@colorado.edu
- Stanford – jurafsky(at)stanford.edu
And his current homepage for a subject identifier: http://www.stanford.edu/~jurafsky/.
Or, in CTM notation for a topic map:
http://www.stanford.edu/~jurafsky/ # subject identifier
– “Dan Jurafsky”; # name with default type
email: jurafsky(at)stanford.edu @stanford; #occurrence with scope
email: jurafsky@colorado.edu @colorado; #occurrence with scope
email: jurafsky@icsi.berkeley.edu #icis.berkeley. #occurrence with scope, note period ending the topic “block”
I thought about and declined to use the notion of “currentEmail.” Using scopes allows for future changes in emails, while maintaining a sense of when certain email addresses were in use. Search engine policies not withstanding, the world is not a timeless place.
I have some of the results of using the Prof. Jurafsky’s prior addresses, but want to polish that up a bit before posting it.
(I will get to Christopher in the next part.)