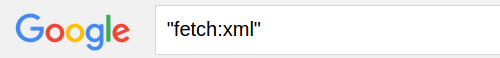Internet search rankings have a significant impact on consumer choices, mainly because users trust and choose higher-ranked results more than lower-ranked results. Given the apparent power of search rankings, we asked whether they could be manipulated to alter the preferences of undecided voters in democratic elections. Here we report the results of five relevant double-blind, randomized controlled experiments, using a total of 4,556 undecided voters representing diverse demographic characteristics of the voting populations of the United States and India. The fifth experiment is especially notable in that it was conducted with eligible voters throughout India in the midst of India’s 2014 Lok Sabha elections just before the final votes were cast. The results of these experiments demonstrate that (i) biased search rankings can shift the voting preferences of undecided voters by 20% or more, (ii) the shift can be much higher in some demographic groups, and (iii) search ranking bias can be masked so that people show no awareness of the manipulation. We call this type of influence, which might be applicable to a variety of attitudes and beliefs, the search engine manipulation effect. Given that many elections are won by small margins, our results suggest that a search engine company has the power to influence the results of a substantial number of elections with impunity. The impact of such manipulations would be especially large in countries dominated by a single search engine company.
I’m not surprised by SEME (search engine manipulation effect).
Although I would probably be more neutral and say: Search Engine Impact on Voting.
Whether you consider one result or another as the result of “manipulation” is a matter of perspective. No search engine strives to delivery “false” information to users.
Gary Anthes in Search Engine Agendas, Communications of the ACM, Vol. 59 No. 4, pages 19-21, writes:
In the novel 1984, George Orwell imagines a society in which powerful but hidden forces subtly shape peoples’ perceptions of the truth. By changing words, the emphases put on them, and their presentation, the state is able to alter citizens’ beliefs and behaviors in ways of which they are unaware.
Now imagine today’s Internet search engines did just that kind of thing—that subtle biases in search engine results, introduced deliberately or accidentally, could tip elections unfairly toward one candidate or another, all without the knowledge of voters.
That may seem an unlikely scenario, but recent research suggests it is quite possible. Robert Epstein and Ronald E. Robertson, researchers at the American Institute for Behavioral Research and Technology, conducted experiments that showed the sequence of results from politically oriented search queries can affect how users vote, especially among undecided voters, and biased rankings of search results usually go undetected by users. The outcomes of close elections could result from the deliberate tweaking of search algorithms by search engine companies, and such manipulation would be extremely difficult to detect, the experiments suggest.
…
Gary’s post is a good supplement to the original article, covering some of the volunteers who are ready to defend the rest of us from biased search results.
Or as I would put it, to inject their biases into search results as opposed to other biases they perceive as being present.
If you are more comfortable describing the search results you want presented as “fair and equitable,” etc., please do so but I prefer the honesty of naming biases as such.
Or as David Bowie once said:
Make your desired bias, direction, etc., a requirement and allow data scientists to get about the business of conveying it.
Quite by accident I discovered the relationship between courses and their texts is hidden in many (approx. 2000) campus bookstore interfaces.
If you visit a physical campus bookstore you can browse courses for their textbooks. Very useful if you are interested the subject but not taking the course.
An online LLM (master’s of taxation) flyer prompted me to check the textbooks for the course work.
A simple enough information request. Find the campus bookstore and browse by course for text listings.
Not so fast!
The online presences of over 1200 campus bookstores are delivered http://www.bkstr.com/, which offers this interface:
Another 748 campus bookstores are delivered by http://bncollege.com/, with a similar interface for textbooks:
I started this post by saying the relationship between courses and their texts is hidden, but that’s not quite right.
The relationship between a meaningless course number and its required/suggested text is visible, but the identification of a course by a numeric string is hardly meaningful to the casual observer. (read not an enrolled student)
Perhaps better to say that a meaningful identification of courses for non-enrolled students and their relationship to required/suggested texts is absent.
That is the relationship of course -> text is present, but not in a form meaningful to anyone other than a student in that course.
Considering two separate vendors across almost 2,000 bookstores deliberately obscure the course -> text relationship, who has to wonder why?
I don’t have any immediate suggestions but when I encounter systematic obscuring of information across vendors, alarm bells start to go off.
Just for completeness sake, you can get around the obscuring of the course -> text relationship by searching for syllabus LLM taxation income OR estate OR corporate or (school name) syllabus LLM taxation income OR estate OR corporate. Extract required/suggested texts from posted syllabi.
PS: If you can offer advice on bookstore interfaces suggest enabling the browsing of courses by name and linking to the required/suggested texts.
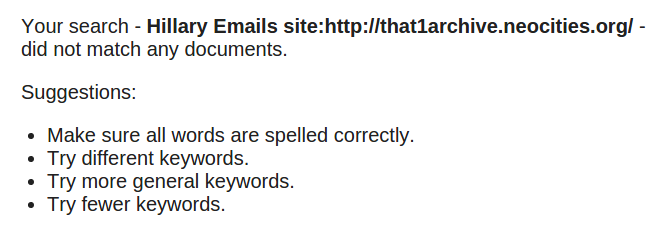
site or domain: http://that1archive.neocities.org/
Here are my results:
My first assumption was that Google simply had not updated for this “new” content. Happens. Unexpected for an important site like http://that1archive.neocities.org/, but mistakes do happen.
The most helpful part of James’ post is the graphic outline of the “process” patented by Facebook:
I sure do hope James has not patented that presentation because it make the Facebook patent, err, clear.
Quick show of hands on originality?
While researching this post, I ran across Open Source as Prior Art at the Linux Foundation. Are there other public projects that research and post prior art with regard to particular patents?
An armory of weapons for opposing ill-advised patents.
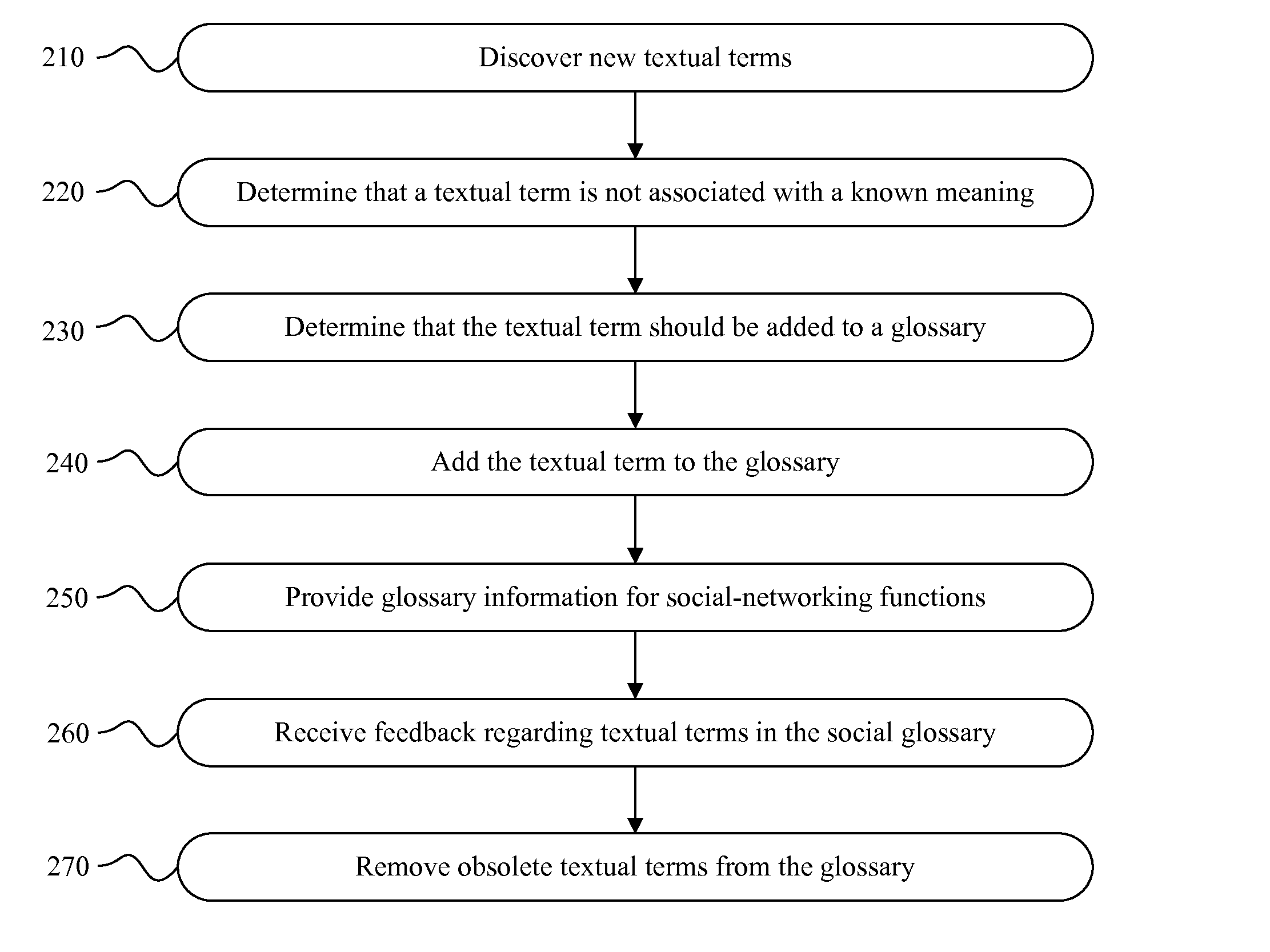
Particular embodiments determine that a textual term is not associated with a known meaning. The textual term may be related to one or more users of the social-networking system. A determination is made as to whether the textual term should be added to a glossary. If so, then the textual term is added to the glossary. Information related to one or more textual terms in the glossary is provided to enhance auto-correction, provide predictive text input suggestions, or augment social graph data. Particular embodiments discover new textual terms by mining information, wherein the information was received from one or more users of the social-networking system, was generated for one or more users of the social-networking system, is marked as being associated with one or more users of the social-networking system, or includes an identifier for each of one or more users of the social-networking system. (emphasis in original)
Comments Off on Patent Sickness Spreads [Open Source Projects on Prior Art?]
We’ve all been served up search results we weren’t sure about, whether they were for “the best tacos in town” or “how to tell if your dog has eaten chocolate.” With IBM Patent no. 9087304, you no longer have to second-guess the answers you’re given. This new tech helps cognitive machines find the best potential answers to your questions by thinking critically about the trustworthiness and accuracy of each source. Simply put, these machines can use their own judgment to separate the right information from wrong. (From: http://ibmblr.tumblr.com/post/139624929596/weve-all-been-served-up-search-results-we-werent
Did you notice that the 1st for 23 years post did not have a single link for any of the patents mentioned?
You would think IBM would be proud enough to link to its new patents and especially 9087304, that “…separate[s] right information from wrong.”
But if you follow the link for 9087304, you get an impression of one reason IBM didn’t include the link.
The abstract for 9087304 reads:
Method, computer program product, and system to perform an operation for a deep question answering system. The operation begins by computing a concept score for a first concept in a first case received by the deep question answering system, the concept score being based on a machine learning concept model for the first concept. The operation then excludes the first concept from consideration when analyzing a candidate answer and an item of supporting evidence to generate a response to the first case upon determining that the concept score does not exceed a predefined concept minimum weight threshold. The operation then increases a weight applied to the first concept when analyzing the candidate answer and the item of supporting evidence to generate the response to the first case when the concept score exceeds a predefined maximum weight threshold.
I will spare you further recitations from the patent.
Show of hands, do U.S. Patents always require:
novel/non-obvious ideas
patent fee
#2 but not #1
?
Judge rankings by # of patents granted accordingly.
Comments Off on U.S. Patents Requirements: Novel/Non-Obvious or Patent Fee?
By its very nature, breaking news happens unexpectedly. Simply waiting for something to start trending on Twitter is not an option for journalists – you’ll have to actively seek it out.
The most important rule is to switch perspectives with the eyewitness and ask yourself, “What would I tweet if I were an eyewitness to an accident or disaster?”
To find breaking news on Twitter you have to think like a person who’s experiencing something out of the ordinary. Eyewitnesses tend to share what they see unfiltered and directly on social media, usually by expressing their first impressions and feelings. Eyewitness media can include very raw language that reflects the shock felt as a result of the situation. These posts often include misspellings.
In this article, we’ll outline some search terms you can use in order to find breaking news. The list is not intended as exhaustive, but a starting point on which to build and refine searches on Twitter to find the latest information.
Great collections of starter search terms but those are going to vary depending on your domain of “breaking” news.
Good illustration of use of Twitter search operators.
Other collections of Twitter search terms?
Comments Off on How to find breaking news on Twitter
I ask about Honestsociety.com because when I search on Google with the string:
honest society member
I get 82,100,000 “hits” and the first page is entirely, honor society stuff.
No, “did you mean,” or “displaying results for…”, etc.
Not a one.
Top of the second page of results did have a webpage that mentions honestsociety.com, but not their home site.
I can’t recall seeing an Honestsociety ad with Google and thought perhaps one of you might.
Lacking such ads, my seat of the pants explanation for “honest society member” returning the non-responsive “honor society” listing isn’t very generous.
What anomalies have you observed in Google (or other) search results?
What searches would you use to test ranking in search results by advertiser with Google versus non-advertiser with Google?
Rigging Searches
For my part, it isn’t a question of whether search results are rigged or not, but rather are they rigged the way I or my client prefers?
Or to say it in a positive way: All searches are rigged. If you think otherwise, you haven’t thought very deeply about the problem.
Take library searches for example. Do you think they are “fair” in some sense of the word?
Hmmm, would you agree that the collection practices of a library will give a user an impression of the literature on a subject?
So the search itself isn’t “rigged,” but the data underlying the results certainly influences the outcome.
If you let me pick the data, I can guarantee whatever search result you want to present. Ditto for the search algorithms.
The best we can do is make our choices with regard to the data and algorithms explicit, so that others accept our “rigged” data or choose to “rig” it differently.
Comments Off on Does HonestSociety.com Not Advertise With Google? (Rigging Search Results)
Unlike some US intelligence agencies, TinEye has a cool logo:
Free registration enables you to share search results with others, an important feature for news teams.
I only tested the plugin for Chrome, but it offers useful result options:
Once installed, use by hovering over an image in your browser, right “click” and select “Search image on TinEye.” Your results will be presented as set under options.
Clue to User Topic Map Interface
That is a good example of how one version of a topic map interface should work. Select some text, right “click” and “Search topic map ….(preset or selection)” with configurable result display.
That puts you into interaction with the topic map, which can offer properties to enable you to refine the identification of a subject of interest and then a merged presentation of the results.
As with a topic map, all sorts of complicated things are happening in the background with the TinEye extension.
But as a user, I’m interested in the results that FireEye presents not how it got them.
I used to say “more interested” to indicate I might care how useful results came to be assembled. That’s a pretension that isn’t true.
It might be true in some particular case, but for the vast majority of searches, I just want the (uncensored Google) results.
US Intelligence Community Logo for Same Capability
I discovered the most likely intelligence community logo for a similar search program:
The answer to the age-old question of “who watches the watchers?” is us. Which watchers are you watching?
Comments Off on Reverse Image Search (TinEye) [Clue to a User Topic Map Interface?]
Google is, beyond question, the most utilized and highest performing search engine on the web. However, most of the users who utilize Google do not maximize their potential for getting the most accurate results from their searches.
By using Google Search Operators, you can find exactly what you are looking for quickly and effectively just by changing what you input into the search bar.
If you are searching for something simple on Google like [Funny cats] or [Francis Ford Coppola Movies] there is no need to use search operators. Google will return the results you are looking for effectively no matter how you input the words.
Note: Throughout this article whatever is in between these brackets [ ] is what is being typed into Google.
When [Francis Ford Coppola Movies] is typed into Google, Google reads the query as Francis AND Ford AND Coppola AND Movies. So Google will return pages that have all those words in them, with the most relevant pages appearing first. Which is fine when you’re searching for very broad things, but what if you’re trying to find something specific?
What happens when you’re trying to find a report on the revenue and statistics from the United States National Park System in 1995 from a reliable source, and no using Wikipedia.
…
I can’t say that Marcela’s guide is comprehensive for Google in 2016, because I am guessing the post was written in 2013. Hard to say if early or late 2013 without more research than I am willing donate. Dating posts makes it easy for readers to spot current or past-use-date information.
For the information that is present, this is a great presentation and list of operators.
One way to use this post is to work through every example but use terms from your domain.
If you are mining the web for news reporting, compete against yourself on successive stories or within a small group.
Great resource for creating a search worksheet for classes.
Comments Off on A Comprehensive Guide to Google Search Operators
These days, most everyone is familiar with the concept of crawling the web: a piece of software that systematically reads web pages and the pages they link to, traversing the world-wide web. It’s what Google does, and countless tech firms crawl web pages to accomplish tasks ranging from searches to archiving content to statistical analyses and so on. Web crawling is a task that has been automated by developers in every programming language around, many times — for example, a search for web crawling source code yields well over a million hits.
So when I recently came across a need to crawl some web pages for a project I’ve been working on, I figured I could just go find some source code online and hack it into what I need. (Quick aside: the project is a Python library for managing EXIF metadata on digital photos. More on that in a future blog post.)
But I spent a couple of hours searching and playing with the samples I found, and didn’t get anywhere. Mostly because I’m working in Python version 3, and the most popular Python web crawling code is Scrapy, which is only available for Python 2. I found a few Python 3 samples, but they all seemed to be either too trivial (not avoiding re-scanning the same page, for example) or too needlessly complex. So I decided to write my own Python 3.x web crawler, as a fun little learning exercise and also because I need one.
In this blog post I’ll go over how I approached it and explain some of the code, which I posted on GitHub so that others can use it as well.
…
Doug has been writing publicly about his hip replacement surgery so I don’t think this has any privacy issues. 😉
I am interested to see what he writes once he is fully recovered.
My contacts at the American Medical Association disavow any knowledge of hip replacement surgery driving patients to write in Python and/or to write web crawlers.
I suppose there could be liability implications, especially for C/C++ programmers who lose their programming skills except for Python following such surgery.
Still, glad to hear Doug has been making great progress and hope that it continues!
Comments Off on Previously Unknown Hip Replacement Side Effect: Web Crawler Writing In Python
There are way too many arxiv papers, so I wrote a quick webapp that lets you search and sort through the mess in a pretty interface, similar to my pretty conference format.
It’s super hacky and was written in 4 hours. I’ll keep polishing it a bit over time perhaps but it serves its purpose for me already. The code uses Arxiv API to download the most recent papers (as many as you want – I used the last 1100 papers over last 3 months), and then downloads all papers, extracts text, creates tfidf vectors for each paper, and lastly is a flask interface for searching through and filtering similar papers using the vectors.
Main functionality is a search feature, and most useful is that you can click “sort by tfidf similarity to this”, which returns all the most similar papers to that one in terms of tfidf bigrams. I find this quite useful.
As XML becomes mainstream, users expect to be able to search their XML documents. This requires a standard way to do full-text search, as well as structured searches, against XML documents. A similar requirement for full-text search led ISO to define the SQL/MM-FT [SQL/MM] standard. SQL/MM-FT defines extensions to SQL to express full-text searches providing functionality similar to that defined in this full-text language extension to XQuery 3.0 and XPath 3.0.
XML documents may contain highly structured data (fixed schemas, known types such as numbers, dates), semi-structured data (flexible schemas and types), markup data (text with embedded tags), and unstructured data (untagged free-flowing text). Where a document contains unstructured or semi-structured data, it is important to be able to search using Information Retrieval techniques such as
scoring and weighting.
Full-text search is different from substring search in many ways:
A full-text search searches for tokens and phrases rather than substrings. A substring search for news items that contain the string “lease” will return a news item that contains “Foobar Corporation releases version 20.9 …”. A full-text search for the token “lease” will not.
There is an expectation that a full-text search will support language-based searches which substring search cannot. An example of a language-based search is “find me all the news items that contain a token with the same linguistic stem as ‘mouse'” (finds “mouse” and “mice”). Another example based on token proximity is “find me all the news items that contain the tokens ‘XML’ and ‘Query’ allowing up to 3 intervening tokens”.
Full-text search must address the vagaries and nuances of language. Search results are often of varying usefulness. When you search a web site for cameras that cost less than $100, this is an exact search. There is a set of cameras that matches this search, and a set that does not. Similarly, when you do a string search across news items for “mouse”, there is only 1 expected result set. When you do a full-text search for all the news items that contain the token “mouse”, you probably expect to find news items containing the token “mice”, and possibly “rodents”, or possibly “computers”. Not all results are equal. Some results are more “mousey” than others. Because full-text search may be inexact, we have the notion of score or relevance. We generally expect to see the most relevant results at the top of the results list.
Note:
As XQuery and XPath evolve, they may apply the notion of score to querying structured data. For example, when making travel plans or shopping for cameras, it is sometimes useful to get an ordered list of near matches in addition to exact matches. If XQuery and XPath define a generalized inexact match, we expect XQuery and XPath to utilize the scoring framework provided by XQuery and XPath Full Text 3.0.
Definition: Full-text queries are performed on tokens and phrases. Tokens and phrases are produced via tokenization.] Informally, tokenization breaks a character string into a sequence of tokens, units of punctuation, and spaces.
Tokenization, in general terms, is the process of converting a text string into smaller units that are used in query processing. Those units, called tokens, are the most basic text units that a full-text search can refer to. Full-text operators typically work on sequences of tokens found in the target text of a search. These tokens are characterized by integers that capture the relative position(s) of the token inside the string, the relative position(s) of the sentence containing the token, and the relative position(s) of the paragraph containing the token. The positions typically comprise a start and an end position.
Tokenization, including the definition of the term “tokens”, SHOULD be implementation-defined. Implementations SHOULD expose the rules and sample results of tokenization as much as possible to enable users to predict and interpret the results of tokenization. Tokenization operates on the string value of an item; for element nodes this does not include the content of attribute nodes, but for attribute nodes it does. Tokenization is defined more formally in 4.1 Tokenization.
[Definition: A token is a non-empty sequence of characters returned by a tokenizer as a basic unit to be searched. Beyond that, tokens are implementation-defined.] [Definition: A phrase is an ordered sequence of any number of tokens. Beyond that, phrases are implementation-defined.]
…
Not a fast read but a welcome one!
XQuery and XPath increase the value of all XML-encoded documents, at least down to the level of their markup. Beyond nodes, you are on your own.
XQuery and XPath Full Text 3.0 extend XQuery and XPath beyond existing markup in documents. Content that was too expensive or simply not of enough interest to encode, can still be reached in a robust and reliable way.
If you can “see” it with your computer, you can annotate it.
You might have to possess a copy of the copyrighted content, but still, it isn’t a closed box that resists annotation. Enabling you to sell the annotation as a value-add to the copyrighted content.
XQuery and XPath Full Text 3.0 says token and phrase are implementation defined.
Imagine the user (name) commented version of X movie, which is a driver file that has XQuery links into DVD playing on your computer (or rather to the data stream).
I rather like that idea.
PS: Check with a lawyer before you commercialize that annotation idea. I am not familiar with all EULAs and national laws.
Comments Off on XQuery and XPath Full Text 3.0 (Recommendation)
Anyone interested in categorizing them? It could be an interesting data science project, scraping these websites, extracting keywords, and categorizing them with a simple indexation or tagging algorithm. For instance, some of these blogs cater about stats, or Bayesian stats, or R libraries, or R training, or visualization, or anything else. This indexation technique was used here to classify 2,500 data science websites. For web crawling tutorials, click here or here.
BTW, Laetitia lists, with links, all 600 R sites.
How many of those R sites will you visit?
Or will you scan the list for your site or your favorite R site?
For that matter, how duplicated content are you going to find at those R sites?
All have some unique content, but neither an index nor classification will help you find unique content.
Thinking of this as a potential data science experiment, we have a list of 600 sites with content related to R.
What would be your next step towards avoiding duplicated content?
By what criteria would you judge “success” in avoiding duplicate content?
Comments Off on 600 websites about R [How to Avoid Duplicate Content?]
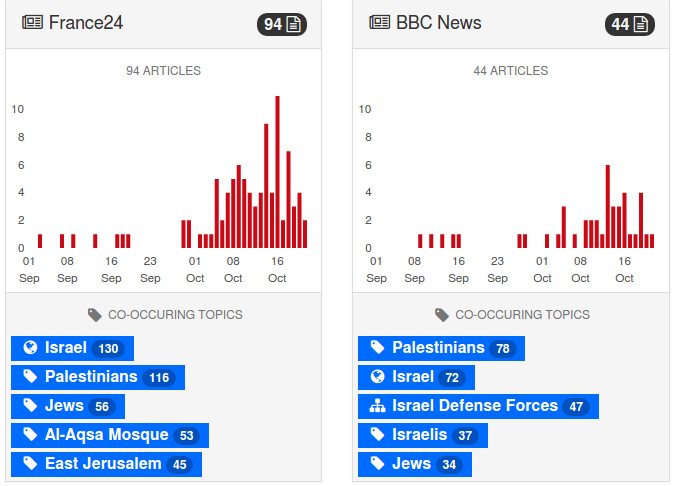
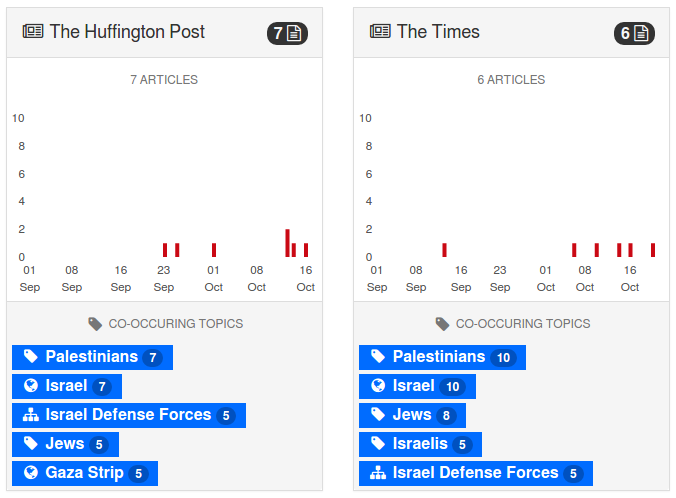
Imagine comparing the coverage of news feeds from approximately 350 sources (you choose), with granular date ranges (instead of last 24 hours, last week, last month, last year) plus, “…AND, OR, NOT and parenthesis in queries.” The interface shows co-occurring topics as well.
BBC New Labs did more than +1! a great idea, they implemented it and posted their code.
From the webpage:
Inspired by a concept created by Adam Ramsay, Zoe Blackler & Iain Collins at the Center for Investigative Reporting design sprint on Climate Change
Implementation by Iain Collins and Sylvia Tippmann, using data from the BBC News Labs Juicer | View Source
What conclusions would you draw from reports starting September 1, 2015 to date, “violence AND Israel?”
One story only illustrates the power of this tool to create comparisons between news sources. Drawing conclusions about news sources requires systematic study of sources across a range of stories. The ability to do precisely that has fallen into your lap.
Everyone has an opinion about “political correctness,” but did you know that Google has “search correctness?”
This morning I was attempting, unsuccessfully, to search for:
Here is a screen shot of my results:
I happen to know that “fetch:xml” is an actual string in Google indexed documents because it was a Google search that found the page (using other search terms) where that string exists!
I wanted to search beyond that page for other instances of “fetch:xml.” Surprise, surprise.
Prior to posting this, as a sanity check, I searched for “dc:title.” And got hits!? What’s going on?
If you look at: Metatags.org, you will find them using:
DC.title, DC.creator, etc. Replacing the “:” (colon) with a “.” (period).
That solution is a non-starter for me because I have no control over how other people report fetch:xml. One assumes they will use the same string as appears in the documentation.
As annoying as this is, perhaps it is the solution to the EU’s right to be forgotten problem.
People who want to be forgotten can change their names to punctuation that Google does not index.
Once their names are entirely punctuation, these shy individuals will never be found in a Google search.
Works across the globe with no burden on search engine operators.
Comments Off on Search Correctness? [Right to be Forgotten, Hiding in Plain Sight]
One of the features we wanted to see in Scumblr was the ability to collect screenshots and text content from potentially malicious sites – this allows security analysts to preview Scumblr results without the risk of visiting the site directly. We wanted this collection system to be isolated from Scumblr and also resilient to sites that may perform malicious actions. We also decided it would be nice to build an API that we could use in other applications outside of Scumblr.
Although a variety of tools and frameworks exist for taking screenshots, we discovered a number of edge cases that made taking reliable screenshots difficult – capturing screenshots from AJAX-heavy sites, cut-off images with virtual X drivers, and SSL and compression issues in the PhantomJS driver for Selenium, to name a few. In order to solve these challenges, we decided to leverage the best possible tools and create an API framework that would allow for reliable, scalable, and easy to use screenshot and text scraping capabilities. Sketchy to the rescue!
If like me, you missed the Ashley Madison dump to an .onion site on Tuesday, 18 August 2015, one that is now thought to be authentic, you need a tool like Scumblr!
From the Netflix description of Scumblr:
What is Scumblr?
Scumblr is a web application that allows performing periodic searches and storing / taking actions on the identified results. Scumblr uses the Workflowable gem to allow setting up flexible workflows for different types of results.
How do I use Scumblr?
Scumblr is a web application based on Ruby on Rails. In order to get started, you’ll need to setup / deploy a Scumblr environment and configure it to search for things you care about. You’ll optionally want to setup and configure workflows so that you can track the status of identified results through your triage process.
What can Scumblr look for?
Just about anything! Scumblr searches utilize plugins called Search Providers. Each Search Provider knows how to perform a search via a certain site or API (Google, Bing, eBay, Pastebin, Twitter, etc.). Searches can be configured from within Scumblr based on the options available by the Search Provider. What are some things you might want to look for? How about:
Compromised credentials
Vulnerability / hacking discussion
Attack discussion
Security relevant social media discussion
…
These are just a few examples of things that you may want to keep an eye on!
Scumblr found stuff, now what?
Up to you! You can create simple or complex workflows to be used along with your results. This can be as simple as marking results as “Reviewed” once they’ve been looked at, or much more complex involving multiple steps with automated actions occurring during the process.
Sounds great! How do I get started?
Take a look at the wiki for detailed instructions on setup, configuration, and use!
This looks particularly useful if you are watching for developments and/or discussions in software forums, blogs, etc.
The Internet is full of fascinating information. While getting lost can sometimes be entertaining, most people still prefer somewhat guided surfing excursions. It’s always great to find new websites that can help out and be useful in one way or another.
Here are a few of our favorites.
Thomas does a great job of collecting, the links/tools run from odd, photos taken at the same location but years later (haven’t they heard of Photoshop?), to notes that self destruct after being read.
Remember for the self-destroying notes that bytes did cross the Internet to arrive. Capturing them sans the self-destruction method is probably a freshman exercise at better CS programs.
My problem is that my bookmark list probably has hundreds of useful links, if I could just remember which subjects they were associated with and was able to easily retrieve them. Yes, the cobbler’s child with no shoes.
These days, every company knows that having its website appear at the top of Google’s results for relevant keyword searches makes a big difference in traffic and helps the business. Numerous search engine optimization (SEO) techniques have existed for years and provided marketers with ways to climb up the PageRank ladder.
In a nutshell, to be popular with Google, your website has to provide content relevant to specific search keywords and also to be linked to by a high number of reputable and relevant sites. (These act as recommendations, and are rather confusingly known as “back links,” even though it’s not your site that is doing the linking.)
Google’s algorithms are much more complex than this simple description, but most of the optimization techniques still revolve around those two goals. Many of the optimization techniques that are being used are legitimate, ethical and approved by Google and other search providers. But there are also other, and at times more effective, tricks that rely on various forms of internet abuse, with attempts to fool Google’s algorithms through forgery, spam and even hacking.
One of the techniques used to mislead Google’s page indexer is known as cloaking. A few days ago, we identified what we believe is a new type of cloaking that appears to work very well in bypassing Google’s defense algorithms.
…
Dmitry reports that Google was notified of this new form of cloaking so it may be work for much longer.
I’m not sure I would characterize this as “poisoning Google search.” Altering a Google search result to be sure but poisoning implies that standard Google search results represent some “standard” of search results. Google search results are the outcome of undisclosed algorithms run on undisclosed content, subject to undisclosed processing of the scores from processing content with algorithms, and output with more undisclosed processing of the results.
Just putting it into large containers, I see four large boxes of undisclosed algorithms and content, all of which impact the results presented as Google Search results. Are Google Search results the standard output from four or more undisclosed processing steps of unknown complexity?
That doesn’t sound like much of a standard to me.
You?
Comments Off on Google search poisoning – old dogs learn new tricks
Before the end of this year, HuffPost will release new tech and a new app, opening the floodgates for contributors. The goal: Add 900,000 contributors to Huffington Post’s 100,000 current ones. Yes, one million in total.
How fast would Arianna like that to get that number?
“One day,” she joked, as we discussed her latest project, code-named Donatello for the Renaissance sculptor. Lots of people got to be Huffington Post contributors through Arianna Huffington. They’d meet her at book signing, send an email and find themselves hooked up. “It’s one of my favorite things,” she told me Thursday. Now, though, that kind of retail recruitment may be a vestige.
“It’s been an essential part of our DNA,” she said, talking about the user contributions that once seemed to outnumber the A.P. stories and smaller original news staff’s work. “We’ve always been a hybrid platform,” a mix of pros and contributors.
So what enables the new strategy? Technology, naturally.
HuffPost’s new content management system is now being extended to work as a self-publishing platform as well. It will allow contributors to post directly from their smartphones, and add in video. Behind the scenes, a streamlined approval system is intended to reduce human (editor) intervention. Get approved once, then publish away, “while preserving the quality,” Huffington added.
…
Adding another 900,000 contributors to the Huffington Post is going to bump their content production substantially.
So, here’s the question: Searching the Huffington Post site is as bad as most other media sites. What is adding content from another 900,000 contributors going to do for that experience? Get worse? That’s my first bet.
On the other hand, what if authors can unknowingly create topic maps? For example, auto-tagging offers Wikipedia links (one or more) for an entity in a story, for relationships, a drop down menu with roles for the major relationship types (slept-with being available for inside the Beltway), with auto-generated relationships to the author, events mentioned, other content at the Huffington Post.
Don’t solve the indexing/search problem after the fact, create smarter data up front. Promote the content with better tagging and relationships. With 1 million unpaid contributors trying to get their contributions noticed, a win-win situation.
Comments Off on One Million Contributors to the Huffington Post
When Gabriel Weinberg launched a new search engine in 2008 I doubt even he thought it would gain any traction in an online world dominated by Google.
Now, seven years on, Philadelphia-based startup DuckDuckGo – a search engine that launched with a promise to respect user privacy – has seen a massive increase in traffic, thanks largely to ex-NSA contractor Edward Snowden’s revelations.
Since Snowden began dumping documents two years ago, DuckDuckGo has seen a 600% increase in traffic (but not in China – just like its larger brethren, its blocked there), thanks largely to its unique selling point of not recording any information about its users or their previous searches.
Such a huge rise in traffic means DuckDuckGo now handles around 3 billion searches per year.
…
DuckDuckGodoes not track its users. Instead, it makes money off of displaying key word (from your search string) based ads.
Hmmm, what if instead of key words from your search string, you pre-qualified yourself for ads?
Say for example I have a topic map fragment that pre-qualifies me for new books on computer science, break baking, and waxed dental floss. When I use a search site, it uses those “topics” or key words to display ads to me.
That avoids displaying to me ads for new cars (don’t own one, don’t want one), hair replacement ads (not interested) and ski resorts (don’t ski).
Advertisers benefit because their ads are displayed to people who have qualified themselves as interested in their products. I don’t know what the difference in click-through rate would be but I suspect it would be substantial.
Thoughts?
Comments Off on DuckDuckGo search traffic soars 600% post-Snowden
Today WikiLeaks has released more than half a million US State Department cables from 1978. The cables cover US interactions with, and observations of, every country.
1978 was an unusually important year in geopolitics. The year saw the start of a great many political conflicts and alliances which continue to define the present world order, as well as the rise of still-important personalities and political dynasties.
The cables document the start of the Iranian Revolution, leading to the stand-off between Iran and the West (1979 – present); the Second Oil Crisis; the Afghan conflict (1978 – present); the Lebanon–Israel conflict (1978 – present); the Camp David Accords; the Sandinista Revolution in Nicaragua and the subsequent conflict with US proxies (1978 – 1990); the 1978 Vietnamese invasion of Cambodia; the Ethiopian invasion of Eritrea; Carter’s critical decision on the neutron bomb; the break-up of the USSR’s nuclear-powered satellite over Canada, which changed space policy; the US “playing the China card” against Russia; Brzezinski’s visit to China, which led to the subsequent normalisation of relations and a proxy war in Cambodia; with the US, UK, China and Cambodia on one side and Vietnam and the USSR on the other.
Through 1978, Zbigniew “Zbig” Brzezinski was US National Security Advisor. He would become the architect of the destabilisation of Soviet backed Afghanistan through the use of Islamic militants, elements of which would later become known as al-Qaeda. Brzezinski continues to affect US policy as an advisor to Obama. He has been especially visible in the recent conflict between Russia and the Ukraine.
WikiLeaks’ Carter Cables II comprise 500,577 US diplomatic cables and other diplomatic communications from and to US embassies and missions in nearly every country. It follows on from the Carter Cables (368,174 documents from 1977), which WikiLeaks published in April 2014.
The Carter Cables II bring WikiLeaks total published US diplomatic cable collection to 2.7 million documents.
…
The Kissinger Cables : 1,707,500 diplomatic cables from 1973 to 1976
The Carter Cables : 367,174 diplomatic cables from 1977
The Carter Cables 2 : 500,577 diplomatic cables from 1978
Cablegate : 251,287 diplomatic cables, nearly all from 2003 to 2010
Keywords : Search for a word in the document text or its header
Subject:only Keywords Search for a word in the document subject line
Concepts Keywords of subjects dealt with in the document
Traffic Analysis by Geography and Subject (TAGS) : There are geographic, organization and subject “TAGS” : the classification system implemented by the Department of State for its central files in 1973
From : Who/where sent the document
To : Who/where received the document
Office Origin : Which State Department office or bureau sent the document
Office Action : Which State Department office or bureau received the document
Original Classification : Classification the document was originally given when produced
Handling Restrictions : All handling restrictions governing the document distribution that have been used to date
Advanced Search Features
Current Classification: Classification the document currently holds
Markings: Markings of declassification/release review of the document
Type: Correspondence type or format of original document
Enclosure: Attachments or other items sent with the original document These are not necessarily currently held in this library
Archive Status: Original documents not deleted or lost by State Department after review are available in one of four formats:
Locator: Where the original document is now held online or on microfilm, or remains in “ADS” (State Department’s 1973 Automated Data System of indexing by TAGS of electronic telegrams and Preels) with the text either garbled, not converted or unretrievable
Character Count : The number of characters, including spaces, in the document
Date : Document date range of the search
Sort by : Date, oldest first; Date, newest first; Relevance; Random; Length, largest first; Length, smallest first
Great for historical research into yesteryear’s disputes.
Not so great for current government transparency.
The crimes and poor decision making of elected officials and their appointees need to be disclosed in time to hold them accountable. (Say dumps every ninety (90) days, uncensored by Wikileaks or the New York Times.)
Comments Off on WikiLeaks releases more than half a million US diplomatic cables from 1978
Online research is often a challenge. Information from the web can be fake, biased, incomplete, or all of the above.
Offline, too, there is no happy hunting ground with unbiased people or completely honest authorities. In the end, it all boils down to asking the right questions, digital or not. Here are some strategic tips and tools for digitizing three of the most asked questions: who, where and when? They all have in common that you must “think like the document” you search.
…
Whether you are writing traditional news, blogging or writing a topic map, its difficult to think of a subject where “who, where, and when,” aren’t going to come up.
Great tips! Start of a great one pager to keep close at hand.
Comments Off on 10 Expert Search Tips for Finding Who, Where, and When
If you read my last post, you know that this semester I engaged in building a Bookworm using a government document collection. My professor challenged me to try my system for parsing the documents on a different, larger collection of government documents. The collection I chose to work with is the Official Records of the Union and Confederate Navies. My Barbary Bookworm took me all semester to build; this Civil War navies Bookworm took me less than a day. I learned things from making the first one!
This collection is significantly larger than the Barbary Wars collection—26 volumes, as opposed to 6. It encompasses roughly the same time span, but 13 times as many words. Though it is still technically feasible to read through all 26 volumes, this collection is perhaps a better candidate for distant reading than my first corpus.
The document collection is broken into geographical sections, the Atlantic Squadron, the West Gulf Blockading Squadron, and so on. Using the Bookworm allows us to look at the words in these documents sequentially by date instead of having to go back and forth between different volumes to get a sense of what was going on in the whole navy at any given time.
…
In this project we develop new methods for simple literature search that works on any catalogs, without requiring in-depth knowledge of the metadata schema. The system helps users proactively and unobtrusively by guessing at each step what the user’s real information need is and providing precise suggestions.
Lex Machina—Latin that translates to “law machine”—is an interesting name for a legal analytics platform that focuses not on the law itself but on providing insights into the human aspects of the practice of law. While traditional legal research platforms—Lexis, Westlaw, Bloomberg, etc.—help guide attorneys to information about where the law is and how it is developing, Lex Machina focuses on providing information about how attorneys, judges, and other involved parties act in the high-stakes world of IP litigation.
Leveraging databases from PACER, the USPTO, and the ITC, Lex Machina cleans and codes millions of data elements from IP-related legal filings to cull information about how judges, attorneys, law firms, and particular patents are treated in various cases. Using that information, Lex Machina is able to offer insights into, for example, how long a particular judge typically takes to decide on summary judgment motions, or how frequently a particular judge grants early motions in favor of defendants. Law firms use the service to create client pitches—highlighting with hard data, for example, how many times they have litigated and won particular types of cases before particular judges or courts as compared to competing law firms. And companies can use the service to assess the historical effectiveness of their counsel and to judge the reasonableness of proposed litigation strategies.
If you are interested in gaining access to Lex Machina and are university and college faculty, staff or students directly engaged in research on, or study of, IP law and policy, you can request a free public-interest account here (Lex Machina notes, however, “to enable public interest users to make best use of Lex Machina, we require prospective new users to attend an online training prior to receiving a user account.”)
When I first wrote about Lex Machina (2013), I don’t recall there being a public interest option. Amusing to see its use as a form of verified advertising for attorneys.
Now, if judicial oversight boards had the same type of information across the board for all judges.
Not that legal outcomes can or should be uniform, but they shouldn’t be freakish as well.