Counting Citations in U.S. Law by Gary Sieling.
From the post:
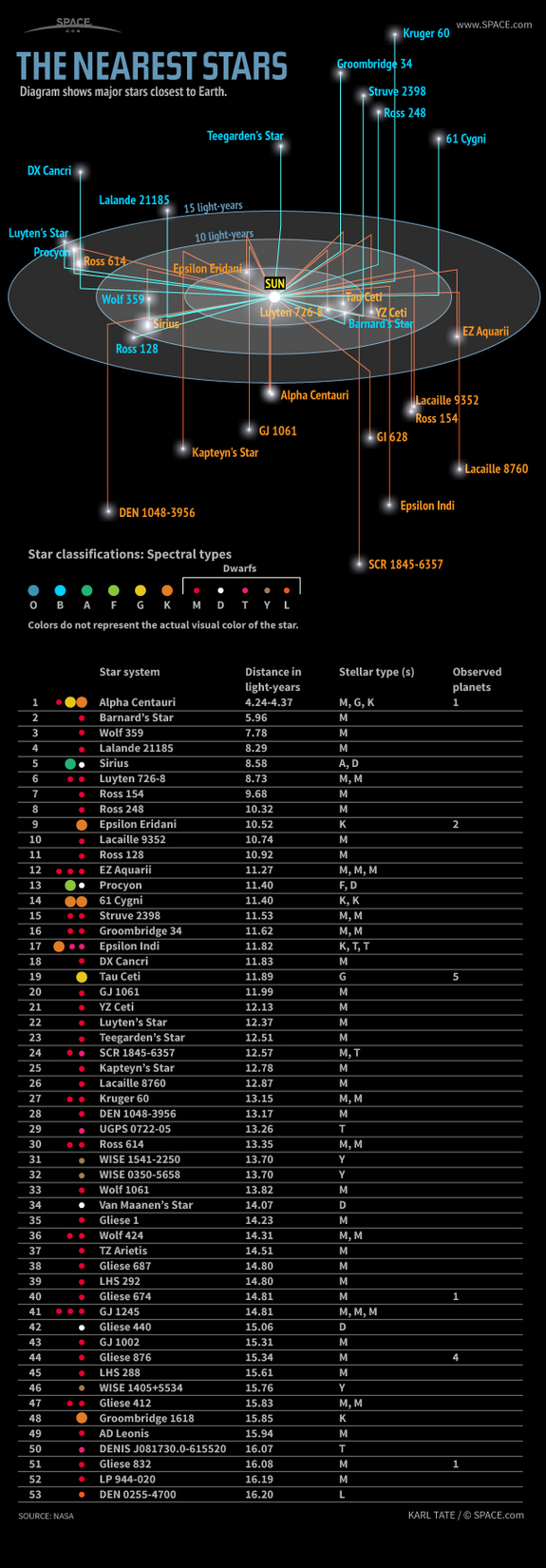
The U.S. Congress recently released a series of XML documents containing U.S. Laws. The structure of these documents allow us to find which sections of the law are most commonly cited. Examining which citations occur most frequently allows us to see what Congress has spent the most time thinking about.
Citations occur for many reasons: a justification for addition or omission in subsequent laws, clarifications, or amendments, or repeals. As we might expect, the most commonly cited sections involve the IRS (Income Taxes, specifically), Social Security, and Military Procurement.
To arrive at this result, we must first see how U.S. Code is laid out. The laws are divided into a hierarchy of units, which allows anything from an entire title to individual sentences to cited. These sections have an ID and an identifier – “identifier” is used an an citation reference within the XML documents, and has a different form from the citations used by the legal community, comes in a form like “25 USC Chapter 21 § 1901″.
If you are interested in some moderate XML data processing, this is the project for you!
Gary has posted the code for developing a citation index to the U.S. Laws in XML.
If you want to skip to one great result of this effort, see: Visualizing Citations in U.S. Law, also by Gary, which is based on d3.js and Uber Data visualization.
In the “Visualizing” post Gary enables the reader to see what laws (by title) cite other titles in U.S. law.
More interesting that you would think.
Take Title 26, Internal Revenue Code (IRC).
Among others, the IRC does not cite:
Title 30 – MINERAL LANDS AND MINING
Title 31 – MONEY AND FINANCE
Title 32 – NATIONAL GUARD
I can understand not citing the NATIONAL GUARD but MONEY AND FINANCE?
Looking forward to more ways to explore the U.S. Laws.
Tying legislative history of laws to say New York Times stories on the subject matter of a law could prove to be very interesting.
I started to suggest tracking donations to particular sponsors and then to legislation that benefits the donors.
But that level of detail is just a distraction. Most elected officials have no shame at selling their offices. Documenting their behavior may regularize pricing of senators and representatives but not have much other impact.
I suggest you find a button other than truth to influence their actions.
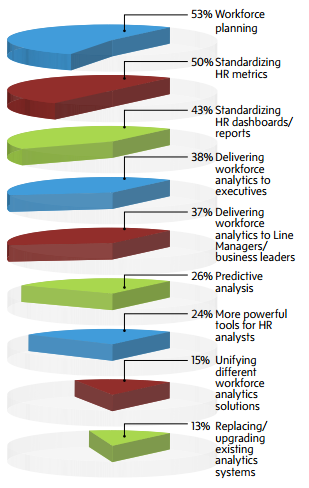
 by Randy Krum.
by Randy Krum.