We study the classic online learning problem of predicting with expert advice, and propose a truly parameter-free and adaptive algorithm that achieves several objectives simultaneously without using any prior information. The main component of this work is an improved version of the NormalHedge.DT algorithm (Luo and Schapire, 2014), called AdaNormalHedge. On one hand, this new algorithm ensures small regret when the competitor has small loss and almost constant regret when the losses are stochastic. On the other hand, the algorithm is able to compete with any convex combination of the experts simultaneously, with a regret in terms of the relative entropy of the prior and the competitor. This resolves an open problem proposed by Chaudhuri et al. (2009) and Chernov and Vovk (2010). Moreover, we extend the results to the sleeping expert setting and provide two applications to illustrate the power of AdaNormalHedge: 1) competing with time-varying unknown competitors and 2) predicting almost as well as the best pruning tree. Our results on these applications significantly improve previous work from different aspects, and a special case of the first application resolves another open problem proposed by Warmuth and Koolen (2014) on whether one can simultaneously achieve optimal shifting regret for both adversarial and stochastic losses.
The terminology, “sleeping expert,” is particularly amusing.
Probably more correct to say “unpaid expert, because unpaid experts, the cleverer ones, don’t offer advice.
Machine learning is the branch of computer science concerned with the development of algorithms which can be trained by previously-seen data in order to make predictions about future data. It has become an important aspect of work in a variety of applications: from optimization of web searches, to financial forecasts, to studies of the nature of the Universe.
This tutorial will explore machine learning with a hands-on introduction to the scikit-learn package. Beginning from the broad categories of supervised and unsupervised learning problems, we will dive into the fundamental areas of classification, regression, clustering, and dimensionality reduction. In each section, we will introduce aspects of the Scikit-learn API and explore practical examples of some of the most popular and useful methods from the machine learning literature.
The strengths of scikit-learn lie in its uniform and well-document interface, and its efficient implementations of a large number of the most important machine learning algorithms. Those present at this tutorial will gain a basic practical background in machine learning and the use of scikit-learn, and will be well poised to begin applying these tools in many areas, whether for work, for research, for Kaggle-style competitions, or for their own pet projects.
If you need a self-paced machine learning course, consider your wish as granted!
From the description:
Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI. In this class, you will learn about the most effective machine learning techniques, and gain practice implementing them and getting them to work for yourself. More importantly, you’ll learn about not only the theoretical underpinnings of learning, but also gain the practical know-how needed to quickly and powerfully apply these techniques to new problems. Finally, you’ll learn about some of Silicon Valley’s best practices in innovation as it pertains to machine learning and AI. This course provides a broad introduction to machine learning, datamining, and statistical pattern recognition. Topics include: (i) Supervised learning (parametric/non-parametric algorithms, support vector machines, kernels, neural networks). (ii) Unsupervised learning (clustering, dimensionality reduction, recommender systems, deep learning). (iii) Best practices in machine learning (bias/variance theory; innovation process in machine learning and AI). The course will also draw from numerous case studies and applications, so that you’ll also learn how to apply learning algorithms to building smart robots (perception, control), text understanding (web search, anti-spam), computer vision, medical informatics, audio, database mining, and other areas.
Great if your schedule/commitments varies from week to week, take the classes at your own pace!
Same great content that has made this course such a winner for Coursera.
Since I posted a postmortem of my entry to Kaggle's See Click Fix competition, I've meant to keep sharing things that I learn as I improve my machine learning skills. One that I've been meaning to share is scikit-learn's pipeline module. The following is a moderately detailed explanation and a few examples of how I use pipelining when I work on competitions.
The pipeline module of scikit-learn allows you to chain transformers and estimators together in such a way that you can use them as a single unit. This comes in very handy when you need to jump through a few hoops of data extraction, transformation, normalization, and finally train your model (or use it to generate predictions).
When I first started participating in Kaggle competitions, I would invariably get started with some code that looked similar to this:
Often, this would yield a pretty decent score for a first submission. To improve my ranking on the leaderboard, I would try extracting some more features from the data. Let's say in instead of text n-gram counts, I wanted tf–idf. In addition, I wanted to include overall essay length. I might as well throw in misspelling counts while I'm at it. Well, I can just tack those into the implementation of extract_features. I'd extract three matrices of features–one for each of those ideas and then concatenate them along axis 1. Easy.
…
Zac has quite a bit of practical advice for how to improve your use of scikit-learn. Just what you need to start a week in the Spring!
The National Data Science Bowl, a data science competition where the goal was to classify images of plankton, has just ended. I participated with six other members of my research lab, the Reservoir lab of prof. Joni Dambre at Ghent University in Belgium. Our team finished 1st! In this post, we’ll explain our approach.
The ≋ Deep Sea ≋ team consisted of Aäron van den Oord, Ira Korshunova, Jeroen Burms, Jonas Degrave, Lionel Pigou, Pieter Buteneers and myself. We are all master students, PhD students and post-docs at Ghent University. We decided to participate together because we are all very interested in deep learning, and a collaborative effort to solve a practical problem is a great way to learn.
There were seven of us, so over the course of three months, we were able to try a plethora of different things, including a bunch of recently published techniques, and a couple of novelties. This blog post was written jointly by the team and will cover all the different ingredients that went into our solution in some detail.
This blog post is going to be pretty long! Here’s an overview of the different sections. If you want to skip ahead, just click the section title to go there.
The goal of the competition was to classify grayscale images of plankton into one of 121 classes. They were created using an underwater camera that is towed through an area. The resulting images are then used by scientists to determine which species occur in this area, and how common they are. There are typically a lot of these images, and they need to be annotated before any conclusions can be drawn. Automating this process as much as possible should save a lot of time!
The images obtained using the camera were already processed by a segmentation algorithm to identify and isolate individual organisms, and then cropped accordingly. Interestingly, the size of an organism in the resulting images is proportional to its actual size, and does not depend on the distance to the lens of the camera. This means that size carries useful information for the task of identifying the species. In practice it also means that all the images in the dataset have different sizes.
Participants were expected to build a model that produces a probability distribution across the 121 classes for each image. These predicted distributions were scored using the log loss (which corresponds to the negative log likelihood or equivalently the cross-entropy loss).
This loss function has some interesting properties: for one, it is extremely sensitive to overconfident predictions. If your model predicts a probability of 1 for a certain class, and it happens to be wrong, the loss becomes infinite. It is also differentiable, which means that models trained with gradient-based methods (such as neural networks) can optimize it directly – it is unnecessary to use a surrogate loss function.
Interestingly, optimizing the log loss is not quite the same as optimizing classification accuracy. Although the two are obviously correlated, we paid special attention to this because it was often the case that significant improvements to the log loss would barely affect the classification accuracy of the models.
This rocks!
Code is coming soon to Github!
Certainly of interest to marine scientists but also to anyone in bio-medical imaging.
The problem of too much data and too few experts is a common one.
What I don’t recall seeing are releases of pre-trained classifiers. Is the art developing too quickly for that to be a viable product? Just curious.
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image classification, localization and detection. Recent developments in neural network (aka “deep learning”) approaches have greatly advanced the performance of these state-of-the-art visual recognition systems. This course is a deep dive into details of the deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification. During the 10-week course, students will learn to implement, train and debug their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. The final assignment will involve training a multi-million parameter convolutional neural network and applying it on the largest image classification dataset (ImageNet). We will focus on teaching how to set up the problem of image recognition, the learning algorithms (e.g. backpropagation), practical engineering tricks for training and fine-tuning the networks and guide the students through hands-on assignments and a final course project. Much of the background and materials of this course will be drawn from the ImageNet Challenge.
Be sure to check out the course notes!
A very nice companion for your DIGITS experiments over the weekend.
The hottest area in machine learning today is Deep Learning, which uses Deep Neural Networks (DNNs) to teach computers to detect recognizable concepts in data. Researchers and industry practitioners are using DNNs in image and video classification, computer vision, speech recognition, natural language processing, and audio recognition, among other applications.
The success of DNNs has been greatly accelerated by using GPUs, which have become the platform of choice for training these large, complex DNNs, reducing training time from months to only a few days. The major deep learning software frameworks have incorporated GPU acceleration, including Caffe, Torch7, Theano, and CUDA-Convnet2. Because of the increasing importance of DNNs in both industry and academia and the key role of GPUs, last year NVIDIA introduced cuDNN, a library of primitives for deep neural networks.
Today at the GPU Technology Conference, NVIDIA CEO and co-founder Jen-Hsun Huang introduced DIGITS, the first interactive Deep Learning GPU Training System. DIGITS is a new system for developing, training and visualizing deep neural networks. It puts the power of deep learning into an intuitive browser-based interface, so that data scientists and researchers can quickly design the best DNN for their data using real-time network behavior visualization. DIGITS is open-source software, available on GitHub, so developers can extend or customize it or contribute to the project.
Apologies for the delay in seeing Allison’s post but at least I saw it before the weekend!
In addition to a great write-up, Allison walks through how she has used DIGITS. In terms of “onboarding” to software, it doesn’t get any better than this.
Hi there, I'm a CS PhD student at Stanford. I've worked on Deep Learning for a few years as part of my research and among several of my related pet projects is ConvNetJS – a Javascript library for training Neural Networks. Javascript allows one to nicely visualize what's going on and to play around with the various hyperparameter settings, but I still regularly hear from people who ask for a more thorough treatment of the topic. This article (which I plan to slowly expand out to lengths of a few book chapters) is my humble attempt. It's on web instead of PDF because all books should be, and eventually it will hopefully include animations/demos etc.
My personal experience with Neural Networks is that everything became much clearer when I started ignoring full-page, dense derivations of backpropagation equations and just started writing code. Thus, this tutorial will contain very little math (I don't believe it is necessary and it can sometimes even obfuscate simple concepts). Since my background is in Computer Science and Physics, I will instead develop the topic from what I refer to as hackers's perspective. My exposition will center around code and physical intuitions instead of mathematical derivations. Basically, I will strive to present the algorithms in a way that I wish I had come across when I was starting out.
"…everything became much clearer when I started writing code."
You might be eager to jump right in and learn about Neural Networks, backpropagation, how they can be applied to datasets in practice, etc. But before we get there, I'd like us to first forget about all that. Let's take a step back and understand what is really going on at the core. Lets first talk about real-valued circuits.
…
I won’t say you don’t need to more formal methods as well but everyone learns in different ways. If doing the code first is better for you, here’s a treatment of deep learning from that perspective.
The last comments were approximately four (4) months ago. I am hopeful this work will continue.
We present hybrid crowd-machine learning classifiers: classification models that start with a written description of a learning goal, use the crowd to suggest predictive features and label data, and then weigh these features using machine learning to produce models that are accurate and use human-understandable features. These hybrid classifiers enable fast prototyping of machine learning models that can improve on both algorithm performance and human judgment, and accomplish tasks where automated feature extraction is not yet feasible. Flock, an interactive machine learning platform, instantiates this approach. To generate informative features, Flock asks the crowd to compare paired examples, an approach inspired by analogical encoding. The crowd’s efforts can be focused on specific subsets of the input space where machine-extracted features are not predictive, or instead used to partition the input space and improve algorithm performance in subregions of the space. An evaluation on six prediction tasks, ranging from detecting deception to differentiating impressionist artists, demonstrated that aggregating crowd features improves upon both asking the crowd for a direct prediction and off-the-shelf machine learning features by over 10%. Further, hybrid systems that use both crowd-nominated and machine-extracted features can outperform those that use either in isolation.
Let’s see, suggest predictive features (subject identifiers in the non-topic map technical sense) and label data (identify instances of a subject), sounds a lot easier that some of the tedium I have seen for authoring a topic map.
I particularly like the “inducing” of features versus relying on a crowd to suggest identifying features. I suspect that would work well in a topic map authoring context, sans the machine learning aspects.
This paper is being presented this week, CSCW 2015, so you aren’t too far behind. 😉
How would you structure an inducement mechanism for authoring a topic map?
Comments Off on Flock: Hybrid Crowd-Machine Learning Classifiers
Major tech companies like Apple and Microsoft have been able to provide millions of people with personal digital assistants on mobile devices, allowing people to do things like set alarms or get answers to questions simply by speaking. Now, other companies can implement their own versions, using new open-source software called Sirius — an allusion, of course, to Apple’s Siri.
Today researchers from the University of Michigan are giving presentations on Sirius at the International Conference on Architectural Support for Programming Languages and Operating Systems in Turkey. Meanwhile, Sirius also made an appearance on Product Hunt this morning.
“Sirius … implements the core functionalities of an IPA (intelligent personal assistant) such as speech recognition, image matching, natural language processing and a question-and-answer system,” the researchers wrote in a new academic paper documenting their work. The system accepts questions and commands from a mobile device, processes information on servers, and provides audible responses on the mobile device.
Opens up the possibility of a IPA (intelligent personal assistant) that has custom intelligence. Are your day-to-day tasks Apple cookie-cutter tasks or do they go beyond that?
The security implications are interesting as well. What if your IPA “reads” on a news stream that you have been arrested? Or if you fail to check in within some time window?
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
The technique described appears very promising but I suspect the paper’s importance lies in another discovery by its authors:
Many insects have a larval form that is optimized for extracting energy and nutrients from the environment and a completely different adult form that is optimized for the very different requirements of traveling and reproduction. In large-scale machine learning, we typically use very similar models for the training stage and the deployment stage despite their very different requirements: For tasks like speech and object recognition, training must extract structure from very large, highly redundant datasets but it does not need to operate in real time and it can use a huge amount of computation. Deployment to a large number of users, however, has much more stringent requirements on latency and computational resources. The analogy with insects suggests that we should be willing to train very cumbersome models if that makes it easier to extract structure from the data.
The sparse results of machine learning haven’t been due to the difficulty of machine learning but by our limited conceptions of it.
Consider the recent rush of papers and promising results with deep learning. Compare that to years of labor spent on trying to specify rules and logic for machine reasoning. The verdict isn’t in, yet, but I suspect that formal logic is too sparse and pinched to support robust machine reasoning.
Like the Google’s Pinball Wizard with Atari games, so long as it wins, does its method matter? What if it isn’t expressible in first order logic?
It will be very ironic after the years of debate over “logical” entities if computers must become less logical and more like us in order to advance machine reasoning projects.
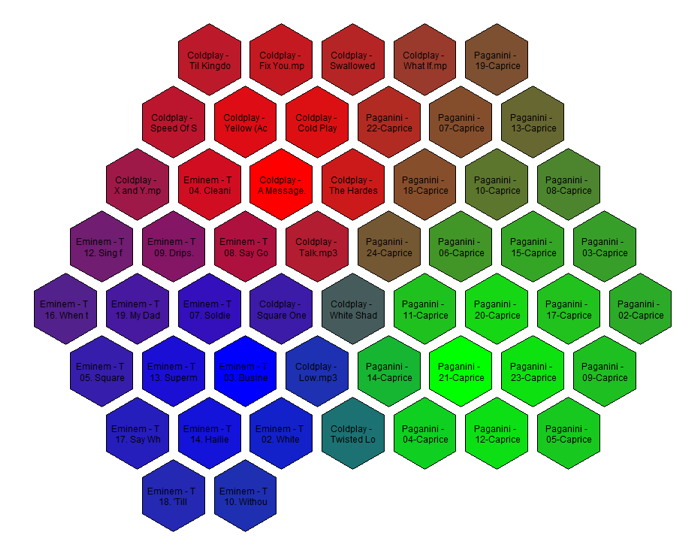
In this article we’ll explore a neat way of visualizing your MP3 music collection. The end result will be a hexagonal map of all your songs, with similar sounding tracks located next to each other. The color of different regions corresponds to different genres of music (e.g. classical, hip hop, hard rock). As an example, here’s a map of three albums from my music collection: Paganini’s Violin Caprices, Eminem’s The Eminem Show, and Coldplay’s X&Y.
To make things more interesting (and in some cases simpler), I imposed some constraints. First, the solution should not rely on any pre-existing ID3 tags (e.g. Arist, Genre) in the MP3 files—only the statistical properties of the sound should be used to calculate the similarity of songs. A lot of my MP3 files are poorly tagged anyways, and I wanted to keep the solution applicable to any music collection no matter how bad its metadata. Second, no other external information should be used to create the visualization—the only required inputs are the user’s set of MP3 files. It is possible to improve the quality of the solution by leveraging a large database of songs which have already been tagged with a specific genre, but for simplicity I wanted to keep this solution completely standalone. And lastly, although digital music comes in many formats (MP3, WMA, M4A, OGG, etc.) to keep things simple I just focused on MP3 files. The algorithm developed here should work fine for any other format as long as it can be extracted into a WAV file.
Creating the music map is an interesting exercise. It involves audio processing, machine learning, and visualization techniques.
…
It would take longer than a weekend to complete this project with a sizable music collection but it would be a great deal of fun!
Great way to become familiar with several Python libraries.
BTW, when I saw Coldplay, I thought of Coal Chamber by mistake. Not exactly the same subject. 😉
Today I’m excited to announce the general availability of Spark 1.3! Spark 1.3 introduces the widely anticipated DataFrame API, an evolution of Spark’s RDD abstraction designed to make crunching large datasets simple and fast. Spark 1.3 also boasts a large number of improvements across the stack, from Streaming, to ML, to SQL. The release has been posted today on the Apache Spark website.
We’ll be publishing in depth overview posts covering Spark’s new features over the coming weeks. Some of the salient features of this release are:
A new DataFrame API
… Spark SQL Graduates from Alpha
… Built-in Support for Spark Packages
… Lower Level Kafka Support in Spark Streaming
… New Algorithms in MLlib
Microsoft Azure Machine Learning contains many powerful machine learning and data manipulation modules. The powerful R language has been described as the lingua franca of analytics. Happily, analytics and data manipulation in Azure Machine Learning can be extended by using R. This combination provides the scalability and ease of deployment of Azure Machine Learning with the flexibility and deep analytics of R.
…
This document will help you quickly start extending Azure Machine Learning by using the R language. This guide contains the information you will need to create, test and execute R code within Azure Machine Learning. As you work though this quick start guide, you will create a complete forecasting solution by using the R language in Azure Machine Learning.
…
BTW, I deleted an ad in the middle of the pasted text that said you can try Azure learning free. No credit card required. Check the site for details because terms can and do change.
I don’t know who suggested “quick” be in the title but it wasn’t anyone who read the post. 😉
Seriously, despite being long it is a great onboarding to using RStudio with Azure Machine Learning that ends with lots of good R resources.
Combining the strength of cloud based machine learning with a language that is standard in data science is a winning combination.
People will differ in their preferences for cloud based machine learning environments but this guide sets a high mark for guides concerning the same.
PredictionIO is an open-source Machine Learning server for developers and data scientists to build and deploy predictive applications in a fraction of the time.
PredictionIO template gallery offers a wide range of predictive engine templates for download, developers can customize them easily. The DASE architecture of engine is the “MVC for Machine Learning”. It enables developers to build predictive engine components with separation-of-concerns. Data scientists can also swap and evaluate algorithms as they wish. The core part of PredictionIO is an engine deployment platform built on top of Apache Spark. Predictive engines are deployed as distributed web services. In addition, there is an Event Server. It is a scalable data collection and analytics layer built on top of Apache HBase.
PredictionIO eliminates the friction between software development, data science and production deployment. It takes care of the data infrastructure routine so that your data science team can focus on what matters most.
You may want to remember that the current state of cyberinsecurity, where all programs are suspect and security software may add more bugs that it cures, is a result, in part, of shipping code because “it works,” and not because it is free (or relatively so) of security issues.
I am really not looking forward to machine learning uncertainty like we have cyberinsecurity now.
That isn’t a reflection on PredictionIO but the thought occurred to me because of the emphasis on accelerated use of machine learning.
Comments Off on PredictionIO [ML Too Easy? Too Fast?]
Apologies for having missed this announcement. Perhaps the title lacked urgency? 😉
From the post:
The National Institutes of Health (NIH) has issued a call for participation in a Request for Information (RFI), allowing the public to share its thoughts with the NIH Advisory Committee to the NIH Director Working Group charged with helping to chart the course of the National Library of Medicine, the world’s largest biomedical library and a component of the NIH, in preparation for recruitment of a successor to Dr. Donald A.B. Lindberg, who will retire as NLM Director at the end of March 2015.
As part of the working group’s deliberations, NIH is seeking input from stakeholders and the general public through an RFI.
Information Requested
The RFI seeks input regarding the strategic vision for the NLM to ensure that it remains an international leader in biomedical data and health information. In particular, comments are being sought regarding the current value of and future need for NLM programs, resources, research and training efforts and services (e.g., databases, software, collections). Your comments can include but are not limited to the following topics:
Current NLM elements that are of the most, or least, value to the research community (including biomedical, clinical, behavioral, health services, public health and historical researchers) and future capabilities that will be needed to support evolving scientific and technological activities and needs.
Current NLM elements that are of the most, or least, value to health professionals (e.g., those working in health care, emergency response, toxicology, environmental health and public health) and future capabilities that will be needed to enable health professionals to integrate data and knowledge from biomedical research into effective practice.
Current NLM elements that are of most, or least, value to patients and the public (including students, teachers and the media) and future capabilities that will be needed to ensure a trusted source for rapid dissemination of health knowledge into the public domain.
Current NLM elements that are of most, or least, value to other libraries, publishers, organizations, companies and individuals who use NLM data, software tools and systems in developing and providing value-added or complementary services and products and future capabilities that would facilitate the development of products and services that make use of NLM resources.
How NLM could be better positioned to help address the broader and growing challenges associated with:
Biomedical informatics, “big data” and data science;
Electronic health records;
Digital publications; or
Other emerging challenges/elements warranting special consideration.
If I manage to put something together, I will post it here as well as to the NIH.
Experiences with big data and machine learning, for all of the hype, have been falling short of the promised land. Not that I think topic maps/subject identity can get you there but certainly closer than wandering in the woods of dark data.
Comments Off on NIH RFI on National Library of Medicine
When I first heard about a lie detector as a child, I was puzzled. How could a machine detect lies? If it could, why couldn’t you use it to predict the future? For example, you could say “IBM stock will go up tomorrow” and let the machine tell you whether you’re lying.
Of course lie detectors can’t tell whether someone is lying. They can only tell whether someone is exhibiting physiological behavior believed to be associated with lying. How well the latter predicts the former is a matter of debate.
I saw a presentation of a machine learning package the other day. Some of the questions implied that the audience had a magical understanding of machine learning, as if an algorithm could extract answers from data that do not contain the answer. The software simply searches for patterns in data by seeing how well various possible patterns fit, but there may be no pattern to be found. Machine learning algorithms cannot generate information that isn’t there any more than a polygraph machine can predict the future.
I supplied the alternative title because of the advocacy of “big data” as a necessity for all enterprises, with no knowledge at all of the data being collected or of the issues for a particular enterprise that it might address. Machine learning suffers from the same affliction.
Specific case studies don’t answer the question of whether machine learning and/or big data is a fit for your enterprise or its particular problems. Some problems are quite common but incompetency in management is the most prevalent of all (Dilbert) and neither big data nor machine learning than help with that problem.
Take John’s caution to heart for both machine learning and big data. You will be glad you did!
Comments Off on Machine learning and magic [ Or, Big Data and magic]
For this exercise, we’ll be training a simple classifier that learns how to categorize bills from the California Legislature based only on their titles. Along the way, we’ll focus on three steps critical to any supervised learning application: feature engineering, model building and evaluation.
To help us out, we’ll be using a Python library called http://scikit-learn.org/, which is the easiest to understand machine learning library I’ve seen in any language.
That’s a lot to pack in, so this session is going to move fast, and I’m going to assume you have a strong working knowledge of Python. Don’t get caught up in the syntax. It’s more important to understand the process.
Since we only have time to hit the very basics, I’ve also included some additional points you might find useful under the “What we’re not covering” heading of each section below. There are also some resources at the bottom of this document that I hope will be helpful if you decide to learn more about this on your own.
A great starting place for journalists or anyone else who wants to understand basic machine learning.
Support Vector Machines (SVM) are very useful and popular in data classification, regression and outlier detection. This advanced supervised machine learning algorithm can quickly become very complex and hard to understand, but can lead to great results. In the example we train a linear SVM to detect and predict who’s the writer of a tweet.
Nice weekend type project, Python, iPython notebook, 400 tweets (I think Leon is right, the sample is too small), but an opportunity to “arm up the switches and dial in the mils.”
Enjoy!
While you are there, you should look around Leon’s blog. A number of interesting posts on statistics using Python.
Comments Off on Linear SVM Classifier on Twitter User Recognition
A new online Chinese riddle game is steeped in more than just tradition. In fact, the machine learning and artificial intelligence that fuels it derives from years of research that also helps drive Bing Search, Bing Translator, the Translator App for Windows Phone, and other products.
Launched in celebration of the Chinese New Year, Microsoft Chinese Character Riddle is based on the two-player game unique to Chinese traditional culture and part of the Chinese Lantern Festival. Developed by the Natural Language Computing Group in the Microsoft Research's Beijing lab, the game not only quickly returns an answer to a user's riddle, but also works in reverse: when a user enters a single Chinese character as the intended answer, the system generates several riddles from which to choose.
"These innovations typically embody the strategic thought of Natural Language Processing 2.0, which is to collect big data on the Internet, to automatically build AI models using statistical machine learning methods, and to involve users in the innovation process by quickly getting their on-line feedback." Says Dr. Ming Zhou, Group Leader for Natural Language Computing Group and Principal Researcher at Microsoft Research Asia. "Thus the riddle system will continue to improve."
…
I don’t know any Chinese characters at all so others will need to judge the usefulness of this machine learning version. I did find a general resource on Riddles about Chinese Characters.
What other word or riddle games would pose challenges for machine learning?
The dataset from the ATLAS Higgs Machine Learning Challenge has been released on the CERN Open Data Portal.
The Challenge, which ran from May to September 2014, was to develop an algorithm that improved the detection of the Higgs boson signal. The specific sample used simulated Higgs particles into two tau particles inside the ATLAS detector. The downloadable sample was provided for participants at the host platform on Kaggle’s website. With almost 1,785 teams competing, the event was a huge success. Participants applied and developed cutting edge Machine Learning techniques, which have been shown to be better than existing traditional high-energy physics tools.
The dataset was removed at the end of the Challenge but due to high public demand ATLAS, as organizer of the event, has decided to house it in the CERN Open Data Portal where it will be available permanently. The 60MB zipped ASCII file can be decoded without a special software, and a few scripts are provided to help users get started. Detailed documentation for physicists and data scientists is also available. Thanks to the Digital Object Identifiers (DOIs) in CERN Open Data Portal, the dataset and accompanying material can be cited like any other paper.
If you missed your chance to test your mettle in the ATLAS’ Higgs ML Challenge, don’t despair! The data is available once again. How have ML techniques changed since the original challenge? How have your skills improved?
Enjoy!
Comments Off on ATLAS’ Higgs ML Challenge Data Open to Public
SmileMiner (Statistical Machine Intelligence and Learning Engine) is a pure Java library of various state-of-art machine learning algorithms. SmileMiner is self contained and requires only Java standard library.
SmileMiner is well documented and you can browse the javadoc for more information. A basic tutorial is avilable on the project wiki.
To see SmileMiner in action, please download the demo jar file and then run java -jar smile-demo.jar.
Classification: Support Vector Machines, Decision Trees, AdaBoost, Gradient Boosting, Random Forest, Logistic Regression, Neural Networks, RBF Networks, Maximum Entropy Classifier, KNN, Naïve Bayesian, Fisher/Linear/Quadratic/Regularized Discriminant Analysis.
Regression: Support Vector Regression, Gaussian Process, Regression Trees, Gradient Boosting, Random Forest, RBF Networks, OLS, LASSO, Ridge Regression.
Feature Selection: Genetic Algorithm based Feature Selection, Ensemble Learning based Feature Selection, Signal Noise ratio, Sum Squares ratio.
Great to have another machine learning library but it reminded me of a question I read yesterday:
When two teams of data scientists report conflicting results, how does a manager choose between them?
There is a view, says Florian Zettelmeyer, the Nancy L. Ertle Professor of Marketing, that data science represents disembodied truth.
Zettelmeyer, himself a data scientist, fervently disagrees with that view.
“Data science fundamentally speaks to management decisions” he said, “and management decisions are fundamentally political. There are agendas and there are winners and losers. As a result, different teams will often come up with different conclusions and it is the job of a manager to be able to call it. This requires a ‘working knowledge of data science.’”
I’m not so sure that a “working knowledge of data science” is required to choose between different answers in data science. A knowledge of what their superiors are likely to accept is a more likely criteria.
A good machine learning library should give you enough options to approximate the expected answer.
With the general availability of Azure Machine Learning, Microsoft released a collection of eighteen new videos which accurately summarize what the product does and how to use it. Most of the videos are short, and some of the material overlaps: I don’t have a recommended order, but you could play the shorter ones first. In all cases, you can download a copy of each video for your own library or offline use.
Eighteen new videos of varying lengths, the shortest and longest are:
Believe it or not, it is possible to say something meaningful in 35 seconds. Not a lot but enough to suggest an experiment based on information from a previous module.
For those of you on the MS side of the house or anyone who likes a range of employment options.
Enjoy!
Comments Off on Azure Machine Learning Videos: February 2015
There are a number of deeplearningpackagesoutthere. However most sacrifice readability for efficiency. This has two disadvantages: (1) It is difficult for a beginner student to understand what the code is doing, which is a shame because sometimes the code can be a lot simpler than the underlying math. (2) Every other day new ideas come out for optimization, regularization, etc. If the package used already has the trick implemented, great. But if not, it is difficult for a researcher to test the new idea using impenetrable code with a steep learning curve. So I started writing KUnet.jl which currently implements backprop with basic units like relu, standard loss functions like softmax, dropout for generalization, L1-L2 regularization, and optimization using SGD, momentum, ADAGRAD, Nesterov’s accelerated gradient etc. in less than 500 lines of Julia code. Its speed is competitive with the fastest GPU packages (here is a benchmark). For installation and usage information, please refer to the GitHub repo. The remainder of this post will present (a slightly cleaned up version of) the code as a beginner’s neural network tutorial (modeled after Honnibal’s excellent parsing example).
…
In the data science course that I instruct, we cover most of the data science pipeline but focus especially on machine learning. Besides teaching model evaluation procedures and metrics, we obviously teach the algorithms themselves, primarily for supervised learning.
Near the end of this 11-week course, we spend a few hours reviewing the material that has been covered throughout the course, with the hope that students will start to construct mental connections between all of the different things they have learned. One of the skills that I want students to be able to take away from this course is the ability to intelligently choose between supervised learning algorithms when working a machine learning problem. Although there is some value in the “brute force” approach (try everything and see what works best), there is a lot more value in being able to understand the trade-offs you’re making when choosing one algorithm over another.
I decided to create a game for the students, in which I gave them a blank table listing the supervised learning algorithms we covered and asked them to compare the algorithms across a dozen different dimensions. I couldn’t find a table like this on the Internet, so I decided to construct one myself! Here’s what I came up with:
…
Eight (8) algorithms compared across a dozen (12) dimensions.
What algorithms would you add? Comments to add or take away?
Looks like the start of a very useful community resource.
Comments Off on Comparing supervised learning algorithms
MILJS is a collection of state-of-the-art, platform-independent, scalable, fast JavaScript libraries for matrix calculation and machine learning. Our core library offering a matrix calculation is called Sushi, which exhibits far better performance than any other leading machine learning libraries written in JavaScript. Especially, our matrix multiplication is 177 times faster than the fastest JavaScript benchmark. Based on Sushi, a machine learning library called Tempura is provided, which supports various algorithms widely used in machine learning research. We also provide Soba as a visualization library. The implementations of our libraries are clearly written, properly documented and thus can are easy to get started with, as long as there is a web browser. These libraries are available from this http URL under the MIT license.
Where “this http URL” = http://mil-tokyo.github.io/. It’s a hyperlink with that text in the original so I didn’t want to change the surface text.
The paper is a brief introduction to the JavaScript Libraries and ends with several short demos.