Why can’t we hate men? by Suzanna Danuta Walters (Washington Post, June 8, 2018), has gotten a surprising number of comments that have little, if any, relationship to what she wrote.
What follows is a reading that other white males may or may not find persuasive.
Open up the Walters’ text and align it with this post in your browser. All set?
Paragraph 1: “It’s not that Eric Schneiderman …” Using “edge” imagery, the author establishes the position in this post, isn’t a new one. It’s one of long and mature consideration.
Paragraph 2: “Seen in this indisputably true context,…” Walters confesses hating all men is a tempting proposition. One she herself has struggled with.
Paragraph 3: “But, of course, the criticisms of this blanket condemnation of men…” Despite the temptation to hate all men, Walters recognizes the proper target is: “…male power as institutional, not narrowly personal or individual or biologically based in male bodies.”
Anyone who claims Walters says “hate all men,” hasn’t read up to and including the third paragraph of her essay.
Paragraph 4: “But this recognition of the complexity of male domination…” A transition to reciting universal facts about women. Facts which are true, despite “…the complexity of male domination.”
Paragraph 5 and 6: “Pretty much everywhere in the world, this is true: Women experience sexual violence, and the threat of that violence permeates our choices big and small.” Does anyone dispute these facts about the lives of women? (If you do, you can stop reading here. What follows will make little sense to you.)
Paragraph 7: “So, in this moment, here in the land of legislatively legitimated toxic masculinity, is it really so illogical to hate men?” Returning to “hating all men,” Walters says despite widespread reporting of male abuse of women, she isn’t seeing significant change. (I don’t see it either. Do you?) Women being abused by men and men taking few steps to stop that abuse, adds up to a pretty logical reason to hate all men. (Walters does not make that call here or elsewhere.)
Paragraph 8: “The world has little place for feminist anger…” You don’t grab female co-workers by the genitals, don’t extort sexual favors, aren’t an incel troll. Feminists are angry over your lack of effort to create a better environment for women.
To put that in another context, not being a slaver isn’t the same thing as opposing slavery. A majority of the families where slavery was legal, were passive beneficiaries of slavery:
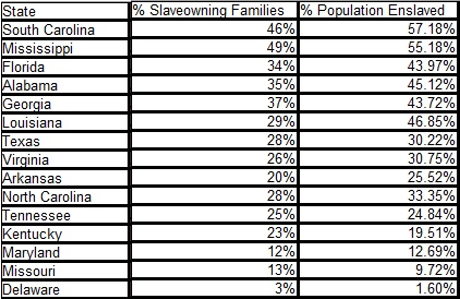
(edited to remove date of secession but otherwise the same as found at: The Extent of Slave Ownership in the United States in 1860.)
The state with the lowest number of passive beneficiaries of slavery was Mississippi, with passive beneficiaries representing 51% of the population.
Compare that with the number of passive beneficiaries of patriarchy:
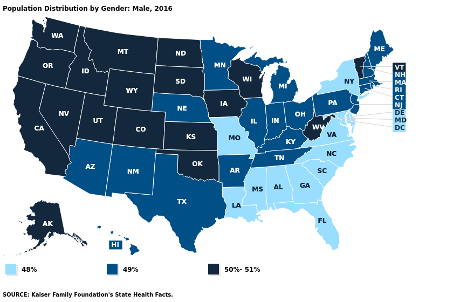
There is no state with less than 48% of its population as passive beneficiaries of patriarchy.
There are men in those populations who are actively campaigning on behalf of women. But if you’re not one of them, then feminists have a right to be angry in general and angry with you in particular.
Paragraph 9: “So men, if you really are #WithUs and would like us to not hate you for all the millennia of woe you have produced and benefited from, start with this:” Walters never says “hate all men.”
There are factual and logical reasons why women could hate all men, but Walters turns aside from the sterility of hate to suggest ways men can make the lives of women different. Different in a positive way.
I read Walters as saying action-less sympathy for women, while enjoying the benefits of patriarchy, is adding insult on top of injury.
Helping to create a different life experience for women requires more than doing no harm. Are you ready to spend your time, resources and energy doing good for women? Ask, respectfully, women in your life what they see as important, read feminist literature and forums, listen before speaking. Spread the word about feminism even when women and/or feminists aren’t present. A better world for women is a better world for us all.