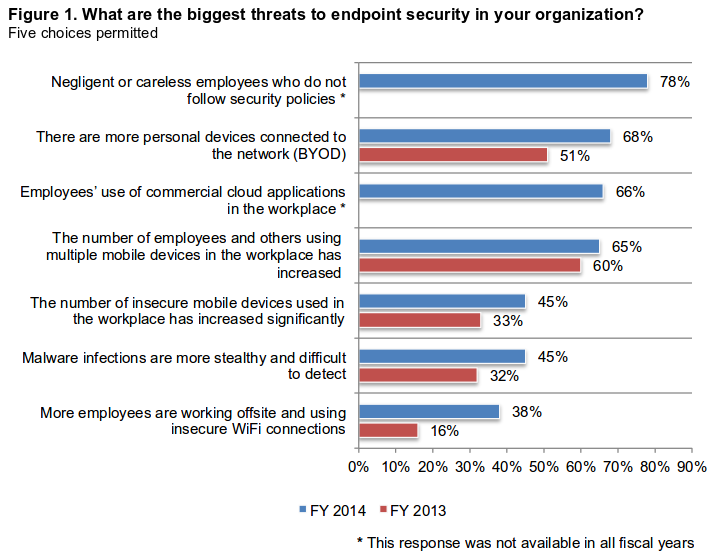
How To Encrypt Your USB Drive to Protect Data by Mohit Kumar.
From the post:
The USB flash drives or memory sticks are an excellent way to store and carry data and applications for access on any system you come across. With storage spaces already reaching 256 gigabytes, nowadays USB drives are often larger than past’s hard drives.
Thanks to increased storage capacity and low prices, you can easily store all your personal data on a tiny, easy-to-carry, USB memory stick.
The USB drive is a device that is used by almost everyone today. However, there’s a downside…
I think you’ll agree with me when I say:
USB sticks are easily lost or stolen.
Aren’t they?
However, in today’s post I am going to show you how to use your USB drives without fear of being misplaced.
If you are not aware, the leading cause of data breaches for the past few years has been the loss or theft of laptops and USB storage devices.
However, USB flash memory sticks are generally treated with far less care than laptops, and criminals seeking for corporate devices could cost your company a million dollars loss by stealing just a $12 USB drive.
By throwing light on the threats of USB drives, I’m not saying that you should never use a USB memory drives. Rather…
…I’ll introduce you a way to use your tiny data storage devices securely.
Losing USB flash drives wouldn’t be so concerning if the criminals were not granted immediate access to sensitive data stored in it.
Instead of relying merely on passwords, it’s essential for businesses to safeguard their data by encrypting the device.
…
Mohit gives great introduction to cryptsetup and its use with an Ubuntu system.
Except for one thing…in the image of creating a password, I only count seventeen (17) obscured characters. And there is no advice on how long your password/passphrase needs to be.
You may remember that the Office of Personnel Management had privileged users with passwords shorter than their own documented minimum (near the end of the post). Bad Joss!
The FAQ on cryptsetup has great advice that I will summarize and then you can read the details if you are interested.
Summary:
Ordinary:
Plain dm-crypt: Use > 80 bit. That is e.g. 17 random chars from a-z or a random English sentence of > 135 characters length.
LUKS: Use > 65 bit. That is e.g. 14 random chars from a-z or a random English sentence of > 108 characters length.
Paranoid:
Plain dm-crypt: Use > 100 bit. That is e.g. 21 random chars from a-z or a random English sentence of > 167 characters length.
LUKS: Use > 85 bit. That is e.g. 18 random chars from a-z or a random English sentence of > 140 characters length.
BTW, you were going to tell me about your minimum of eight (8) characters for a password? Feel as secure as before you started reading this post?
The fuller explanation from the cryptsetup FAQ:
5.1 How long is a secure passphrase ?
This is just the short answer. For more info and explanation
of some of the terms used in this item, read the rest of
Section 5. The actual recommendation is at the end of this item.
First, passphrase length is not really the right measure,
passphrase entropy is. For example, a random lowercase letter (a-z)
gives you 4.7 bit of entropy, one element of a-z0-9 gives you 5.2
bits of entropy, an element of a-zA-Z0-9 gives you 5.9 bits
and a-zA-Z0-9!@#$%^&:-+ gives you 6.2 bits. On the other hand,
a random English word only gives you 0.6…1.3 bits of entropy
per character. Using sentences that make sense gives lower
entropy, series of random words gives higher entropy. Do not
use sentences that can be tied to you or found on your computer.
This type of attack is done routinely today.
That said, it does not matter too much what scheme you use,
but it does matter how much entropy your passphrase contains, because
an attacker has to try on average
1/2 * 2^(bits of entropy in passphrase)
different passphrases to guess correctly.
Historically, estimations tended to use computing time estimates,
but more modern approaches try to estimate cost of guessing a passphrase.
As an example, I will try to get an estimate from
the numbers in http://it.slashdot.org/story/12/12/05/0623215/new-25-gpu-monster-devours-strong-passwords-in-minutes
More references can be found a the end of this document. Note that
these are estimates from the defender side, so assuming something
is easier than it actually is is fine. An attacker may still
have vastly higher cost than estimated here.
LUKS uses SHA1 for hashing per default. The claim in the reference is
63 billion tries/second for SHA1. We will leave aside the check
whether a try actually decrypts a key-slot. Now, the machine has
25 GPUs, which I will estimate at an overall lifetime cost of
USD/EUR 1000 each, and an useful lifetime of 2 years. (This is on
the low side.) Disregarding downtime, the machine can then
break
N = 63*10^9 * 3600 * 24 * 365 * 2 ~ 4*10^18
passphrases for EUR/USD 25k. That is one 62 bit passphrase hashed once
with SHA1 for EUR/USD 25k. Note that as this can be parallelized, it
can be done faster than 2 years with several of these machines.
For plain dm-crypt (no hash iteration) this is it. This gives (with SHA1,
plain dm-crypt default is ripemd160
which seems to be slightly slower than SHA1):
Passphrase entropy Cost to break
60 bit EUR/USD 6k
65 bit EUR/USD 200K
70 bit EUR/USD 6M
75 bit EUR/USD 200M
80 bit EUR/USD 6B
85 bit EUR/USD 200B
... ...
For LUKS, you have to take into account hash iteration in PBKDF2.
For a current CPU, there are about 100k iterations (as can be queried
with ”cryptsetup luksDump”.
The table above then becomes:
Passphrase entropy Cost to break
50 bit EUR/USD 600k
55 bit EUR/USD 20M
60 bit EUR/USD 600M
65 bit EUR/USD 20B
70 bit EUR/USD 600B
75 bit EUR/USD 20T
... ...
Recommendation:
To get reasonable security for the next 10 years, it is a good idea
to overestimate by a factor of at least 1000.
Then there is the question of how much the attacker is willing
to spend. That is up to your own security evaluation.
For general use, I will assume the attacker is willing to
spend up to 1 million EUR/USD. Then we get the following
recommendations:
Plain dm-crypt: Use > 80 bit. That is e.g. 17 random chars from a-z or
a random English sentence of > 135 characters length.
LUKS: Use > 65 bit. That is e.g. 14 random chars from a-z or
a random English sentence of > 108 characters length.
If paranoid, add at least 20 bit. That is roughly four additional
characters for random passphrases and roughly 32 characters for
a random English sentence.
The FAQ was edited about a month ago (as of June 17, 2015) so it should be relatively up to date. However, advances in attacks on encryption can occur without warning so use this information at your own risk. I do appreciate the FAQ answering what seems like a question that most people elide over.
PS: There are organizations that love to find encrypted USB drives in their facilities. Think of it as digital littering.
Or you can pick an encrypted USB drive with a > 100 bit key from a punch bowl at a USB drive swapping party to carry on your person and truthfully report that you don’t know the key, nor who does.
Enjoy!