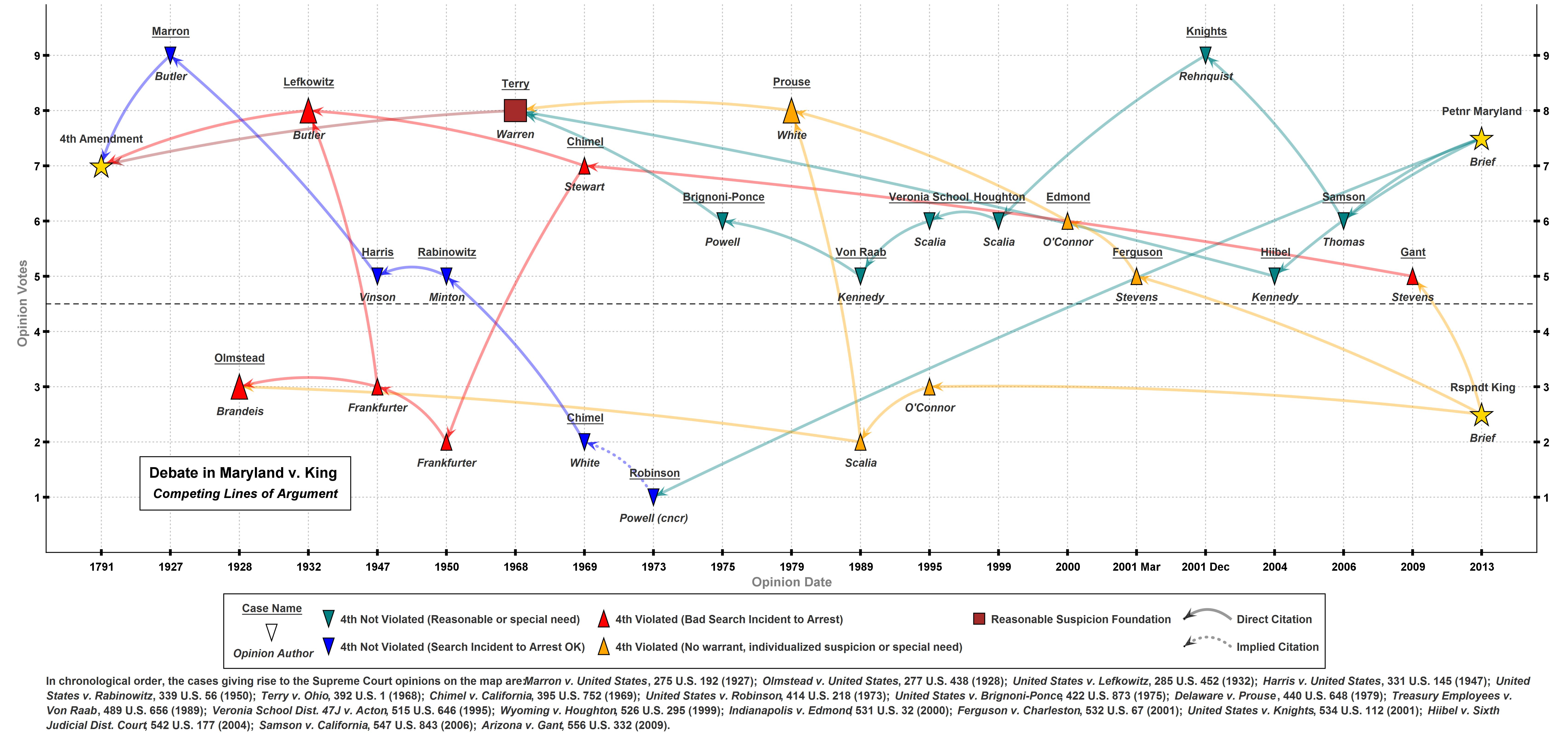
Law Classification Added to Library of Congress Linked Data Service by Kevin Ford.
From the post:
The Library of Congress is pleased to make the K Class – Law Classification – and all its subclasses available as linked data from the LC Linked Data Service, ID.LOC.GOV. K Class joins the B, N, M, and Z Classes, which have been in beta release since June 2012. With about 2.2 million new resources added to ID.LOC.GOV, K Class is nearly eight times larger than the B, M, N, and Z Classes combined. It is four times larger than the Library of Congress Subject Headings (LCSH). If it is not the largest class, it is second only to the P Class (Literature) in the Library of Congress Classification (LCC) system.
We have also taken the opportunity to re-compute and reload the B, M, N, and Z classes in response to a few reported errors. Our gratitude to Caroline Arms for her work crawling through B, M, N, and Z and identifying a number of these issues.
Please explore the K Class for yourself at http://id.loc.gov/authorities/classification/K or all of the classes at http://id.loc.gov/authorities/classification.
The classification section of ID.LOC.GOV remains a beta offering. More work is needed not only to add the additional classes to the system but also to continue to work out issues with the data.
As always, your feedback is important and welcomed. Your contributions directly inform service enhancements. We are interested in all forms of constructive commentary on all topics related to ID. But we are particularly interested in how the data available from ID.LOC.GOV is used and continue to encourage the submission of use cases describing how the community would like to apply or repurpose the LCC data.
You can send comments or report any problems via the ID feedback form or ID listserv.
Not leisure reading for everyone but if you are interested, this is fascinating source material.
And an important source of information for potential associations between subjects.
I first saw this at: Ford: Law Classification Added to Library of Congress Linked Data Service.