You’ll Never Guess Where This FBI Agent Left a Secret Interrogation Manual by Nick Baumann.
From the post:
In a lapse that national security experts call baffling, a high-ranking FBI agent filed a sensitive internal manual detailing the bureau’s secret interrogation procedures with the Library of Congress, where anyone with a library card can read it.
For years, the American Civil Liberties Union fought a legal battle to force the FBI to release a range of documents concerning FBI guidelines, including this one, which covers the practices agents are supposed to employ when questioning suspects. Through all this, unbeknownst to the ACLU and the FBI, the manual sat in a government archive open to the public. When the FBI finally relented and provided the ACLU a version of the interrogation guidebook last year, it was heavily redacted; entire pages were blacked out. But the version available at the Library of Congress, which a Mother Jones reporter reviewed last week, contains no redactions.
The 70-plus-page manual ended up in the Library of Congress, thanks to its author, an FBI official who made an unexplainable mistake. This FBI supervisory special agent, who once worked as a unit chief in the FBI’s counterterrorism division, registered a copyright for the manual in 2010 and deposited a copy with the US Copyright Office, where members of the public can inspect it upon request. What’s particularly strange about this episode is that government documents cannot be copyrighted.
A bit further on in the story it is reported:
Because the two versions are similar, a side-by-side comparison allows a reader to deduce what was redacted in the later version. The copyright office does not allow readers to take pictures or notes, but during a brief inspection, a few redactions stood out.
See Nick’s story for the redactions but what puzzled me was the “does not allow readers to take pictures or notes…” line.
Turns out what Mother Jones should have done was contact the ACLU, who is involved in litigation over this item.
Why?
Because under Circular 6 of the Copyright Office, copies of a deposit can be obtained under three (3) conditions, one of which is:
The Copyright Office Litigation Statement Form is completed and received from an attorney or authorized representative in connection with litigation, actual or prospective, involving the copyrighted work. The following information must be included in such a request: (a) the names of all parties involved and the nature of the controversy, and (b) the name of the court in which the actual case is pending. In the case of a prospective proceeding, the requestor must give a full statement of the facts of controversy in which the copyrighted work is involved, attach any letter or other document that supports the claim that litigation may be instituted, and make satisfactory assurance that the requested reproduction will be used only in connection with the specified litigation.
Contact the Records Research and Certification Section for a Litigation Statement Form. This form must be used. No substitute will be permitted. The form must contain an original signature and all information requested for the Copyright Office to process a request.
You can also get a court order but this one looks like a custom fit for the ACLU case.
It is hard to argue the government is in bad faith while ignoring routine administrative procedures to obtain the information you seek.
PS: If you have any ACLU contacts, please forward this post to them.
If you have Mother Jones contacts, suggest to them the drill is to get the information first, then break the story. They seem to have gotten that backwards on this one.


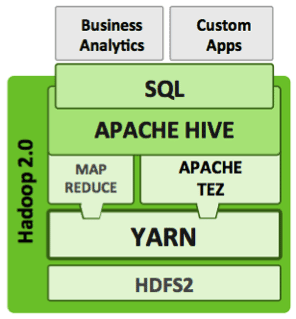 Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.
Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.