I was reading Embracing the Internet of Everything To Capture Your Share of $14.4 Trillion by Joseph Bradley, Joel Barbier, and Doug Handler, when I realized their projected Value at Stake of $14.4 trillion left out an important number. The price for an Internet of Everything.
Prices are usually calculated by the product price multiplied by the quantity of the product. Let’s start there to evaluate Cisco’s pricing.
In How Many Things Are Currently Connected To The “Internet of Things” (IoT)?, appearing in Forbes, Rob Soderberry, Cisco Executive, said that:
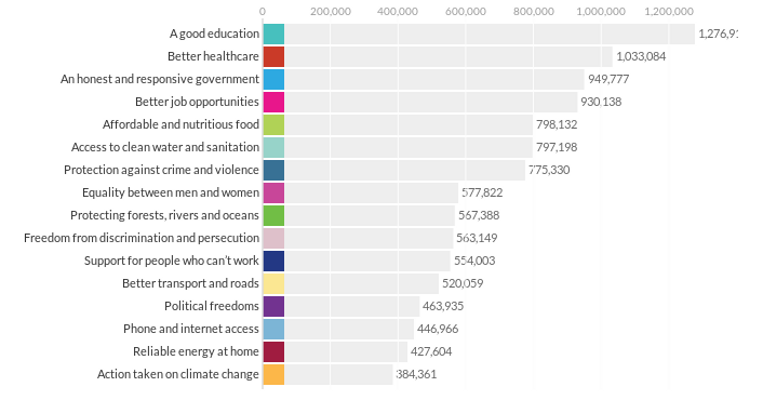
the number of connected devices reached 8.7 billion in 2012.
The Internet of Everything (IoE) paper projects 50 billion “things” being connected by 2020.
Roughly that’s 41.3 billion more connections than exist at present.
Let’s take some liberties with Cisco’s numbers. Assume the networking in each device, leaving aside the cost of a new device with networking capability, is $10. So $10 times 41.3 billion connections = $410.3 billion. The projected ROI just dropped from $14.4 trillion to $14 trillion.
Let’s further assume that Internet connectivity has radically dropped in price and so it only $10 per month. For our additional 41.3 billion devices, $10 times 41.3 billion things times 12 or $4.130 trillion per year. The projected ROI just dropped to $10 trillion.
I say the ROI “dropped,” but that’s not really true. Someone is getting paid for Internet access, the infrastructure to support it, etc. Can you spell “C-i-s-c-o?”
In terms of complexity, consider Mark Zuckerberg’s (Facebook founder) Internet.org, which is working with Ericsson, MediaTek, Nokia, Opera, Qualcomm, and Samsung:
to help bring web access to the five billion people who are not yet connected. (From: Mark Zuckerberg launches Internet.org to help bring web access to the whole world by Mark Wilson.)
A coalition of major players working on connecting 5 billion people versus Cisco’s hand waving about connecting 50 billion “things.”
That’s not a cost estimate but it does illustrate the enormity of the problem of creating the IoE.
But the cost of the proposed IoE isn’t just connecting to the Internet.
For commercial ground vehicles the Cisco report says:
As vehicles become more connected with their environment (road, signals, toll booths, other vehicles, air quality reports, inventory systems), efficiencies and safety greatly increase. For example, the driver of a vending-machine truck will be able to look at a panel on the dashboard to see exactly which locations need to be replenished. This scenario saves time and reduces costs.
Just taking roads and signals, do you know how much is spent on highway and street construction in the United States every month?
Would you believe it averages between $77 billion and 83+ billion a month? US Highway and Street Construction Spending:
82.09B USD for Nov 2013
And the current state of road infrastructures in the United States?
Forty-two percent of America’s major urban highways remain congested, costing the economy an estimated $101 billion in wasted time and fuel annually. While the conditions have improved in the near term, and Federal, state, and local capital investments increased to $91 billion annually, that level of investment is insufficient and still projected to result in a decline in conditions and performance in the long term. Currently, the Federal Highway Administration estimates that $170 billion in capital investment would be needed on an annual basis to significantly improve conditions and performance. (2013 Report Card: Roads D+. For more infrastructure reports see: 2013 Report Card )
I read that to say an estimated $170 billion is needed annually just to improve current roads. Yes?
That doesn’t include the costs of Internet infrastructure, the delivery vehicle, other vehicles, inventory systems, etc.
I am certain that however and whenever the Internet of Things comes into being, Cisco, as part of the core infrastructure now, will prosper. I can see Cisco’s ROI from the IoE.
What I don’t see is the ROI for the public or private sector, even assuming the Cisco numbers are spot on.
Why? Because there is no price tag for the infrastructure to make the IoE a reality. Someone, maybe a lot of someones, will be paying that cost.
If you encounter costs estimates sufficient for players in the public or private sectors to make their own ROI calculations, please point them out. Thanks!
PS: A future Internet more to my taste would have tagged Cisco’s article with “speculation,” “no cost data,” etc. as aids for unwary readers.
PPS: Apologies for only U.S. cost figures. Other countries will have similar issues but I am not as familiar with where to find their infrastructure data.