Pre-inauguration suppression of free speech/protests is underway for the Trump regime. (CNN link as subject identifier for Donald J. Trump, even though it fails to mention he looks like a cheeto in a suit.)
Women’s March on Washington barred from Lincoln Memorial by Amber Jamieson and Jessica Glenza.
From the post:
…
For the thousands hoping to echo the civil rights and anti-Vietnam rallies at Lincoln Memorial by joining the women’s march on Washington the day after Donald Trump’s inauguration: time to readjust your expectations.The Women’s March won’t be held at the Lincoln Memorial.
That’s because the National Park Service, on behalf of the Presidential Inauguration Committee, filed documents securing large swaths of the national mall and Pennsylvania Avenue, the Washington Monument and the Lincoln Memorial for the inauguration festivities. None of these spots will be open for protesters.
The NPS filed a “massive omnibus blocking permit” for many of Washington DC’s most famous political locations for days and weeks before and after the inauguration on 20 January, said Mara Verheyden-Hilliard, a constitutional rights litigator and the executive director of the Partnership for Civil Justice Fund.
…

I contacted Amber Jamieson for more details on the permits and she forwarded two links (thanks Amber!):
Press Conference: Mass Protests Will Go Forward During Inauguration, which had the second link she forwarded:
PresidentialInauguralCommittee12052016.pdf, the permit requests made by the National Park Service on behalf of the Presidential Inaugural Committee.
Start with where protests are “permitted” to see what has been lost.
A grim read but 36 CFR 7.96 says in part:
…
3 (i) White House area. No permit may be issued authorizing demonstrations in the White House area, except for the White House sidewalk, Lafayette Park and the Ellipse. No permit may be issued authorizing special events, except for the Ellipse, and except for annual commemorative wreath-laying ceremonies relating to the statutes in Lafayette Park.
…
(emphasis added, material hosted by the Legal Information Institute (LII))
Summary: In White House area, protesters have only three places for permits to protest:
- White House sidewalk
- Lafayette Park
- Ellipse
White House sidewalk / Lafayette Park (except North-East Quadrant) – Application 16-0289
Dates:
Set-up dates starting 11/1/2016 6:00 am ending 1/19/2017
Activity dates starting 1/20/2017 ending 1/20/2017
Break-down dates starting 1/21/2017 ending 3/1/2017 11:59 pm
Closes:
…
All of Lafayette Park except for its northeast quadrant pursuant to 36 CFR 7.96 (g)(4)(iii)(A). The initial areas of Lafayette Park and the White House Sidewalk that will be needed for construction set-up, and which will to be closed to ensure public safety, is detailed in the attached map. The attached map depicts the center portion of the White House Sidewalk as well as a portion of the southern oval of Lafayette Park. The other remaining areas in Lafayette Park and the White House Sidewalk that will be needed for construction set-up, will be closed as construction set-up progresses into these other areas, which will also then be delineated by fencing and sign age to ensure public safety.
…
Two of the three possible protest sites in the White House closed by Application 16-0289.
Ellipse – Application 17-0001
Dates:
Set-up dates starting 01/6/2017 6:00 am ending 1/19/2017
Activity dates starting 1/20/2017 ending 1/20/2017
Break-down dates starting 1/21/2017 ending 2/17/2017 11:59 pm
These dates are at variance with those for the White House sidewalk and Lafayette Park (shorter).
Closes:
Ellipse, a fitty-two acre park, as depicted by Google Maps:
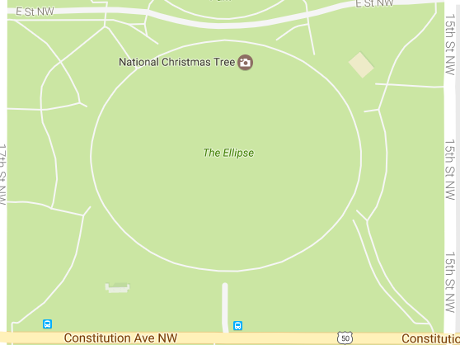
Plans for the Ellipse?
…
Purpose of Activity: In connection with the Presidential Inaugural Ceremonies, this application is for use of the Ellipse by PIC, in the event that PIC seeks its use for Inaugural ceremonies and any necessary staging, which is expected to be:A) In the event that PIC seeks the use of the Ellipse for pre- and/or post- Inaugural ceremonies, the area will be used for staging the event(s), staging of media to cover and/or broadcast the event, and if possible for ticketed and/or public viewing; and/or
B) In the event that PIC seeks the use of the Ellipse for the Inaugural ceremony and Inaugural parade staging, the area will be used to stage the various parade elements, for media to cover and/or broadcast the event, and if possible for ticketed and/or public viewing.
…
The PIC has no plans to use the Ellipse but has reserved it no doubt to deny its use to others.
Those two applications close three out of three protest sites in the White House area. The PIC went even further to reach out and close off other potential protest sites.
Other permits granted to the PIC include:
Misc. Areas – Application 16-0357
Ten (10) misc. areas identified by attached maps for PIC activities.
Arguably legitimate since the camp followers, sycophants and purveyors of “false news” need somewhere to be during the festivities.
National Mall -> Trump Mall – Application 17-0002
The National Mall will become Trump Mall for the following dates:
Set-up dates starting 01/6/2017 6:00 am ending 1/19/2017
Activity dates starting 1/20/2017 ending 1/20/2017
Break-down dates starting 1/21/2017 ending 1/30/2017 11:59 pm
Closes:
…
Plan for Proposed Activity: Consistent with NPS regulations at 36 CFR 7.96{g)(4)(iii)(C), this application seeks, in connection with the Presidential Inaugural Ceremonies, the area of the National Mall between 14th – 4th Streets, for the exclusive use of the Joint Task Force Headquarters (JTFHQ) on Inaugural Day for the assembly, staging, security and weather protection of the pre-Inaugural parade components and floats on Inaugural Day between 14th – 7th Streets. It also includes the placement of jumbotrons and sound towers by the Architect of the Capitol or the Joint Congressional Committee on Inaugural Ceremonies so that the Inaugural Ceremony may be observed by the Joint Congressional Committee’s ticketed standing room ticket holders between 4th – 3rd streets and the general public, which will be located on the National Mall between 7th – 4th Streets. Further, a 150-foot by 200-foot area on the National Mall just east of 7th Street, will be for the exclusive use of the Presidential Inaugural Committee for television and radio media broadcasts on Inaugural Day.
…
In the plans thus far, no mention of the main card or where the ring plus cage will be erected on Trump Mall. (that’s sarcasm, not “fake news”)
Most Other Places – Application 17-0003
If you read 36 CFR 7.96 carefully, you noticed there are places always prohibited to protesters:
…
(ii) Other park areas. Demonstrations and special events are not allowed in the following other park areas:(A) The Washington Monument, which means the area enclosed within the inner circle that surrounds the Monument’s base, except for the official annual commemorative Washington birthday ceremony.
(B) The Lincoln Memorial, which means that portion of the park area which is on the same level or above the base of the large marble columns surrounding the structure, and the single series of marble stairs immediately adjacent to and below that level, except for the official annual commemorative Lincoln birthday ceremony.
(C) The Jefferson Memorial, which means the circular portion of the Jefferson Memorial enclosed by the outermost series of columns, and all portions on the same levels or above the base of these columns, except for the official annual commemorative Jefferson birthday ceremony.
(D) The Vietnam Veterans Memorial, except for official annual Memorial Day and Veterans Day commemorative ceremonies.
…
What about places just outside the already restricted areas?
Dates:
Set-up dates starting 01/6/2017 6:00 am ending 1/19/2017
Activity dates starting 1/20/2017 ending 1/20/2017
Break-down dates starting 1/21/2017 ending 2/10/2017 11:59 pm
Closes:
…
The Lincoln Memorial area, as more fully detailed as the park area bordered by 23rd Street, Daniel French Drive and Independence Avenue, Henry Bacon Drive and Constitution Avenue, Constitution Avenue between 15th & 23rd Streets, Constitution Gardens to include Area #5 outside of the Vietnam Veteran’s Memorial restricted area, the Lincoln Memorial outside of its restricted area, the Lincoln Memorial Plaza and Reflecting Pool Area, JFK Hockey Field, park area west of Lincoln Memorial between French Drive, Henry Bacon Drive, Parking Lots A, Band C, East and West Potomac Park, Memorial Bridge, Memorial Circle and Memorial Drive, the World War II Memorial. The Washington Monument Grounds as more fully depicted as the park area bounded by 14th & 15th Streets and Madison Drive and Independence Avenue.
…
Not to use but to prevent its use by others:
…
Purpose of Activity: In connection with the Presidential Inaugural Ceremonies, this application is for use of the Lincoln Memorial areas and Washington Monument grounds by PIC, in the event that PIC seeks its use for the Inaugural related ceremonies and any necessary staging, which is expected to be:A) In the event that PIC seeks the use of the Lincoln Memorial areas for a pre-and/or post Inaugural ceremonies, the area will be used for staging the event(s), staging of media to cover and/or broadcast the event, and for ticketed and/or public viewing.
B) In the event that PIC seeks to use the Washington Monument grounds for a public overflow area to view the Inaugural ceremony and/ or parade, the area will be used for the public who will observe the activities through prepositioned jumbotrons and sound towers.
…
Next Steps
For your amusement, all five applications contain the following question answered No:
Do you have any reason to believe or any information indicating that any individual, group or organization might seek to disrupt the activity for which this application is submitted?
I would venture to say someone hasn’t been listening. 😉
Among the data science questions raised by this background information are:
- How best to represent these no free speech and/or no free assembly zones on a map?
- What data sets do you need to make protesters effective under these restrictions?
- What questions would you ask of those data sets?
- How to decide between viral/spontaneous action versus publicly known but lawful conduct, up until the point it becomes unlawful?
If you use any of this information, please credit Amber Jamieson, Jessica Glenza and the Partnership for Civil Justice Fund as the primary sources.
See further news from the Partnership for Civil Justice Fund at: Your Right of Resistance.
Tune in next Monday for: How To Brick A School Bus, Data Science Helps Park It.
PS: “The White House Sidewalk is the sidewalk between East and West Executive Avenues, on the south side Pennsylvania Avenue, N.W.” From OMB Control No. 1024-0021 – Application for a Permit to Conduct a Demonstration or Special Event in Park Areas and a Waiver of Numerical Limitations on Demonstrations for White House Sidewalk and/or Lafayette Park






