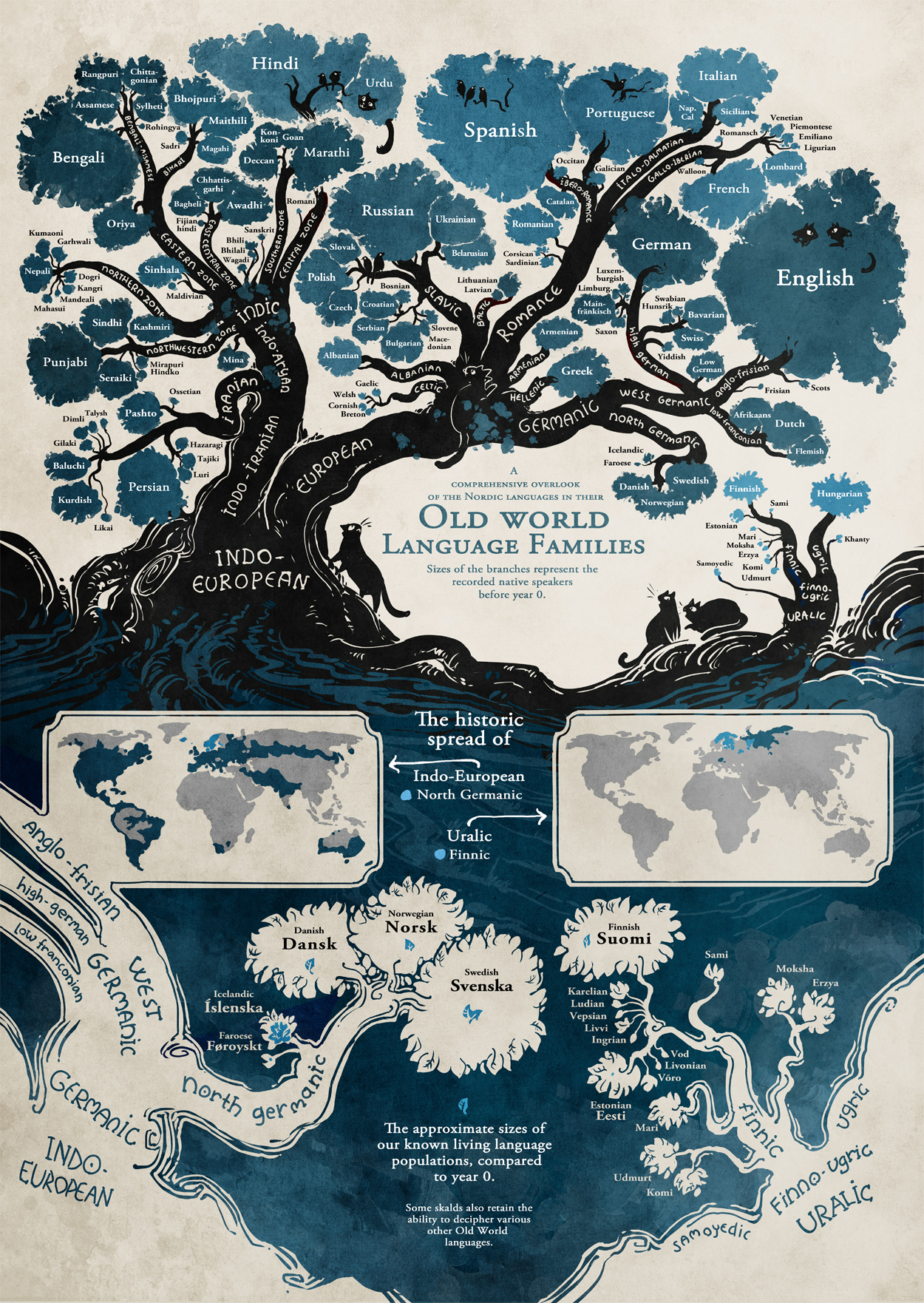
Modelling Plot: On the “conversional novel” by Andrew Piper.
From the post:
I am pleased to announce the acceptance of a new piece that will be appearing soon in New Literary History. In it, I explore techniques for identifying narratives of conversion in the modern novel in German, French and English. A great deal of new work has been circulating recently that addresses the question of plot structures within different genres and how we might or might not be able to model these computationally. My hope is that this piece offers a compelling new way of computationally studying different plot types and understanding their meaning within different genres.
Looking over recent work, in addition to Ben Schmidt’s original post examining plot “arcs” in TV shows using PCA, there have been posts by Ted Underwood and Matthew Jockers looking at novels, as well as a new piece in LLC that tries to identify plot units in fairy tales using the tools of natural language processing (frame nets and identity extraction). In this vein, my work offers an attempt to think about a single plot “type” (narrative conversion) and its role in the development of the novel over the long nineteenth century. How might we develop models that register the novel’s relationship to the narration of profound change, and how might such narratives be indicative of readerly investment? Is there something intrinsic, I have been asking myself, to the way novels ask us to commit to them? If so, does this have something to do with larger linguistic currents within them – not just a single line, passage, or character, or even something like “style” – but the way a greater shift of language over the course of the novel can be generative of affective states such as allegiance, belief or conviction? Can linguistic change, in other words, serve as an efficacious vehicle of readerly devotion?
While the full paper is available here, I wanted to post a distilled version of what I see as its primary findings. It’s a long essay that not only tries to experiment with the project of modelling plot, but also reflects on the process of model building itself and its place within critical reading practices. In many ways, its a polemic against the unfortunate binariness that surrounds debates in our field right now (distant/close, surface/depth etc.). Instead, I want us to see how computational modelling is in many ways conversional in nature, if by that we understand it as a circular process of gradually approaching some imaginary, yet never attainable centre, one that oscillates between both quantitative and qualitative stances (distant and close practices of reading).
Andrew writes of “…critical reading practices….” I’m not sure that technology will increase the use of “…critical reading practices…” but it certainly offers the opportunity to “read” texts in different ways.
I have done this with IT standards but never a novel, attempt reading it from the back forwards, a sentence at a time. At least with authoring you are proofing, it provides a radically different perspective than the more normal front to back. The first thing you notice is that it interrupts your reading/skimming speed so you will catch more errors as well as nuances in the text.
Before you think that literary analysis is a bit far afield from “practical” application, remember that narratives (think literature) are what drive social policy and decision making.
Take the current popular “war on terrorism” narrative that is so popular and unquestioned in the United States. Ask anyone inside the beltway in D.C. and they will blather on and on about the need to defend against terrorism. But there is an absolute paucity of terrorists, at least by deed, in the United States. Why does the narrative persist in the absence of any evidence to support it?
The various Red Scares in U.S. history were similar narratives that have never completely faded. They too had a radical disconnect between the narrative and the “facts on the ground.”
Piper doesn’t offer answers to those sort of questions but a deeper understanding of narrative, such as is found in novels, may lead to hints with profound policy implications.