Thousands of years of visual culture made free through Wellcome Images
From the post:
We are delighted to announce that over 100,000 high resolution images including manuscripts, paintings, etchings, early photography and advertisements are now freely available through Wellcome Images.
Drawn from our vast historical holdings, the images are being released under the Creative Commons Attribution (CC-BY) licence.
This means that they can be used for commercial or personal purposes, with an acknowledgement of the original source (Wellcome Library, London). All of the images from our historical collections can be used free of charge.
The images can be downloaded in high-resolution directly from the Wellcome Images website for users to freely copy, distribute, edit, manipulate, and build upon as you wish, for personal or commercial use. The images range from ancient medical manuscripts to etchings by artists such as Vincent Van Gogh and Francisco Goya.
The earliest item is an Egyptian prescription on papyrus, and treasures include exquisite medieval illuminated manuscripts and anatomical drawings, from delicate 16th century fugitive sheets, whose hinged paper flaps reveal hidden viscera to Paolo Mascagni’s vibrantly coloured etching of an ‘exploded’ torso.
Other treasures include a beautiful Persian horoscope for the 15th-century prince Iskandar, sharply sketched satires by Rowlandson, Gillray and Cruikshank, as well as photography from Eadweard Muybridge’s studies of motion. John Thomson’s remarkable nineteenth century portraits from his travels in China can be downloaded, as well a newly added series of photographs of hysteric and epileptic patients at the famous Salpêtrière Hospital
Semantics or should I say semantic confusion is never far away. While viewing an image of Gladstone as Scrooge:
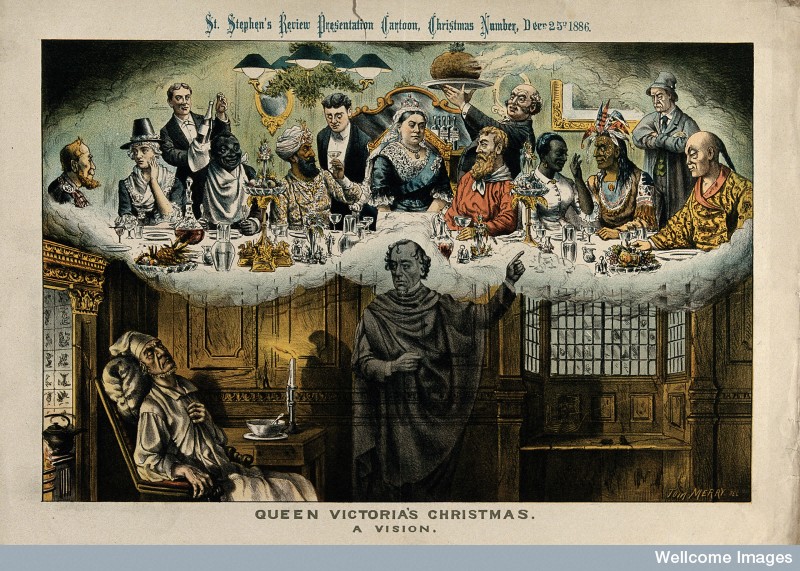
When “search by keyword” offered “colonies,” I assumed either the colonies of the UK at the time.
Imagine my surprise when among other images, Wellcome Images offered:
The search by keywords had found fourteen petri dish images, three images of Batavia, seven maps of India (salt, leporsy), one half naked woman being held down, and the Gladstone image from earlier.
About what one expects from search these days but we could do better. Much better.
I first saw this in a tweet by Neil Saunders.



")

")
")

")

")






")
-test")
")
