Mapping an audience-centric World Wide Web: A departure from hyperlink analysis by Harsh Taneja.
Abstract:
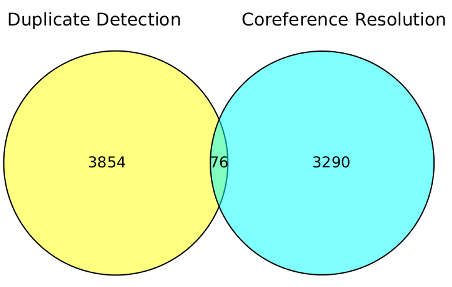
This article argues that maps of the Web’s structure based solely on technical infrastructure such as hyperlinks may bear little resemblance to maps based on Web usage, as cultural factors drive the latter to a larger extent. To test this thesis, the study constructs two network maps of 1000 globally most popular Web domains, one based on hyperlinks and the other using an “audience-centric” approach with ties based on shared audience traffic between these domains. Analyses of the two networks reveal that unlike the centralized structure of the hyperlink network with few dominant “core” Websites, the audience network is more decentralized and clustered to a larger extent along geo-linguistic lines.
Apologies but the article is behind a firewall.
A good example of what you look for determining your results. And an example of how firewalls prevent meaningful discussion of such research.
Unless you know of a site like sci-hub.io of course.
Enjoy!
PS: This is what an audience-centric web mapping looks like:
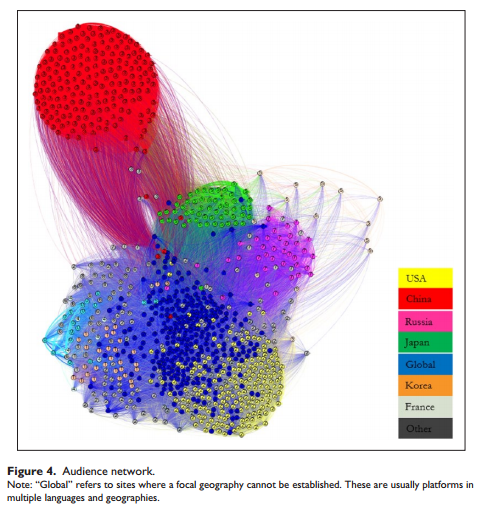
Impressive work!